
Fig. 1.
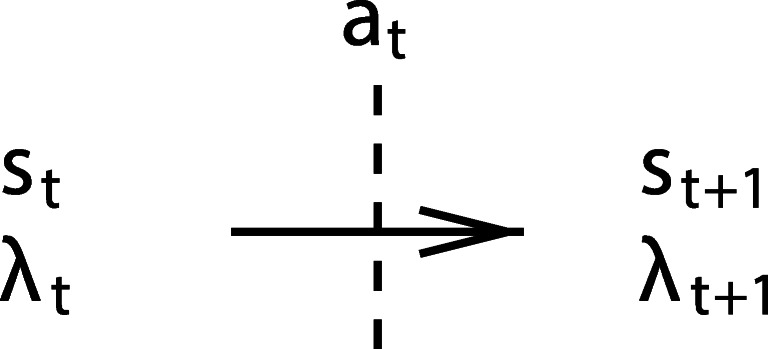
Transition from time step t to t + 1, (t = 0,1,2,…), via the agent’s decision at, where s and λ denote environment state and reward (λ0 = 0), respectively (adapted from Sutton and Barto (2018))
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
Transition from time step t to t + 1, (t = 0,1,2,…), via the agent’s decision at, where s and λ denote environment state and reward (λ0 = 0), respectively (adapted from Sutton and Barto (2018))