
Figure 4:
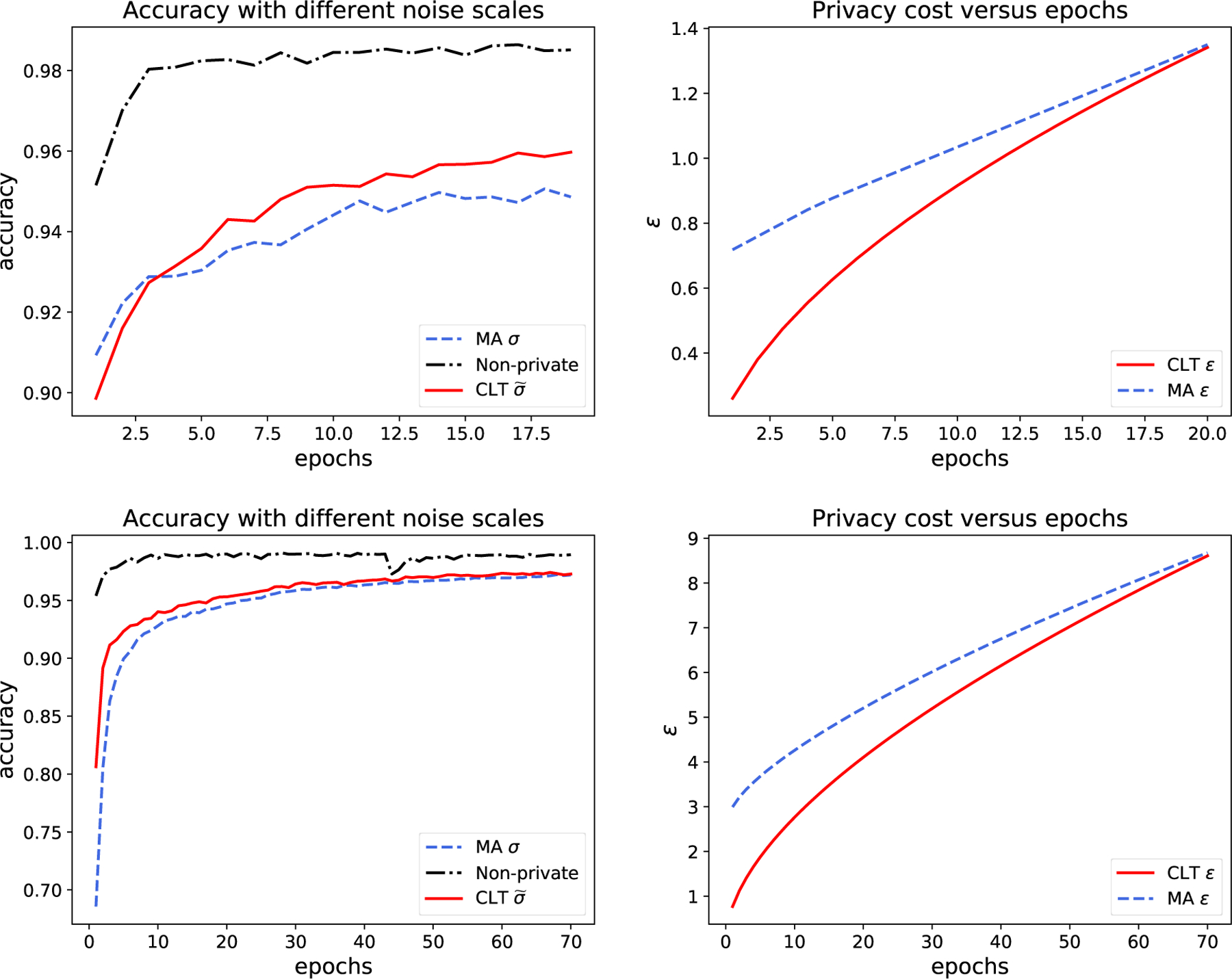
Experimental results from one run of NoisySGD on MNIST with different noise scales but the same (ε, δ)-DP guarantees. The top plots use p = 256/60000, η = 0.15, R = 1.5, and σ = 1.3, . The CLT approach with and the moments accountant with σ = 1.3 give (1.34, 10−5)-DP at the 20th epoch (μCLT = 0.35). The bottom plots use the same parameters except for σ = 0.7, , and η = 0.15. Both approaches give (8.68, 10−5)-DP at epoch 70 (μCLT = 1.78). The right plots show the privacy loss during the training process in terms of the ε spending with respect to δ = 10−5.