

Abstract
There is an abundance of RNA sequence information available due to the efforts of sequencing projects. However, current techniques implemented to solve the tertiary structures of RNA, such as NMR and X-ray crystallography, are difficult and time consuming. Therefore, biophysical techniques are not able to keep pace with the abundance of sequence information available. Because of this, there is a need to develop quick and efficient ways to predict RNA tertiary structure from sequence. One promising approach is to identify structural patterns within previously solved 3D structures and apply these patterns to new sequences. RNA tetraloops are one of the most common naturally occurring secondary structure motifs. Here, we use RNA Characterization of Secondary Structure Motifs (CoSSMos), Dissecting the Spatial Structure of RNA (DSSR), and a bioinformatic approach to search for and characterize tertiary structure patterns among tetraloops. Not surprising, we identified the well-known GNRA and UNCG tetraloops, as well as the previously identified RNYA tetraloop. However, some previously identified characteristics of these families were not observed in this dataset, and some new characteristics were identified. In addition, we also identified and characterized three new tetraloop sequence families: YGAR, UGGU, and RMSA. This new structural information sheds light on the tertiary structure of tetraloops and contributes to the efforts of RNA tertiary structure prediction from sequence.
INTRODUCTION
RNA is a versatile molecule which serves many different purposes in the cell1 and is a potential therapeutic target.2–7 RNA is typically single-stranded and can fold back on itself to form secondary structure motifs such as stems, loops, and bulges. Additional interactions of RNA secondary structures lead to a tertiary structure that is largely responsible for RNA’s biological function. While the scientific community has made great advances in the ability to quickly sequence nucleic acids, using NMR, X-ray crystallography, and cryo-EM to solve the 3D structures of individual sequences cannot keep pace with all of the interesting RNA sequences available. Therefore, there has been and continues to be a large push in the scientific community to improve prediction of RNA structure from sequence.8–12 Due to the relationship between secondary and tertiary structures, identifying tertiary structural patterns among secondary structure motifs is a promising intermediate step in RNA 3D structure prediction from sequence.
A variety of methods have been used to search for 3D structural patterns.13–24 Some methods of searching have focused on tetraloops,15, 17, 20, 25 while others have been applied in the search for many sizes and types of 3D structural patterns.13, 14, 18, 22, 23 The Znosko Lab has developed the RNA Characterization of Secondary Structure Motifs (CoSSMos) database26, 27 to allow researchers to quickly search for secondary structure motifs among 3D structures deposited in the Protein Data Bank (PDB). After identifying instances of a particular secondary structure motif using the CoSSMos website (http://rnacossmos.com), one can then begin to search for tertiary structural patterns within a motif. Davis et al. (2011) searched for structural patterns among RNA single mismatches and identified several structural patterns, although the work was manually intensive.24 To increase efficiency and produce reliable results, methods utilized to identify tertiary structural patterns among secondary structure motifs must be refined and automated.
RNA hairpin loops are the most common secondary structure motif found among naturally occurring RNAs.28–30 Hairpins of four nucleotides, or tetraloops, are the most frequently occurring hairpin loop size and are often found in rRNA and tRNA.31 Tetraloops may take part in a variety of processes such as folding of RNA structures,32 protecting mRNA from degradation,30 and participating in tertiary interactions and protein binding.33–35 Therefore, it is important to understand any sequence-structure relationships found among tetraloops to quickly assess a particular loop’s potential functionality.
One of the well-documented tertiary structural patterns in RNA is the GNRA tetraloop.36, 37 Nearly all sequence members of the GNRA family (N= any nucleotide and R= G or A) adopt the same 3D structure in which G (the first base) and A (the last base) form a sheared pair, and the N, R, and A bases form a three-base stack.36 Another notable tetraloop sequence family is UNCG,15, 38, 39 in which the U and G form a wobble pair, and the C base stacks on the U base. GNRA and UNCG tetraloops comprise over 70% of all tetraloop sequences found among rRNA.29 One other notable tetraloop family is RNYA (Y = C or U), where the R and the Y bases form a stack.40 These three sequence families have been found by many of the current methods used for finding structural patterns, and their rediscovery is sometimes used to help validate a new method,13, 17, 18, 23 as is done again here. Other tetraloop tertiary structural patterns found in smaller populations among RNA include CU(U/Y)G (Y = C or U),29, 41 GANC,42 (A/U)GNN,43, 44 UUUM (M = A or C),45, 46 and GGUG.47
In this study, a tetraloop is defined using the RNA CoSSMos 2.0 definition, a hairpin containing four nucleotides in the loop closed by at least two canonical pairs.26, 27 Note that other definitions of tetraloops exist that allow for tetraloops closed by non-canonical pairs15 or allow for base insertions and deletions;31 however, for the purpose of modeling a 3D RNA structure from sequence using 2D structures as an intermediate step, we have chosen to require four nucleotides and two canonical closing pairs for a tetraloop. Many of the previous methods for cluster analysis of 3D motifs were performed over 10 years ago or on a limited number of structures.14, 17, 18, 22, 23 A recent tetraloop analysis by D’Ascenzo et al. focused on tetraloops with an interaction between the first and last nucleotides in the hairpin loop, providing a detailed study of GNRA and UNCG tetraloops but did not extend the analysis to all tetraloops.25 Other recent analyses of 3D tetraloop motifs include only the positions and orientations of the bases without the backbone in their geometric comparisons.15, 48 One study used a nucleobase-centered, sequence-independent continuous metric distance approach.15 While several studies have noted that the closing base pair may play a role in determining the fold of a tetraloop,15, 41 no recent tetraloop analysis has created a non-redundant set of structures with unique sequences and performed sequence analysis on all of the nucleotides in the tetraloop (including closing base pairs).
The goal of this work is to develop an automated protocol to identify and characterize tertiary structural patterns among RNA tetraloop sequences to potentially discover new tetraloop sequence families using GNRA, UNCG, and RNYA as a test case. To this end, we have developed an automated protocol for searching the frequently-updated CoSSMos database for tetraloops that does not require a priori knowledge of a tetraloop. In this method, RNA tetraloops from solved structures deposited in the PDB are identified using the CoSSMos database. To eliminate sequence redundancies among the dataset, a sequence-representative structure is chosen for each unique sequence (including closing base pairs), which captures the most common structure for each sequence. The non-redundant dataset is grouped based on structural similarity of atom coordinates in the backbone and base. Sequence analysis using Biopython and structural characterization using Dissecting the Spatial Structure of RNA (DSSR)49 are performed on each group. Identification of GNRA, UNCG, and RNYA tetraloops from all tetraloop structures serves as a proof-of-concept for this protocol. Additionally, three novel sequence families (YGAR, UGGU, and RMSA) are identified and characterized.
MATERIAL AND METHODS
Assembly of structures.
The CoSSMos database was utilized to search for tetraloops in the PDB. A search was conducted on June 25, 2018 for all tetraloops found in structures solved by X-ray crystallography with a resolution ≤ 3.0 Å. This search yielded 1715 hits. Subsequently, all *.pdb files from the CoSSMos results were downloaded, and the structures of interest were “clipped” from the original *.pdb file (all atom coordinates except those of the tetraloop and first closing base pair were removed). The residue IDs were also renumbered so that the nucleotides involved in the closing base pair and tetraloop were numbered 1–6 (Figure 1). Additionally, any coordinates for H atoms were removed, since not all of the *.pdb files contained H atom coordinates. Next, the quality of the clipped and renumbered *.pdb files was checked to ensure that they fit the criteria required for subsequent analysis. Files that were missing atom coordinates or contained multiple coordinates for the same atom were identified and removed from further analysis. Of the 1715 tetraloops, 8 clipped *.pdb files did not pass the quality check (Table S1).
Figure 1.
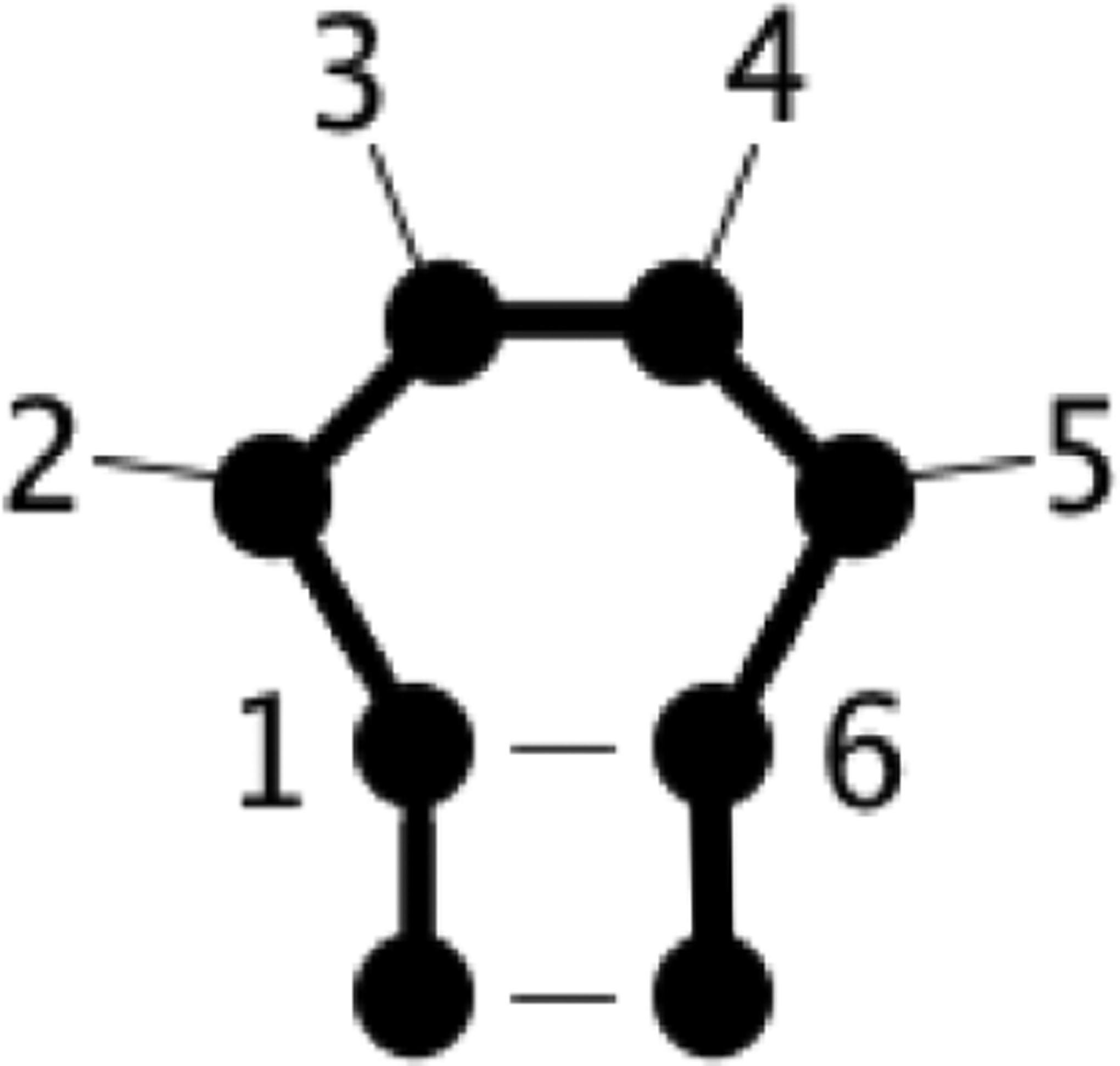
Secondary structure of a tetraloop with residues numbered. Figure was generated with XRNA.
Representative Structure Selection.
To select sequence-representative structures, the clipped *.pdb files that passed the quality check were first grouped by unique sequence only. The sequence includes the four nucleotides in the tetraloop as well as the adjacent base pair. When grouping by unique sequence, everything but the sequence (organism, location, etc) was ignored. For each unique sequence, all *.pdb files with that six-nucleotide sequence were averaged. Then, each file was compared to the average structure by calculating an all-atom RMSD, and the file that had the lowest RMSD was chosen as the sequence-representative structure for that sequence. This step yielded 74 sequence-representative tetraloop structures (Table S2).
The reason for using sequence representative structures is two-fold. First, it is one way to address sequence redundancy in the PDB (discussed below). Second, using sequence representative structures allows for the prediction of the mostly likely structural conformation from sequence, which could aid in 3D structure prediction from sequence. It has been noted previously (and seen again here) that a given sequence does not always correspond to one 3D structure.15, 25, 50 While the approach of using a sequence representative structure has its advantages, we acknowledge that we may be missing out on some structural idiosyncrasies displayed by some instances of a particular tetraloop sequence.
RMSD Comparison and Clustering.
All-against-all RMSD values were calculated for the sequence-representative structures. Since these structures have different sequences, the RMSD values were calculated using the phosphate-sugar backbone atoms and three atoms from each base (N9, C8, and C4 for purines and N1, C2, and C6 for pyrimidines) as done previously.17 A distance matrix was created with the RMSD values, and a distance tree was generated using a modified version of Biopython’s unweighted pair group method with arithmetic mean (UPGMA).51 The original source code created a tree that was not ultrametric (the tips of the tree were not all equidistant to the root of the tree) and was calculated using a weighted pair group method with arithmetic mean. The source code was modified to create ultrametric trees with unweighted averages; the modified source code is being incorporated into Biopython and is currently available upon request. For structures A and B in the tree, the branch distance was defined as half of the RMSD distance between A and B. An RMSD cutoff of 1.0 Å was assigned, and branches of the tree that fell within the corresponding branch distance cutoff were grouped together into a cluster. Sequence analysis was performed on each cluster so that a degenerate consensus sequence was assigned to each group using rules previously published.52 If the most frequent base at a particular position occurred at least 50% of the time and twice as much as the next most frequent base, it was assigned at that position. If the sum of the frequencies of two bases were at least 75% but neither met the requirements for single nucleotide assignment, then they were co-assigned at that position. If none of the bases at that position met the requirements for assignment or co-assignment, then N was assigned at that position.
Characterization and Analysis of Clusters.
Each cluster of interest was characterized by DSSR. DSSR was iterated over all sequence-representative *.pdb files present in a single cluster and over all the sequence-representative structures in the dataset. Because some of the clusters contained only two sequence-representative structures, DSSR was also iterated over all of the structures in the dataset for the newly identified clusters to determine whether interactions were present not only in the two sequence-representative structures but also the total number of structures. Information regarding base pairing, hydrogen bonding, base-base stacking, glycosidic angle, and sugar puckering for each tetraloop was isolated from the DSSR output and was compiled and tallied using a series of Python scripts to determine which specific interactions were common to the majority of tetraloops in the cluster. The data was represented by percentages; for each interaction, a percentage was calculated representing the percentage of structures in the cluster which possess the interaction.
RESULTS AND DISCUSSION
Sequence Redundancy.
A total of 74 unique sequences were found among the 1715 assembled structures. There exists disproportionate redundancy of sequences among tetraloops. For example, tetraloops with the sequence 5’-CGAAAG-3’ occurred 242 times in CoSSMos output, while tetraloops with the sequence 5’-UUGAGG-3’ only occurred 3 times. To ensure that later sequence comparison was not biased by redundant occurrences of particular tetraloop sequences, sequence-representative structures for each unique tetraloop and closing base pair sequence were selected. While this approach was able to address sequence redundancy when comparing different sequences, structure redundancy still biases the determination of the sequence representative structure. For example, the tetraloop sequence CGCAAG was found 95 times in the database, with 84 of these occurrences from rRNA. When determining the sequence representative structure, the rRNA structures dominated. Overall, using a sequence representative structure to represent all tetraloops of a given sequence worked well; the average RMSD between each tetraloop structure and the corresponding sequence representative structure was only 0.57Å. While this method does not capture every possible 3D structural pattern a sequence may form, by taking the structure closest to the average, we hoped to capture the most common 3D structural pattern formed by the unique sequence.
Unweighted Pair Group Method with Arithmetic Mean Tree.
The sequence-representative structures were clustered using UPGMA. The UPGMA cluster analysis of the tetraloops can be seen in Figure 2. Each tetraloop sequence occurs only once due to the selection of sequence-representative structures for each unique sequence.
Figure 2.

UPGMA cluster analysis of the tetraloops. The tetraloops included in the clusters are colored according to the legend. Each tetraloop is named by the PDB ID of the structure in which it appears followed by the tetraloop sequence (including closing base pairs), the chain ID, and the residue ID of the first nucleotide in the loop (after the 5’ closing nucleotide). Each tetraloop sequence occurs only once due to the selection of sequence-representative structures for each unique sequence. The distance scale at the bottom left of the tree is in Å. The tree was generated with Archaeopteryx 0.9901 beta.53
Tetraloop Clusters.
The cluster analysis resulted in six clusters (Figure 2). Of the 74 total sequence-representative structures, 46 structures were divided among the six clusters. The 28 structures that were not grouped into any cluster were not within 1.0 Å of any other structure in the UPGMA tree.
Sequence Analysis.
Each cluster was named by its degenerate sequence (Table S3). While we have chosen to name clusters based on degenerate sequence, it should be noted that other have used different approaches. For example, Bottaro and Lindorff-Larsen (2017) have used a more descriptive name of the tetraloop structure, such as 4-stack fold and U-turn fold.15 The largest cluster, NGNRAG, corresponds to the GNRA tetraloops and contains 29 unique sequences. The next largest clusters, SUWCGS (S = G or C and W = A or U) and GAUNAC, contain six and five unique sequences, respectively. The SUWCGS and GAUNAC clusters correspond to UNCG and RNYA tetraloops, respectively. Three additional clusters were identified: UYGARG (Y = U or C and R = G or A), KUGGUM (K = G or U and M = A or C), and YRMSAR (S = G or C). These three sequence families, to our knowledge, have not been previously identified in the literature. A list of the sequences comprising each cluster is shown in Table 1.
Table 1.
Sequences comprising the clusters.
| GAUNAC Cluster N = Any Base |
NGNRAG Cluster N = Any Base and R = A or G |
||
| Unique Sequence (5’ to 3’) | Sequence-Representative Structurea | Unique Sequence (5’ to 3’) | Sequence-Representative Structurea |
| GAUUAC | 1AQ4_R9 | CGCAAG | 1N32_A898 |
| GAUCAC | 1ZDH_R9 | CGCGAG | 1QVG_’0’577 |
| GAUAAC | 2C50_R9 | UGAAAA | 1VQM_’0’1327 |
| GAUGAC | 2C51_S9 | CGAAGG | 1XMQ_A727 |
| CAACAG | 7MSF_S6 | GGCAAC | 1XMQ_A1266 |
| CGGGAG | 1YI2 ’0’2249 | ||
| K = G or U and M = A or C | GGUGAC | 2NZ4_P109 | |
| Unique Sequence (5’ to 3’) | Sequence-Representative Structurea | UGAGAG | 2VQF_A297 |
| GUGGUC | 3ADB_D16 | GGCGAC | 2Z74_B114 |
| UUGGUA | 3AM1B_19 | AGCAAU | 2ZJR_X2832 |
| CGUAGG | 2ZZM B47.A | ||
| S = G or C and W = A or U | CGAGUG | 3ADC_C47.E | |
| Unique Sequence (5’ to 3’) | Sequence-Representative Structurea | CUCACG | 3CC2_’0’253 |
| CUACGG | 2UUB_A1446 | UGUGAA | 3CCU_’0’469 |
| GUTJCGC | 4E8Q_A339 | CGAAAG | 3MXH_R32 |
| CUCCGG | 4QVI_B2144 | CGUGAG | 3OW2_’0’2630 |
| GAUCGC | 5OB3_A31 | CCAAAG | 3PDR_A69 |
| CUUCGG | 5Y87_B29 | UTJAGCG | 3RG5_A47D |
| AUUUGU | 6CK5_A28 | CUAACG | 3T1Y_A840 |
| AAAAAU | 4AOB_A50 | ||
| Y = C or U and R = A or G | UGAAAG | 4FNJ_A17 | |
| Unique Sequence (5’ to 3’) | Sequence-Representative Structurea | GGAGAC | 4L81_A58 |
| UCGAAG | 3CC4_’0’920 | GGUAAC | 4WFL_A82 |
| UUGAGG | 5DM6_X827 | AGAAAU | 5B2S_A33 |
| CGCAGG | 5DM6_Y89 | ||
| Y = C or U, R = A or G, M = A or C, and S = G or C | UGCAAG | 5DM6_X1874 | |
| Unique Sequence (5’ to 3’) | Sequence-Representative Structurea | AGUGAU | 5F9F_F11 |
| CGAGAG | 1YHQ_’0’2738 | GGAAAC | 5FK4_A74 |
| UACCAA | 5DM7_X2681 | CGUAAG | 299D_B31L |
The PDB ID followed by the chain and residue ID of the first nucleotide in the loop
The sequence analysis of all tetraloop clusters can be seen in Table S4, and the base positions assigned to a tetraloop can be seen in Figure 1. When using the degenerate sequence, it is important to keep in mind the rules used to determine the degenerate sequence (see Materials and Methods). For example, the first G in the loop of the NGNRAG cluster does not indicate that only G nucleotides were found in that position in those structures. As seen in Table S4, all four bases actually occur at that position; however, a G occurs at that position in 83% of the structures.
Average and Representative Structures.
To aid visualization, a cluster-representative structure was selected for each cluster by calculating an average structure for each cluster and then calculating the RMSD of each member of the cluster to the average structure. The member that had the lowest RMSD from the average structure was chosen as the cluster-representative structure for that cluster (Figure 3).
Figure 3.
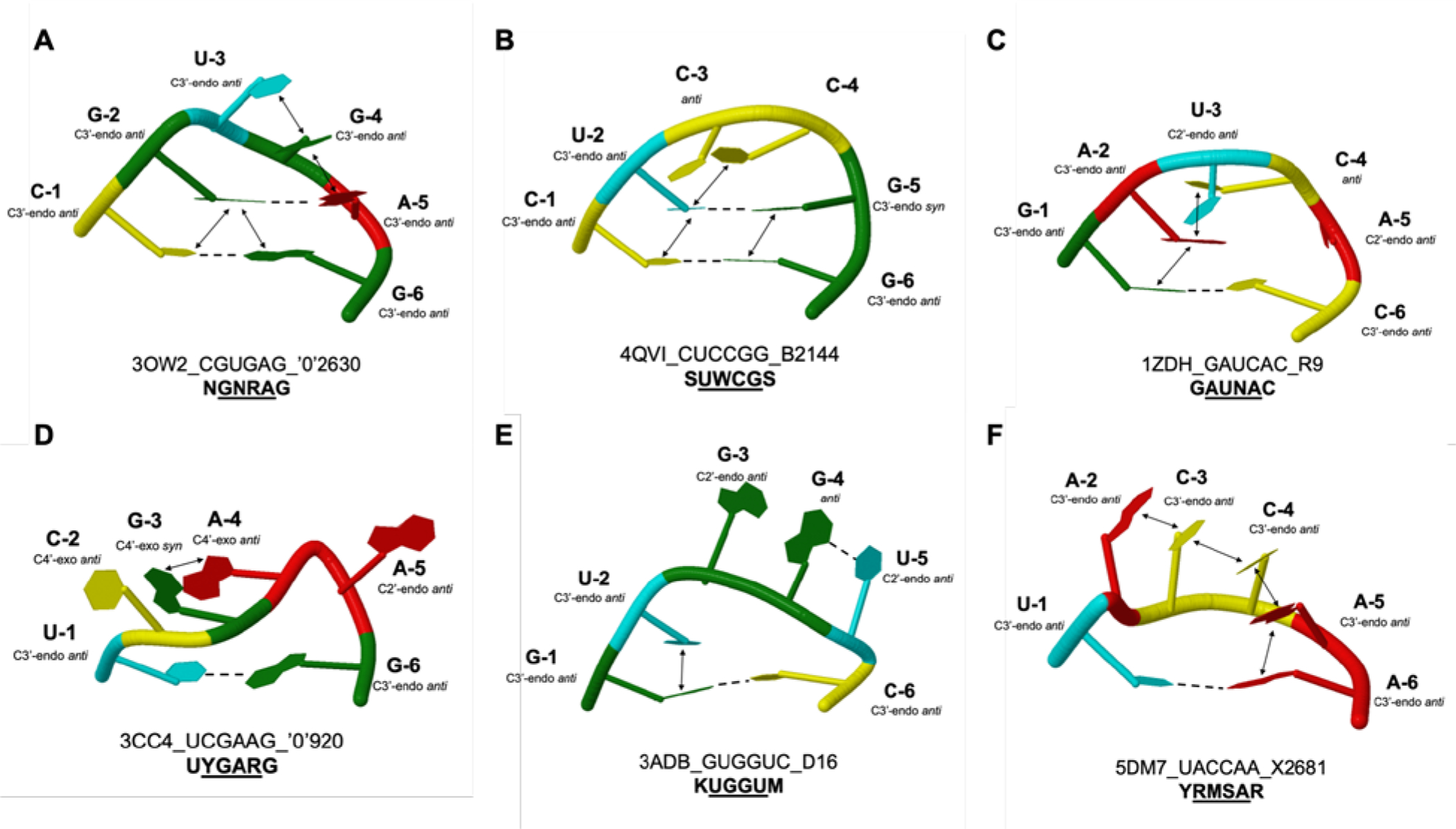
Cluster representative structures for each of the six clusters (A-F). The sugar conformations, base pairing, and stacking interactions found in ≥ 75% of sequence representative structures (and those shown in blue text in Tables 5–7) are drawn. Base pairing and stacking interactions are represented with dashed lines and arrows, respectively. Cartoon representations were created using DSSR-Jmol.49 Cluster-representative structures are named with the PDB ID, sequence, and the first residue involved in the loop. Clusters are named with the degenerate sequence shown in bold font.
Characterization of known tetraloop sequence families.
The NGNRAG, SUWCGS, and GAUNAC clusters were characterized by DSSR and analyzed by a series of Python scripts to determine the interactions common to each sequence-representative structure in the cluster. In order to determine the validity of our protocol, these interactions were compared to interactions identified in the literature to be common to the GNRA,15, 31, 36, 54, 55 UNCG,15, 38, 39 and RNYA15, 19 sequence families (Tables 2, 3, and 4, respectively).
Table 2.
NGNRAG cluster analysis (Figure 3A), corresponding to the well-known GNRA tetraloop family.
| Interactions from literature found in ≥75% of structures in the database15, 31, 36, 54, 55 | Percentage of NGNRAG sequence-representative structures with interaction (n = 29)a, b | Percentage of all other tetraloop sequence-representative structures with interaction |
|---|---|---|
| All nucleotides have an anti glycosidic angle | nt 1 – 100% anti | nt 1 – 100% anti |
| nt 2 – 100% anti | nt 2 – 98% anti | |
| nt 3 – 100% anti | nt 3 – 88% anti | |
| nt 4 – 100% anti | nt 4 – 88% anti | |
| nt 5 – 100% anti | nt 5 – 79% anti | |
| nt 6 – 100% anti | nt 6 – 100% anti | |
| Base pairing between nt 1 and nt 6 | 100% | 98% |
| Base pairing between nt 2 and nt 5 | 100% | 29% |
| Hydrogen bond between N2 of nt 2 and N7 of nt 5 | 79% | 5% |
| All nucleotides have a majority of C3’-endo sugar pucker conformation | nt 1 – 97% C3’-endo | |
| nt 2 – 97% C3’-endo | nt 1 – 95% C3’-endo | |
| nt 3 – 93% C3’-endo | nt 2 – 71% C3’-endo | |
| nt 4 – 93% C3’-endo | nt 3 – 33% C3’-endo | |
| nt 5 – 93% C3’-endo | nt 4 – 36% C3’-endo | |
| nt 6 – 90% C3’-endo | nt 5 – 41% C3’-endo | |
| nt 6 – 93% C3’-endo | ||
| Stacking between nt 3 and nt 4 | 100% | 31% |
| Stacking between nt 4 and nt 5 | 97% | 29% |
| Hydrogen bond between O2’ (hydroxyl) of nt 2 and N7 of nt 4 | 86% | 2% |
| Hydrogen bond between N2 of nt 2 and OP2 of nt 5 | 83% | 5% |
| Interactions from literature not found in ≥75% of structures in the database | ||
| Hydrogen bond between N3 of nt 2 and N6 of nt 5 | 10% | 5% |
| Stacking between nt 2 and nt 6 | 69% | 17% |
| New interactions identified | ||
| Stacking between nt 1 and nt 2 | 90% | 67% |
n = number of sequence-representative structures in this cluster.
Red values indicate interactions that are found among ≥75% of sequence-representative structures in this cluster and <75% of structures among all other tetraloops.
Table 3.
SUWCGS cluster analysis (Figure 3B), corresponding to the well-known UNCG tetraloop family.
| Interactions from literature found in ≥75% of structures in the database15, 38, 39 | Percentage of SUWCGS sequence-representative structures with interaction (n = 6)a, b | Percentage of all other tetraloop sequence-representative structures with interaction |
|---|---|---|
| nt 1, nt 2, nt 3, and nt 6 have an anti glycosidic angle; nt 5 has a syn glycosidic angle | nt 1 – 100% anti | nt 1 – 100% anti |
| nt 2 – 100% anti | nt 2 – 99% anti | |
| nt 3 – 83% anti | nt 3 – 94% anti | |
| nt 5 – 83% syn | nt 5 – 3% syn | |
| nt 6 – 100% anti | nt 6 – 100% anti | |
| Base pairing between nt 1 and nt 6 | 100% | 99% |
| Base pairing between nt 2 and nt 5 | 100% | 54% |
| Hydrogen bond between O2’ (hydroxyl) of nt 2 and O6 (carbonyl) of nt 5 | 100% | 0% |
| Hydrogen bond between O2 (carbonyl) of nt 2 and N1 of nt 5 | 100% | 2% |
| nt 1, nt 2, nt 5, and nt 6 have a C3’-endo sugar pucker conformation | nt 1 – 83% C3’-endo | nt 1 – 97% C3’-endo |
| nt 2 – 83% C3’-endo | nt 2 – 82% C3’-endo | |
| nt 5 – 83% C3’-endo | nt 5 – 60% C3’-endo | |
| nt 6 – 100% C3’-endo | nt 6 – 91% C3’-endo | |
| Stacking between nt 2 and nt 4 | 100% | 12% |
| Interactions from literature not found in ≥75% of structures in the database | ||
| nt 4 has an anti glycosidic angle | nt 4 – 67% anti | nt 4 – 95% anti |
| Hydrogen bond between OP2 of nt 3 and N4 of nt 4 | 67% | 5% |
| Hydrogen bond between O2’ (hydroxyl) of nt 3 and N7 of nt 5 | 17% | 2% |
| Hydrogen bond between O2’ (hydroxyl) of nt 3 and O6 of nt 5 | 33% | 0% |
| Hydrogen bond between O2 (carbonyl) of nt 2 and N2 of nt 5 | 17% | 0% |
| nt 3 and nt 4 have C2’-endo sugar pucker conformation | nt 3 – 50% C2’-endo | nt 3 – 31% C2’-endo |
| nt 4 – 67% C2’-endo | nt 4 – 22% C2’-endo | |
| New interactions identified | ||
| Stacking between nt 1 and nt 2 | 100% | 74% |
| Stacking between nt 5 and nt 6 | 100% | 32% |
n = number of sequence-representative structures in this cluster.
Red values indicate interactions that are found among ≥75% of sequence-representative structures in this cluster and <75% of structures among all other tetraloops.
Table 4.
GAUNAC cluster analysis (Figure 3C), corresponding to the previously identified RNYA tetraloop family.
| Interactions from literature found in ≥75% of structures in the database15, 19 | Percentage of GAUNAC sequence-representative structures with interaction (n = 5)a, b | Percentage of all other tetraloop sequence-representative structures with interaction |
|---|---|---|
| Stacking between nt 2 and nt 4 | 100% | 14% |
| Base pairing between nt 1 and nt 6 | 100% | 100% |
| New interactions identified | ||
| All nts have an anti glycosidic angle | nt 1 – 100% anti | nt 1 – 100% anti |
| nt 2 – 100% anti | nt 2 – 99% anti | |
| nt 3 – 100% anti | nt 3 – 92% anti | |
| nt 4 – 100% anti | nt 4 – 92% anti | |
| nt 5 – 100% anti | nt 5 – 86% anti | |
| nt 6 – 100% anti | nt 6 – 100% anti | |
| nt 1, nt 2, and nt 6 have C3’-endo sugar pucker conformation; nt 3 and nt 5 have C2’-endo sugar pucker conformation | nt 1 – 100% C3’-endo | nt 1 – 96% C3’-endo |
| nt 2 – 100% C3’-endo | nt 2 – 80% C3’-endo | |
| nt 3 – 80% C2’-endo | nt 3 – 29% C2’-endo | |
| nt 5 – 80% C2’-endo | nt 5 – 24% C2’-endo | |
| nt 6 – 100% C3’-endo | nt 6 – 91% C3’-endo | |
| Stacking between nt 1 and nt 2 | 100% | 74% |
n = number of sequence-representative structures in this cluster.
Red values indicate interactions that are found among ≥75% of sequence-representative structures in this cluster and <75% of structures among all other tetraloops.
As GNRA is the most commonly occurring tetraloop sequence family, it was important that the protocol that was developed was not only able to identify a cluster corresponding to GNRA but was also able to identify the structural features previously identified for GNRA tetraloops. GNRA tetraloops are known to exhibit a sheared pair between nt 2 and nt 5 and a three-base stack between nt 3, nt 4, and nt 5 (Fig. 1).15, 19, 36, 38 These same features were identified among the majority of structures in the NGNRAG cluster (Table 2). An interaction was considered to be present in the majority of the structures of each cluster if that interaction was identified in ≥75% of the sequence-representative structures of a particular cluster. DSSR was run on all of the sequence-representative structures in the dataset, excluding the sequence-representative structures in the working cluster. This analysis was compared to the output for each cluster. It can be seen in Table 2 that there are many structural features present in the majority of sequence-representative structures in the NGNRAG sequence family that are not present in the majority of all other sequence-representative structures, indicated by red text in Table 2. This shows that there are interactions within the NGNRAG cluster that distinguish this sequence family from all other tetraloops.
It should also be noted that there were two characteristic interactions identified in the literature to be common to the GNRA sequence family that were present among some sequence-representative structures within the NGNRAG cluster but with values <75%. These interactions include stacking between nt 2 and nt 6 and a hydrogen bond between N3 of nt 2 and N6 of nt 5.15, 31, 36, 54, 55 In a previous tetraloop analysis, Huang and co-workers discovered that many tetraloops that adopted the signature GNRA fold were lacking some or all of the characteristic hydrogen bonding interactions due to the variability of bases present at each position.17 In our dataset, there was only one characteristic hydrogen bonding interaction that was not present, a hydrogen bond between N3 of nt 2 and N6 of nt 5. Due to the nucleobases that occur at these positions, 8 of the 29 unique sequences in this cluster are incapable of forming this hydrogen bond, leaving 72% of the unique sequences. But, this hydrogen bond was only found in 10% of the sequence representative structures, suggesting that this hydrogen bond is not a characteristic hydrogen bond of our GNRA cluster.
In addition to identifying interactions common to GNRA tetraloops as identified by the literature, one interaction common to the majority of sequence-representative structures that was not previously mentioned in the literature was also identified, stacking between nt 1 and nt 2.
It should be noted that not all tetraloops with a GNRA sequence are found in the NGNRAG cluster and that the NGNRAG cluster contains non-GNRA sequences. This has been seen previously and discussed extensively in similar studies.15
The SUWCGS cluster which corresponds to the second-most common tetraloop fold, UNCG, was also identified and characterized. Interactions referenced in the literature common to tetraloops adopting the UNCG fold, including a syn glycosidic conformation in nt 5, a base pair between nt 2 and nt 5, and stacking between nt 2 and nt 4, were identified among the majority of structures in the SUWCGS cluster (Table 3).15, 38, 39 As with the NGNRAG cluster, there are several interactions present in the majority of sequence-representative structures in the SUWCGS cluster that are not present in the majority of all other tetraloop sequence-representative structures, thereby distinguishing the SUWCGS sequence family from all other tetraloops (Table 3, red text).
Additionally, there were characteristic interactions common to the UNCG sequence family identified in the literature that were present among some structures within the SUWCGS cluster but with values <75%. These interactions include hydrogen bonds between O2 of nt 2 and N2 of nt 5, between O2’ of nt 3 and O6 of nt 5, between O2’ of nt 3 and N7 of nt 5, and between OP2 of nt 3 and N4 of nt 4; an anti glycosidic conformation in nt 4; and a C2’-endo sugar pucker conformation in nt 3 and nt 415, 38, 39 (Table 3).
Two interactions not previously discussed in the literature were identified in the SUWCGS cluster. These include stacking interactions between nt 1 and nt 2 and between nt 5 and nt 6.
The GAUNAC cluster, corresponding to the previously identified RNYA sequence family, was also identified and characterized. The stacking interaction between nt 2 and nt 4 referenced in the literature to be common to RNYA tetraloops was identified among the majority of structures in the GAUNAC cluster (Table 4).15, 19 Four interactions not previously identified in the RNYA sequence family were identified among the majority of structures in the GAUNAC cluster. These interactions include anti glycosidic conformation in all nucleotides; C3’-endo sugar puckering in nt 1, nt 2, and nt 6; C2’-endo sugar puckering in nt 3 and nt 5; and stacking between nt 1 and nt 2. Like the previous two clusters, there are several interactions present in the majority of sequence-representative structures in the GAUNAC cluster that are not present in the majority of all other tetraloop sequence-representative structures, thereby distinguishing the GAUNAC sequence family from all other tetraloops (Table 4, red text).
The re-discovery of the GNRA, UNCG, and RNYA sequence families provides a proof-of-concept that the developed protocol used to cluster and characterize tetraloops is successful. While many of the interactions common to GNRA, UNCG, and RNYA tetraloops in the literature were re-discovered by the protocol, there were also interactions that the literature considers to be common to these sequence families that were found in <75% of structures in the NGNRAG and SUWCGS clusters. Although these clusters have already been identified, our analysis further defines these clusters; we were able to identify features not mentioned previously by the literature for these folds. These new interactions identified by our protocol provide information to further characterize existing tetraloop sequence families to better understand their tertiary structural features.
Characterization of newly identified tetraloop sequence families.
Three novel tetraloop clusters, UYGARG, KUGGUM, and YRMSAR, were identified from among all tetraloops, and the structural features of each cluster were characterized by DSSR. To our knowledge, none of these sequence families have been previously identified or characterized. Here, we describe the notable interactions present in the majority (≥75%) of structures in each of these novel clusters.
The first new cluster is UYGARG. Hairpins in this sequence family are represented in this database by 59 3D structures of rRNA. This cluster consists of two unique sequences: UCGAAG and UUGAGG. The sequence representative structure for UCGAAG is the co-crystal structure of anisomycin bound to the 50S ribosomal subunit of Haloarcula marismortui (PDB ID 3CC4). In this structure, the tetraloop may be stabilized by tertiary interactions with another hairpin in the RNA. The sequence representative structure for UUGAGG is the crystal structure of the 50S ribosomal subunit from Deinococcus radiodurans (PDB ID 5DM6). Also in this structure, the tetraloop may be stabilized by tertiary interactions with another hairpin in the RNA.
The interactions common to the UYGARG fold include an anti glycosidic conformation in nt 1, nt 2, nt 4, nt 5, and nt 6; base pairing between nt 1 and nt 6; and C3’-endo sugar pucker conformations in nt 1 and nt 6 (Fig. 3D and Table 5). In addition to these interactions, the interactions that distinguish the UYGARG cluster from all other tetraloop sequence-representative structures include a hydrogen bond between O2’ of nt 3 and O4’ of nt 4; C4’-exo sugar pucker conformation in nt 2; and a C2’-endo sugar pucker conformation in nt 5 (Fig. 3D and Table 5, red text).
Table 5.
UYGARG cluster analysis (Figure 3D).
| Interaction | Percentage of UYGARG sequence-representative structures with interaction (n = 2)a, b, c | Percentage of all UYGARG structures in cluster with interaction (x = 59)d | Percentage of all other tetraloop sequence-representative structures with interaction |
|---|---|---|---|
| nt 1, nt 2, nt 4, nt 5, and nt 6 have an anti glycosidic angle; nt 3 has a syn glycosidic angle | nt 1 – 100% anti | nt 1 – 100% anti | nt 1 – 100% anti |
| nt 2 – 100% anti | nt 2 – 100% anti | nt 2 – 99% anti | |
| nt 3 – 50% syn | nt 3 – 97% syn | nt 3 – 3% syn | |
| nt 4 – 100% anti | nt 4 – 100% anti | nt 4 – 93% anti | |
| nt 5 – 100% anti | nt 5 – 100% anti | nt 5 – 87% anti | |
| nt 6 – 100% anti | nt 6 – 100% anti | nt 6 – 100% anti | |
| Base pairing between nt 1 and nt 6 | 100% | 100% | 99% |
| Hydrogen bond between O2’ (hydroxyl) of nt 3 and O4’ of nt 4 | 100% | 100% | 0% |
| nt 1, and nt 6 have C3’-endo sugar pucker; nt 2, nt 3, and nt 4 have C4’-exo sugar pucker; nt 5 has C2’-endo sugar pucker | nt 1 – 100% C3’-endo | nt 1 – 100% C3’-endo | nt 1 – 96% C3’-endo |
| nt 2 – 100% C4’-exo | nt 2 – 97% C4’-exo | nt 2 – 4% C4’-exo | |
| nt 3 – 50% C4’-exo | nt 3 – 97% C4’-endo | nt 3 – 1% C4’-exo | |
| nt 4 – 50% C4’-exo | nt 4 – 90% C4’-exo | nt 4 – 1% C4’-exo | |
| nt 5 – 100% C2’-endo | nt 5 – 98% C2’-endo | nt 5 – 26% C2’-endo | |
| nt 6 – 100% C3’-endo | nt 6 – 100% C3’-endo | nt 6 – 91% C3’-endo | |
| Stacking between nt 3 and nt 4 | 50% | 97% | 59% |
n = number of sequence-representative structures in this cluster.
Red values indicate interactions that are found among ≥75% of sequence-representative structures in this cluster and <75% of structures among all other tetraloops.
Blue values indicate interactions found in <75% of sequence-representative structures (n = 2) but found in ≥75% of the total number of structures represented by the sequences in this cluster (x = 59).
x = total number of structures represented by the sequences in this cluster.
As mentioned previously, while the dataset was being prepared for clustering, an average structure was selected to represent each unique sequence to reduce sequence bias. These structures are referred to as sequence-representative structures, and it is these structures which are used for clustering. However, each sequence-representative structure can represent multiple structures for the same sequence. For example, the UYGARG cluster contains two sequence-representative structures, but the total number of structures represented by the cluster is 59 (56 structures with the sequence UCGAAG and 3 structures with the sequence UUGAGG, Tables 1 and S2). While the syn glycosidic angle in nt 3 is only present in one of the two sequence-representative structures of the UYGARG cluster, this interaction is present in 57 out of 59, or 97%, of the total structures in the cluster. Interactions such as these may be overestimated or underestimated in the clusters. Interactions that are not present in the majority of sequence-representative structures but are present in the majority of the total structures representing the UYGARG cluster are shown in blue text in Table 5. Other similar interactions include: C4’-exo sugar pucker conformation in nt 3 and nt 4 and a stacking interaction between nt 3 and nt 4 (Fig. 3D and Table 5, blue text). While not present in the majority of sequence-representative structures, we consider these interactions to be features that distinguish this sequence family from the rest of the tetraloops. It should be noted that the overall structure of this cluster resembles clusters (clusters 14 and 19) identified previously using a nucleobase-centered, sequence-independent continuous metric distance approach and a slightly different definition of a tetraloop.15
The second new cluster is KUGGUM. Hairpins in this sequence family are represented in this database by nine 3D structures of tRNA. This cluster consists of two unique sequences: GUGGUC and UUGGUA. The sequence representative structure for GUGGUC is the crystal structure of O-phosphoseryl-tRNA kinase complexed with selenocysteine tRNA and 5’-adenylyl imidodiphosphate (PDB ID 3ADB). This tetraloop is located in the D-arm and has tertiary interactions with the T-arm and the protein. The sequence representative structure for UUGGUA is the crystal structure of O-phosphoseryl-tRNA kinase complexed with the anticodon-stem/loop of truncated tRNA (selenocysteine) (PDB ID 3AM1). Similarly, this tetraloop has tertiary interactions with the TΨC loop and the protein.
The interactions common to the KUGGUM fold include anti glycosidic conformation in all nts; pairing between nt 1 and nt 6; C3’-endo sugar pucker conformation in nt 1, nt 2, and nt 6; and a stacking interaction between nt 1 and nt 2 (Fig. 3E and Table 6). In addition to these interactions, the KUGGUM cluster also possesses several interactions that distinguish the sequence-representative structures within this cluster from all other tetraloop sequence-representative structures including: base pairing between nt 4 and nt 5; a hydrogen bond between O2’ of nt 2 and OP1 of nt 4; a hydrogen bond between OP1 of nt 5 and O2’ of nt 6; a hydrogen bond between N2 of nt 4 and O4 of nt 5; and C2’-endo sugar pucker conformation in nt 3 and nt 5 (Fig. 3E and Table 6, red text).
Table 6.
KUGGUM cluster analysis (Figure 3E).
| Interaction | Percentage of KUGGUM sequence-representative structures with interaction (n = 2)a, b, c | Percentage of all KUGGUM structures in cluster with interaction (x = 9)d | Percentage of all other tetraloop sequence-representative structures with interaction |
|---|---|---|---|
| All nts have an anti glycosidic angle | nt 1 – 100% anti | nt 1 – 100% anti | nt 1 – 100% anti |
| nt 2 – 100% anti | nt 2 – 100% anti | nt 2 – 99% anti | |
| nt 3 – 100% anti | nt 3 – 100% anti | nt 3 – 93% anti | |
| nt 4 – 100% anti | nt 4 – 100% anti | nt 4 – 93% anti | |
| nt 5 – 100% anti | nt 5 – 100% anti | nt 5 – 87% anti | |
| nt 6 – 100% anti | nt 6 – 100% anti | nt 6 – 100% anti | |
| Base pairing between nt 1 and nt 6 | 100% | 100% | 99% |
| Base pairing between nt 4 and nt 5 | 100% | 100% | 0% |
| Hydrogen bond between O2’ (hydroxyl) of nt 2 and OP1 of nt 4 | 100% | 100% | 1% |
| Hydrogen bond between OP1 of nt 5 and O2’ (hydroxyl) of nt 6 | 100% | 78% | 0% |
| Hydrogen bond between N2 (amino) of nt 4 and O4 (carbonyl) of nt 5 | 100% | 100% | 0% |
| Hydrogen bond between O2’ (hydroxyl) of nt 4 and OP2 of nt 5 | 50% | 78% | 0% |
| nt 1, nt 2, an nt 6 have C3’-endo sugar pucker conformation; nt 3 and nt 5 have C2’-endo sugar pucker conformation | nt 1 – 100% C3’-endo | nt 1 – 100% C3’-endo | nt 1 – 96% C3’-endo |
| nt 2 – 100% C3’-endo | nt 2 – 100% C3’-endo | nt 2 – 81% C3’-endo | |
| nt 3 – 100% C2’-endo | nt 3 – 89% C2’-endo | nt 3 – 30% C2’-endo | |
| nt 5 – 100% C2’-endo | nt 5 – 100% C2’-endo | nt 5 – 26% C2’-endo | |
| nt 6 – 100% C3’-endo | nt 6 – 100% C3’-endo | nt 6 – 91% C3’-endo | |
| Stacking between nt 1 and nt 2 | 100% | 100% | 75% |
n = number of sequence-representative structures in this cluster.
Red values indicate interactions that are found among ≥75% of sequence-representative structures in this cluster and <75% of structures among all other tetraloops.
Blue values indicate interactions found in <75% of sequence-representative structures (n = 2) but found in ≥75% of the total number of structures represented by the sequences in this cluster (x = 9).
x = total number of structures represented by the sequences in this cluster.
Similar to that discussed above for the UYGARG cluster, while the hydrogen bond between O2’ of nt 4 and OP2 of nt 5 is only present in one of the two sequence-representative structures of the KUGGUM cluster, this interaction is present in 7 out of 9, or 78%, of the total structures in the cluster (Fig. 3E and Table 6, blue text). While not present in the majority of sequence-representative structures, we consider this interaction to be a feature that distinguishes this sequence family from the rest of the tetraloops.
The third new cluster is YRMSAR. Hairpins in this sequence family are represented in this database by 98 3D structures, mostly of rRNA. This sequence family is also prevalent in group I intron secondary structures. This cluster consists of two unique sequences: CGAGAG and UACCAA. The sequence representative structure for CGAGAG is the crystal structure of azithromycin bound to a mutant 50S ribosomal subunit of Haloarcula marismortui (PDB ID 1YHQ). This tetraloop does not appear to have any tertiary interactions. The sequence representative structure for UACCAA is the crystal structure of the 50S ribosomal subunit from Deinococcus radiodurans in complex with hygromycin A (PDB ID 5DM7). Similarly, this tetraloop does not appear to have any tertiary interactions.
The interactions common to the YRMSAR fold include an anti glycosidic conformation in all nucleotides; pairing between nt 1 and nt 6; and a C3’-endo sugar pucker conformation in nt 1, nt 2, and nt 6 (Fig. 3F and Table 7). In addition to these interactions, the YRMSAR cluster also possesses several interactions that distinguish the structures within this cluster from all other tetraloop sequence-representative structures. These interactions include a C3’-endo sugar pucker conformation in nt 3, nt 4, and nt 5, and extensive stacking interactions between nt 2 and nt 3, nt 3 and nt 4, nt 4 and nt 5, and nt 5 and nt 6 (Fig. 3F and Table 7, red text). It should be noted that the structural features of this cluster resemble the four-base stack (cluster 11) identified previously using a nucleobase-centered, sequence-independent continuous metric distance approach and a slightly different definition of a tetraloop.15 The structure of CGAGAG in PDB ID 1jj2, a member of this tetraloop sequence family, was previously highlighted in a 3D structure study using the Structural Classification of RNA (SCOR) database.19, 56
Table 7.
YRMSAR cluster analysis (Figure 3F).
| Interaction | Percentage of YRMSAR sequence-representative structures with interaction (n = 2)a, b | Percentage of all YRMSAR structures in cluster with interaction (x = 98)c | Percentage of all other tetraloop sequence-representative structures with interaction |
|---|---|---|---|
| All nts have an anti glycosidic angle | nt 1 – 100% anti | nt 1 – 100% anti | nt 1 – 100% anti |
| nt 2 – 100% anti | nt 2 – 100% anti | nt 2 – 99% anti | |
| nt 3 – 100% anti | nt 3 – 100% anti | nt 3 – 93% anti | |
| nt 4 – 100% anti | nt 4 – 100% anti | nt 4 – 93% anti | |
| nt 5 – 100% anti | nt 5 – 100% anti | nt 5 – 87% anti | |
| nt 6 – 100% anti | nt 6 – 100% anti | nt 6 – 100% anti | |
| Base pairing between nt 1 and nt 6 | 100% | 100% | 99% |
| All nts have a C3’-endo sugar pucker conformation | nt 1 – 100% C3’-endo | nt 1 – 98% C3’-endo | nt 1 – 96% C3’-endo |
| nt 2 – 100% C3’-endo | nt 2 – 99% C3’-endo | nt 2 – 81% C3’-endo | |
| nt 3 – 100% C3’-endo | nt 3 – 94% C3’-endo | nt 3 – 57% C3’-endo | |
| nt 4 – 100% C3’-endo | nt 4 – 99% C3’-endo | nt 4 – 58% C3’-endo | |
| nt 5 – 100% C3’-endo | nt 5 – 99% C3’-endo | nt 5 – 61% C3’-endo | |
| nt 6 – 100% C3’-endo | nt 6 – 100% C3’-endo | nt 6 – 91% C3’-endo | |
| Stacking between nt 2 and nt 3 | 100% | 61% | 9% |
| Stacking between nt 3 and nt 4 | 100% | 96% | 58% |
| Stacking between nt 4 and nt 5 | 100% | 98% | 52% |
| Stacking between nt 5 and nt 6 | 100% | 62% | 36% |
n = number of sequence-representative structures in this cluster.
Red values indicate interactions that are found among ≥75% of sequence-representative structures in this cluster and <75% of structures among all other tetraloops.
x = total number of structures represented by the sequences in this cluster.
In summary, six sequence families were identified and characterized from among all tetraloops. Each of the families possesses tertiary structural features which distinguish them from each other and from all other tetraloops (Fig. 3 and Tables 2–7). Three families (NGNRAG, SUWCGS, and GAUNAC) have been previously identified by the literature (GNRA, UNCG, and RNYA, respectively). However, interactions that have not been previously discussed in the literature were identified among these three clusters, further refining the distinguishing features of the existing sequence families. Additionally, three novel sequence families (UYGARG, KUGGUM, and YRMSAR) were identified and characterized. These three new sequence families add to the current understanding of tetraloop tertiary structure and can be used to assist in our inferences of tetraloop tertiary structure from secondary structure.
Supplementary Material
ACKNOWLEDGMENT
The authors would like to thank Nicole Meyer, Amber Davis, Matthew Stark, and Zexiang Chen for laying the groundwork for the development of this protocol.
FUNDING SOURCES
This work was supported by the National Institutes of Health [2R15GM085699-03]. Funding for open access charge: National Institutes of Health.
ABBREVIATIONS
- CoSSMos
Characterization of Secondary Structure Motifs
- DSSR
Dissecting the Spatial Structure of RNA
- PDB
Protein Data Bank
- N
Any nucleotide
- R
G or A
- Y
C or U
- M
A or C
- UPGMA
Unweighted pair group method with arithmetic mean
- S
G or C
- W
A or U
- K
G or U
Footnotes
SUPPORTING INFORMATION
Tables showing the tetraloops that failed the quality check, representative structures for each unique sequence, the degenerate sequence and number of unique sequences for each cluster, and sequence analysis of clusters are available in the supporting information.
REFERENCES
- [1].Eddy SR (2001) Non-coding RNA genes and the modern RNA world, Nat. Rev. Genet 2, 919–929. [DOI] [PubMed] [Google Scholar]
- [2].Strekowski LW,B (2007) Noncovalent interactions with DNA: an overview, Mutat. Res 623, 3–13. [DOI] [PubMed] [Google Scholar]
- [3].Lee JH, Culver G, Carpenter S, and Dobbs D (2008) Analysis of the EIAV Rev-responsive element (RRE) reveals a conserved RNA motif required for high affinity rev binding in both HIV-1 and EIAV, PLoS One 3, e2272–e2272. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Donarski J, Shammas C, Banks R, and Ramesh V (2006) NMR and molecular modelling studies of the binding of amicetin antibiotic to conserved secondary structural motifs of 23S ribosomal RNAs, J. Antibiot 59, 177–183. [DOI] [PubMed] [Google Scholar]
- [5].Fimiani C, Goina E, Su Q, Gao G, and Mallamaci A (2016) RNA-therapeutics of gene haploinsufficiencies, Hum. Gene Ther 27, A144–A144. [Google Scholar]
- [6].Barata P, Sood AK, and Hong DS (2016) RNA-targeted therapeutics in cancer clinical trials: Current status and future directions, Cancer Treat Rev 50, 35–47. [DOI] [PubMed] [Google Scholar]
- [7].Connelly CM, Moon MH, and Schneekloth JS (2016) The emerging role of RNA as a therapeutic target for small molecules, Cell Chem Biol 23, 1077–1090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Miao Z, Adamiak RW, Antczak M, Batey RT, Becka AJ, Biesiada M, Boniecki MJ, Bujnicki JM, Chen SJ, Cheng CY, Chou FC, Ferre-D’Amare AR, Das R, Dawson WK, Ding F, Dokholyan NV, Dunin-Horkawicz S, Geniesse C, Kappel K, Kladwang W, Krokhotin A, Lach GE, Major F, Mann TH, Magnus M, Pachulska-Wieczorek K, Patel DJ, Piccirilli JA, Popenda M, Purzycka KJ, Ren A, Rice GM, Santalucia J, Sarzynska J, Szachniuk M, Tandon A, Trausch JJ, Tian S, Wang J, Weeks KM, Williams B, Xiao Y, Xu X, Zhang D, Zok T, and Westhof E (2017) RNA-Puzzles Round III: 3D RNA structure prediction of five riboswitches and one ribozyme, RNA 23, 655–672. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Shapiro BA, Yingling YG, Kasprzak W, and Bindewald E (2007) Bridging the gap in RNA structure prediction, Curr. Opin. in Struct. Biol 17, 157–165. [DOI] [PubMed] [Google Scholar]
- [10].Boniecki MJ, Lach G, Dawson WK, Tomala K, Lukasz P, Soltysinski T, Rother KM, and Bujnicki JM (2016) SimRNA: a coarse-grained method for RNA folding simulations and 3D structure prediction, Nucleic Acids Res. 44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Popenda M, Szachniuk M, Antczak M, Purzycka KJ, Lukasiak P, Bartol N, Blazewicz J, and Adamiak RW (2012) Automated 3D structure composition for large RNAs, Nucleic Acids Res. 40. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Xia Z, Bell DR, Shi Y, and Ren PY (2013) RNA 3D Structure Prediction by Using a Coarse-Grained Model and Experimental Data, J. Phys. Chem. B 117, 3135–3144. [DOI] [PubMed] [Google Scholar]
- [13].Petrov AI, Zirbel CL, and Leontis NB (2013) Automated classification of RNA 3D motifs and the RNA 3D Motif Atlas, RNA 19, 1327–1340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Wadley LM, and Pyle AM (2004) The identification of novel RNA structural motifs using COMPADRES: An automated approach to structural discovery, Nucleic Acids Res. 32, 6650–6659. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Bottaro S, and Lindorff-Larsen K (2017) Mapping the universe of RNA tetraloop folds, Biophys. J 113, 257–267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Liu YC, Yang CH, Chen KT, Wang JR, Cheng ML, Chung JC, Chiu HT, and Lu CL (2011) R3D-BLAST: A search tool for similar RNA 3D substructures, Nucleic Acids Res. 39, W45–W49. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Huang HC, Nagaswamy U, and Fox GE (2005) The application of cluster analysis in the intercomparison of loop structures in RNA, RNA 11, 412–423. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Schudoma C, May P, Nikiforova V, and Walther D (2010) Sequence-structure relationships in RNA loops: Establishing the basis for loop homology modeling, Nucleic Acids Res. 38, 970–980. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Klosterman PS, Tamura M, Holbrook SR, and Brenner SE (2002) SCOR: A structural classification of RNA database, Nucleic Acids Res. 30, 392–394. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Apostolico A, Ciriello G, Guerra C, Heitsch CE, Hsiao C, and Williams LD (2009) Finding 3D motifs in ribosomal RNA structures, Nucleic Acids Res. 37, e29–e29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Hamdani HY, Appasamy SD, Willett P, Artymiuk PJ, and Firdaus-Raih M (2012) NASSAM: A server to search for and annotate tertiary interactions and motifs in three-dimensional structures of complex RNA molecules, Nucleic Acids Res. 40, W35–W41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Djelloul M, and Denise A (2008) Automated motif extraction and classification in RNA tertiary structures, RNA 14, 2489–2497. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Zhong C, and Zhang S (2012) Clustering RNA structural motifs in ribosomal RNAs using secondary structural alignment, Nucleic Acids Res. 40, 1307–1317. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Davis AR, Kirkpatrick CC, and Znosko BM (2011) Structural characterization of naturally occurring RNA single mismatches, Nucleic Acids Res. 39, 1081–1094. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].D’Ascenzo L, Leonarski F, Vicens Q, and Auffinger P (2017) Revisiting GNRA and UNCG folds: U-turns versus Z-turns in RNA hairpin loops, RNA 23, 259–269. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Vanegas PL, Hudson GA, Davis AR, Kelly SC, Kirkpatrick CC, and Znosko BM (2012) RNA CoSSMos: Characterization of Secondary Structure Motifs-A searchable database of secondary structure motifs in RNA three-dimensional structures, Nucleic Acids Res. 40, D439–D444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Richardson KE, Kirkpatrick CC, and Znosko BM (2019) RNA CoSSMos 2.0: An improved searchable database of secondary structure motifs in RNA three-dimensional structures, Database Submitted. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Sponer J, Bussi G, Krepl M, Banas P, Bottaro S, Cunha RA, Gil-Ley A, Pinamonti G, Poblete S, Jureacka P, Walter NG, and Otyepka M (2018) RNA Structural Dynamics As Captured by Molecular Simulations: A Comprehensive Overview, Chem. Rev 118, 4177–4338. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Woese CR, Winker S, and Gutell RR. (1999) Architecture of ribosomal-RNA-constraints on the sequence of tetra-loops, Proc. Natl. Acad. Sci U. S. A 87, 8467–8471. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Svoboda P, and Di Cara A (2006) Hairpin RNA: a secondary structure of primary importance, Cell. Mol. Life Sci 63, 901–918. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Hsiao C, Mohan S, Hershkovitz E, Tannenbaum A, and Williams LD (2006) Single nucleotide RNA choreography, Nucleic Acids Res. 34, 1481–1491. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Brion P, and Westhof E (1997) Hierarchy and dynamics of RNA folding, Ann. Rev. Biophys. Biomol. Struct 26, 113–137. [DOI] [PubMed] [Google Scholar]
- [33].Puglisi JD, Tan RY, Calnan BJ, Frankel AD, and Williamson JR (1992) Conformation of the TAR RNA-Arginine complex by NMR spectroscopy, Science 257, 76–80. [DOI] [PubMed] [Google Scholar]
- [34].Varani G (1995) Exceptionally stable nucleic-acid hairpins, Ann. Rev. Biophys. Biomol. Struct 24, 379–404. [DOI] [PubMed] [Google Scholar]
- [35].Chauhan S, and Woodson SA (2008) Tertiary interactions determine the accuracy of RNA folding, J. Am. Chem. Soc 130, 1296–1303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Correll CC, and Swinger K (2003) Common and distinctive features of GNRA tetraloops based on a GUAA tetraloop structure at 1.4 Angstrom resolution, RNA 9, 355–363. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Woese CR, Winker S, and Gutell RR (1990) Architecture of ribosomal-RNA-constraints on the sequence of tetra-loops, Proc. Natl. Acad. Sci. U. S. A 87, 8467–8471. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Varani G, Cheong C, and Tinoco I (1991) Structure of an unusually stable RNA hairpin, Biochemistry 30, 3280–3289. [DOI] [PubMed] [Google Scholar]
- [39].Ennifar E, Nikulin A, Tishchenko S, Serganov A, Nevskaya N, Garber M, Ehresmann B, Ehresmann C, Nikonov S, and Dumas P (2000) The crystal structure of a UUCG tetraloop, J. Mol. Biol 304, 35–42. [DOI] [PubMed] [Google Scholar]
- [40].Rowsell S, Stonehouse NJ, Convery MA, Adams CJ, Ellington AD, Hirao I, Peabody DS, Stockley PG, and Phillips SEV (1998) Crystal structures of a series of RNA aptamers complexed to the same protein target, Nat. Struct. Biol 5, 970–975. [DOI] [PubMed] [Google Scholar]
- [41].Jucker FM, and Pardi A (1995) Solution structure of the CUUG hairpin loop: A novel RNA tetraloop motif, Biochemistry 34, 14416–14427. [DOI] [PubMed] [Google Scholar]
- [42].Keating KS, Toor N, and Pyle AM (2008) The GANC Tetraloop: A Novel Motif in the Group IIC Intron Structure, J. Mol. Biol 383, 475–481. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [43].Wu HH, Yang PK, Butcher SE, Kang S, Chanfreau G, and Feigon J (2001) A novel family of RNA tetraloop structure forms the recognition site for Saccharomyces cerevisiae RNase III, EMBO J. 20, 7240–7249. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [44].Butcher SE, Dieckmann T, and Feigon J (1997) Solution structure of the conserved 16 S-like ribosomal RNA UGAA tetraloop, J. Mol. Biol 268, 348–358. [DOI] [PubMed] [Google Scholar]
- [45].DeJong ES, Marzluff WF, and Nikonowicz EP (2002) NMR structure and dynamics of the RNA-binding site for the histone mRNA stem-loop binding protein, RNA 8, 83–96. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [46].Zanier K, Luyten I, Crombie C, Muller B, Schumperli D, Linge JP, Nilges M, and Sattler M (2002) Structure of the histone mRNA hairpin required for cell cycle regulation of histone gene expression, RNA 8, 29–46. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [47].Amarasinghe GK, De Guzman RN, Turner RB, and Summers MF (2000) NMR structure of stem-loop SL2 of the HIV-1 Psi RNA packaging signal reveals a novel A-U-A base-triple platform, J. Mol. Biol 299, 145–156. [DOI] [PubMed] [Google Scholar]
- [48].Parlea LG, Sweeney BA, Hosseini-Asanjan M, Zirbel CL, and Leontis NB (2016) The RNA 3D Motif Atlas: Computational methods for extraction, organization and evaluation of RNA motifs, Methods 103, 99–119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [49].Hanson RM, and Lu X-J (2017) DSSR-enhanced visualization of nucleic acid structures in Jmol, Nucleic Acids Res. 45, W528–W533. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [50].Lemieux S, and Major F (2006) Automated extraction and classification of RNA tertiary structure cyclic motifs, Nucleic Acids Res. 34, 2340–2346. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [51].Cock PJA, Antao T, Chang JT, Chapman BA, Cox CJ, Dalke A, Friedberg I, Hamelryck T, Kauff F, Wilczynski B, and de Hoon MJL (2009) Biopython: Freely available Python tools for computational molecular biology and bioinformatics, Bioinformatics 25, 1422–1423. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [52].Cavener DR (1987) Comparison of the consensus sequence flanking translational start sites in Drosophila and vertebrates, Nucleic Acids Res. 15, 1353–1361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [53].Han MV, and Zmasek CM (2009) phyloXML: XML for evolutionary biology and comparative genomics, BMC Bioinf. 10, 356. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [54].Heus HA, and Pardi A (1991) Structural features that give rise to the unusual stability of RNA hairpins containing GNRA loops, Science 253, 191–194. [DOI] [PubMed] [Google Scholar]
- [55].Jucker FM, Heus HA, Yip PF, Moors EHM, and Pardi A (1996) A network of heterogeneous hydrogen bonds in GNRA tetraloops, J. Mol. Biol 264, 968–980. [DOI] [PubMed] [Google Scholar]
- [56].Klosterman PS, Hendrix DK, Tamura M, Holbrook SR, and Brenner SE (2004) Three-dimensional motifs from the SCOR, structural classification of RNA database: extruded strands, base triples, tetraloops and U-turns, Nucleic Acids Res. 32, 2342–2352. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.