

Abstract
The paper concerns a new forecast model that includes the class of undiagnosed infected people, and has a multiregion extension, to cope with the in‐time and in‐space heterogeneity of an epidemic. The model is applied to the SARS‐CoV2 (COVID‐19) pandemic that, starting from the end of February 2020, began spreading along the Italian peninsula, by first attacking small communities in north regions, and then extending to the center and south of Italy, including the two main islands. It has proved to be a robust and reliable tool for the forecast of the total and active cases, which can be also used to simulate different scenarios. In particular, the model is able to address a number of issues, such as assessing the adoption of the lockdown in Italy, started from March 11, 2020; the estimate of the actual attack rate; and how to employ a rapid screening test campaign for containing the epidemic.
Keywords: epidemiology, mathematical model for epidemic, medical epidemiology, multiregion SIR‐type model
1. INTRODUCTION
Virus SARS‐CoV2 (COVID‐19) hit Italy at the end of February 2020: after the first patient diagnosed in Codogno (Lodi, Lombardy) on February 21, the virus spread very quickly in the Italian peninsula, particularly in Lombardy and in the Northern Italy. The syndrome of acute respiratory disease and the consequences of COVID‐19 put the national healthcare system under stress. The first epidemic phase was characterized by a huge number of patients with severe or critical conditions that congested Lombardy hospitals, particularly in the provinces of Lodi, Bergamo, and Brescia. Also neighboring provinces of the Emilia Romagna region were affected; hospitals of provinces of Piacenza and Parma had great difficulties to manage COVID‐19 patients. Disease spread in the regions around the epicenter of Lodi, but Italian government closed the country progressively: at the beginning, a red zone around Lodi was created; then, all the Lombardy was declared red zone; finally, on March 11, 2020, every region was locked down. * In Italy, the COVID‐19 spread has been inhomogeneous; in fact, in the north, the virus spread out before the lockdown and a huge number of people contracted the virus, whereas the Centre, South, and Italian islands regions (Sicily and Sardinia) had fewer cases, so that these regions were able to manage the disease. This regional differences were amplified by the lockdown in the country.
An inhomogeneous spread of COVID‐19 happened also in other countries and, where it coincides with a high‐density residential area and with high mobility, the results are dramatic, as it happened in Lombardy and in the metropolitan area of big cities, such as Madrid, London, and New York. In those cases, it is fundamental the capacity of resilience and resistance of the health sanitary system in the region where the spread exploded as a big pandemic wave. For these reasons mrSI2R2, the model given here, is a multiregional model that takes into account the inhomogeneous spread of the disease. Figure 1 shows how there is a huge regional difference in the SARS‐CoV2 spread along the country.
FIGURE 1.
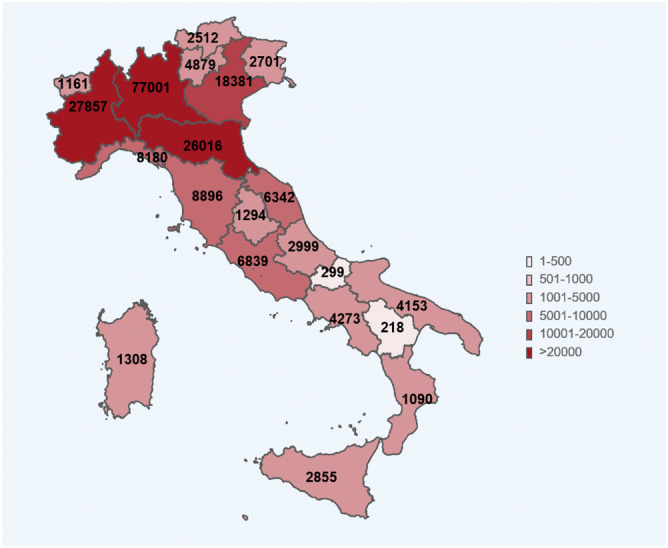
COVID‐19 cases in the different regions of Italy on May 4, 2020 (source Italian Istituto Superiore di Sanità) [Colour figure can be viewed at wileyonlinelibrary.com]
The incubation period of COVID‐19 is quite long; for this reason, when the first patient, not imported from China, was diagnosed in Lombardy on the 21st of February, SARS‐CoV2 was already spread in the most populated Italian region. The virus was circulating since the beginning of February in Italy, as is demonstrated by the onset data released by the Health National Institute. Once people are diagnosed positive to COVID‐19 from tests, they are asked when they felt first symptoms, and the onset data are drawn on the graph (see Figure 2). In fact, we never talked in Italy about the patient‐zero, but it was always considered at least the patient‐one.
FIGURE 2.
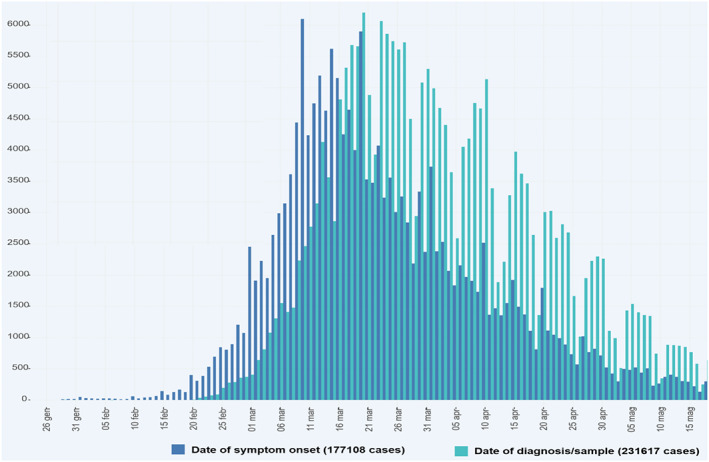
Diagnoses and onset of symptoms for patients in Italy (source Italian Istituto Superiore di Sanità) 1 [Colour figure can be viewed at wileyonlinelibrary.com]
For this reason, the Italian healthcare system, as other European national health systems in Spain, France, United Kingdom, and Belgium, was not prepared to manage the first epidemic wave in Europe. The course of the COVID‐19 disease is quite long; it takes several days from the virus contact to the first symptoms to hospitalization to death or recovery. Fastest cases take more than 1 week, and many other cases have a disease course of several weeks of hospitalization.
It is impossible to test the entire population of a country in a short time, to verify the presence of SARS‐CoV2 virus. Above all, at the beginning of the epidemic, tests were scarce. A big part of the population has contracted the virus, but it is not included in the “positive cases” statistics, both for the presence of asymptomatic people and for the difficulty of testing people with clear COVID‐19 symptoms. A healthcare system has to be prepared in the future to test hundreds of thousands people each day. Tests are really important to fight the virus as they are able to seek positive people, to isolate them, and to contain the virus spread.
The lack of intensive care unit (ICU) beds, medical devices such as lung fans, and even oxygen has amplified the impact of COVID‐19 in the most affected areas. To this must be added the lack of an adequate number of doctors, nurses, and health workers and, in some cases, even that of personal protective equipment. All this, combined with the fact that COVID‐19 is a new disease, little known even in the medical field, has increased the apparent lethality rate, particularly in the areas most affected by the spread of the virus. The preparation of the national healthcare system is therefore decisive both for the containment of the disease and for its ability to limit its most harmful effects on people. The creation of a forecast model that manages to alert the decision‐making bodies and, in particular, the healthcare system, is therefore decisive to hinder the emergence of any other pandemic outbreaks, or the arrival of subsequent pandemic waves.
The mathematical model mrSI2R2 has been introduced for this reason and has proved to be able to predict the trend of the positive cases with an accuracy greater than 90%, 3 weeks in advance. Having more than 20 days to prepare for the management of a further pandemic outbreak, even on a regional and local basis, is essential to set up suitable containment measures in due time. Based on an extension of the classical SIR equations (see, e.g., Luenberger 2 ), the new model takes the form of a delay differential system which incorporates the class of undiagnosed infected individuals: these are the actual responsible for virus shedding during their infectivity period, unless they are detected for some reason and, therefore, quarantined. Within this class are asymptomatic and pauci‐symptomatic people, as well as infectious presymptomatic people, considering that a significant portion of transmission is expected to occur before infected persons have developed symptoms. 3 To take account for the time lag between infectiousness onset, appearance of symptoms, and infection detection, a delay time τ is introduced in the equations, making the resulting system very well suited to fit the observed data. Furthermore, to account for the in‐space and in‐time heterogeneity of the epidemic diffusion, the Italian peninsula has been subdivided into four macro‐areas, and a new term has been introduced in the equations to consider the effect of a possible migration from one area to another, given that even a small uncontrolled flow of infected people may cause the appearance of a new source of infection in a clean zone.
The mathematical modeling of the COVID‐19 spread has been the subject of many investigations (see, e.g., other studies 4 , 5 , 6 , 7 ). The model here considered, though quite refined in the description of the underlying infection mechanisms, tries to keep at minimum the number of the involved variables and parameters to be estimated, in order to reduce the risk of redundancy (existence of multiple solutions) and, at the same time, to provide a reliable and computationally affordable forecast tool. Among the other features, this model is able to predict the actual portion of infected people (attack rate), to outline the benefits of the lockdown, and to assess the extent to which rapid screening tests may help in mitigating the risk of a future escalation of the infection.
With these premises, the structure of the paper is as follows: in Section 2, we present the SI2R2 model and its multiregion extension (mrSI2R2); in Section 3, we study a number of application of the model to the spread of the epidemic in Italy; and finally, a few concluding remarks are reported in Section 4.
2. THE MODEL
In case of a single region, we divide the population into the following five classes:
-
S:
Susceptive individuals, circulating healthy people who come in contact with infected persons and, thus, can catch the virus;
-
I
1:
Infected undiagnosed individuals, the subclass of infected people who can spread the disease (carriers);
-
I
2:
Infected diagnosed individuals, the subclass of infected people who tested positive for COVID‐19 and, thus, quarantined;
-
R
1:
Removed undiagnosed individuals, spontaneously recovered people coming from class I 1;
-
R
2:
Removed diagnosed individuals, either recovered or died people coming from class I 2.
It is worth emphasizing that, distinguishing between I 2 and R 2 among the diagnosed people, allows to better exploit the available dataset.
Recovering from the illness seems to give some immunity. 8 , 9 Consequently, considering that we are mainly interested in describing the “early dynamics” of the epidemic, recovered people are assumed to be not susceptive anymore. The diagram in Figure 3 elucidates the interactions between the above classes defining the basic SI2R2 model. †
FIGURE 3.
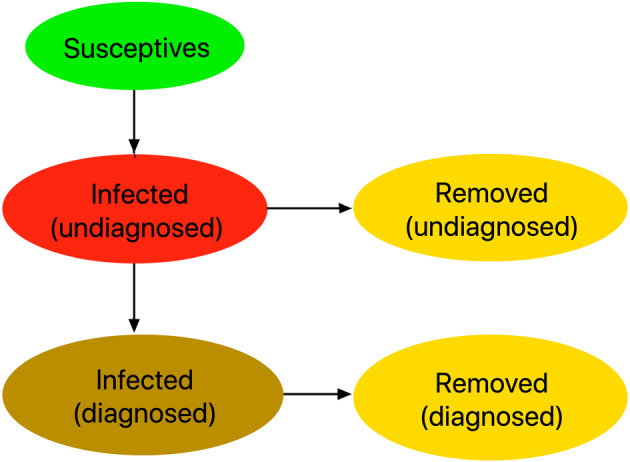
Interactions among the classes of the SI2R2 model [Colour figure can be viewed at wileyonlinelibrary.com]
Concerning our definition of susceptive people (class S), a remark is in order. In contrast with what is usually done in the literature, we leave the initial value of S as an unknown parameter. Its value has to be determined during the optimization procedure, which estimates the set of the involved parameters in order to fit the observed data as close as possible. We made this choice for two main reasons:
on one hand, the assumption underlying general epidemic models that the population is subject to a form of homogeneous mixing (see, e.g., Luenberger 2 ), evidently does not apply in our context: as was outlined in Section 1, local sources of infection have spread the disease in neighboring areas first, so that the number of healthy people coming in contact with the virus was far from being equal to all the population during the first stages of the epidemic diffusion;
on the other hand, our choice reflects the final goal of social‐distancing measures, such as the lockdown, where people are isolated to prevent possible contacts with the virus. In this regard, it should be noted that in some regions, the spread has been confined to small areas and, thus, did not affect the whole population that much.
Hereafter, in order to keep the notation as simple as possible, we shall make the following formal correspondences between compartments and variables describing their numerosity:
The SI2R2 model is then described by the following equations,
| (1) |
where:
β is the coefficient of infection rate;
γ 1 and γ 2 are the removal coefficients of the two classes y 1 and y 2, respectively;
σ is the probability of detection of infected people by means of the Covid tests campaign;
τ is a delay time, and accounts for the time elapsing between the onset of infectiousness and the detection of the disease, for example, after the appearance of symptoms or a contact‐tracing procedure;
is a switch factor which prevents the corresponding solution component to became negative.
Considering that the sum of the right‐hand sides in Equation (1) identically vanishes, we get the conservation property
| (2) |
the total number of people entering the model, which remains constant over time.
All the parameters listed above were left free, with the exception of the removal coefficient γ 1 and the delay time τ, which have instead been inferred from the literature. The remaining parameters have been tuned in order to assure a good fitting with the observed data by employing a global optimization procedure. The reason for fixing γ 1 a priori is that, otherwise, a certain parameter redundancy was experienced and, consequently, the model appeared not locally identifiable. This means that different but close configurations of the parameters could be selected leading to essentially the same accuracy in fitting the observed data. Based on the results reported in Noh et al, 10 we have set
| (3) |
where d stands for days. As for the choice of the delay time τ, we have confined the analysis to symptomatic individuals only and considered two additive contributions: the period of infectiveness before the development of symptoms plus the the time duration from the onset of symptoms and diagnosis. Their mean values have been inferred from Xi et al 3 and the data available at https://www.epicentro.iss.it, 11 respectively, resulting in the choice . Figure 2 better clarifies this aspect. It shows bar diagrams on the dates of onset of symptoms (dark blue bars) and dates of diagnosis (light blue bars). We have noted that the peak of onset date was on March 10, the last day before Italy tightened the lockdown. Positives on diagnoses tests continued to rise for 10 days before reversing the trend. ‡ In principle, a couple of days should be added to this delay time, due to the period of infectiveness before the development of symptoms. 3 However, we have kept the value considering that (a) a certain percentage of infected people is diagnosed before symptoms occur and (b) the results obtained by using nearby values of τ were pretty similar.
To cope with the heterogeneous nature of the spread of COVID‐19 disease across the Italian peninsula (see, e.g., the data in Figure 1 or the web‐pages 11 , 12 , 13 ), we have introduced a multiregion extension of the basic model (1). In more details, assuming that we have divided the country into r regions, the multiregion version of Equation (1) reads:
| (4) |
where x i , y i1, y i2, z i1, z i2, β i , σ i , γ i1, and γ i2 are related to the ith region and are defined as for Equation (1). § As before, we set as in Equation (3). We see that
is the (time‐dependent) number of individuals in the ith region, whereas the migration coefficients ρ ij satisfy
| (5) |
due to the fact that ρ ij , i ≠ j is the coefficient of migration from region j to region i. We observe that, because of Equation (5), the sum of all right‐hand sides in Equatio (4) vanishes. As a result, one has that
| (6) |
which is the analogue of Equation (2) for the multiregion extension of the model.
For our purposes, we have divided Italy into the following macro‐regions, depending on the onset of the epidemic and the geography (see Figure 1),
Lombardy;
North, including Emilia Romagna, Friuli‐Venezia Giulia, Liguria, Piemonte, Trentino‐Alto Adige, Valle d'Aosta, and Veneto;
Center, including Abruzzo, Lazio, Marche, Toscana, and Umbria;
South (and islands), including Basilicata, Calabria, Campania, Molise, Puglia, Sardegna, and Sicilia.
3. RESULTS
Starting from February 24, 2020 (initial day ), the number of diagnosed active cases y i2(t n ) and the removed = recovered + deceased individuals z i2(t n ) at day t n , published on a daily basis by the Italian Civil Protection Department, 12 have been exploited to tune the parameters of the model (4) in order to fit the data in the ith macro‐region. The fitting procedure, carried out with the aid of the Matlab® optimization toolbox, ¶ has been split into three phases:
-
(a)
at first, in each macro‐region, we fit the corresponding total cases, y i2(t n ) + z i2(t n ), given by the diagnosed active cases and removed people. Adding the third and the last equations in Equation (4), we see that the removal coefficient γ i2 are not explicitly involved at this stage. Moreover, in this phase, we set the migration coefficients to 0, i.e., we at first neglect the inter‐regions movements;
-
(b)
the second optimization phase adapts the solution components y i2(t n ) (positive active cases) and removed (recovered or deceased) individuals z i2(t n ) in the ith macro‐region, to the observed data by suitably tuning the removal coefficient γ i2;
-
(c)
finally, a further improvement is gained by making the migration coefficients ρ ij in Equation (4) come into play.
The rationale behind this approach is to better exploit the degree of regularity of data and make the resulting minimization algorithm more efficient. In fact, in each macro‐region, the total cases exhibit a more regular temporal distribution, and thus, in performing phase (a), they play a more important role in tuning all the free parameters except γ i2.
The task of splitting the total cases into the two classes of positive active cases, y i2(t n ), and removed cases, z i2(t n ), is assigned to phase (b). Here, the data display a much more irregular behavior especially in Lombardy, probably due to the human interference in deciding when an infected individual is to be considered completely recovered. As a matter of fact, a huge amount of positive cases moving from active to recovered may be observed in some specific days. This is mainly due to the criteria of discharge of COVID‐19 patients adopted in Italy and, in particular, to the “negativization tests” for home‐quarantined people (hospitalized discharges are less affected by this phenomenon). For this reason, the coefficients γ i2 have been assumed piecewise‐constant on time intervals of length of (at least) 30 d.
Lastly, phase (c) refines the fitting of the solution to the data: it has played a significant role during the days approaching the lockdown which saw a considerable number of workers and students, native to South Italy, to leave the northern regions in order to avoid the quarantine restrictions imposed by the Italian government.
The results for the whole country are obtained by summing those in each macro‐region. To this end, hereafter, we set:
| (7) |
representing the five classes of the model related to Italy.
3.1. Reliability of the model
Forecasts of the total and active confirmed positive cases, in the above four macro‐regions and Italy, are generated every day and collected at the web‐site 16 starting from April 1, 2020. Here, we report a few of them, in order to show the reliability of the model.
3.1.1. Detection of the pick of confirmed active cases
On April 19, the curve of the Italian active (diagnosed) cases y 2(t n ) attained its maximum of 108,257 individuals and exhibited a flat slope in the neighboring days before slowing down. To check the accuracy of the model in predicting the peak day and the number of total confirmed cases y 2(t n ) + z 2(t n ), we have solved the model by fitting its solutions to the observed data available on April 1 and 22. The results for these two datasets are displayed in the top and bottom pairs of pictures in Figure 4, respectively. The solid lines are predicted by the model, whereas the circles correspond to the observed data. The dashed vertical lines locate the days around the predicted peak where the number of active cases differ at most of 0.4% from the maximum. We see that both the total cases and the peak day in Italy (corresponding to Day 55) are quite well‐predicted on a time range of more than twenty days.
FIGURE 4.
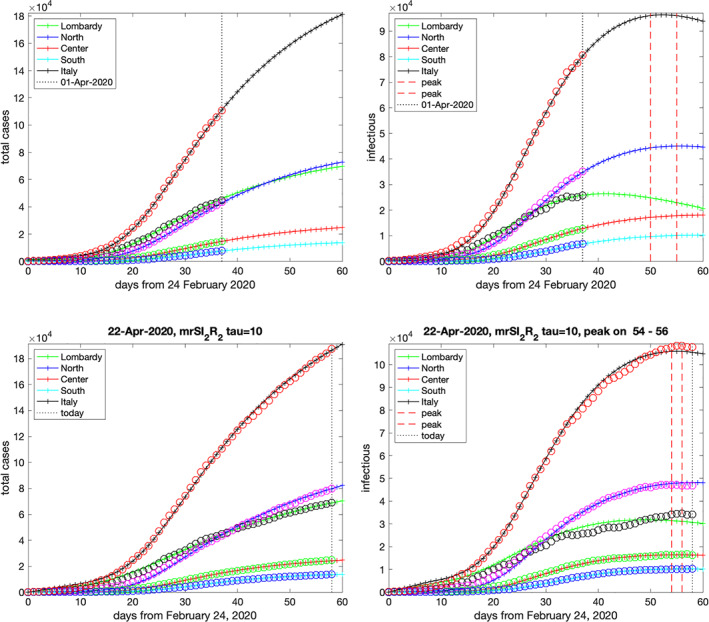
Forecast for the total cases (left pictures) and diagnosed active cases (right pictures) on April 1 and 22, 2020, respectively [Colour figure can be viewed at wileyonlinelibrary.com]
3.1.2. Estimation of the actual attack rate
It is widely believed that the number of infected people who remain hidden to COVID‐19 testing programs is likely far grater than the number of confirmed cases worldwide. The importance of practicing social distancing and safety measures not only reflects the risks associated with the presymptomatic stage of the disease but also suggests that an important role in the transmission of the virus might be played by asymptomatic and pauci‐symptomatic people. In absence of a population‐wide testing, it is difficult to estimate how many people get infected without showing significant symptoms. As for now, there are isolated studies which cannot be extended to general contexts, even though a percentage of asymptomatic carriers reaching the 80% among all infected people has been considered a possible outcome in areas with high prevalence of circulating infection. 17
While waiting for an extensive screening program, one route for investigating the number of hidden infections is to rely on a suitable compartmental epidemiological model, able to explain the dynamics of virus shedding in observed data and to yield possible scenarios of those classes of population that may not be directly traced (see, e.g., previous studies 4 , 5 , 6 ). By considering the class y 1(t) of untested infected people, our model offers a tool to get an estimation of the portion of population who actually got the virus (actual attack rate). We emphasize that, strictly speaking, our model does not consider a separate class for asymptomatic people, but we can get some insight into this additional question under suitable assumptions which depend on the context (see below for a discussion).
As a reference dataset to tune the parameters of the model, we used the observed data updated to May 24, 2020 (Day 90). ‖ The aim of the two upper pictures in Figure 5 is to assess the accuracy of the model in fitting the data. In particular:
the upper‐left picture shows the total confirmed cases (circles) and the corresponding solutions y i2(t n ) + z i2(t n ), , for the four macro‐regions and y 2(t n ) + z 2(t n ) for the whole Italy obtained in output by the model (solid lines). We see that the yielded accuracy is quite good, and is fostered by the regular course, from the appearance of the symptoms to the disease detection, ruling the transition from the class y i1 of infected untested people to the class y i2 of confirmed patients;
the upper‐right picture shows the active confirmed cases (circles) and the corresponding solutions y i2(t n ), , for the four macro‐regions and y 2(t n ) for the whole of Italy. In this case, the data display a certain irregularity especially in Lombardy and in the rest of Northern Italy. As was discussed above in the description of the optimization algorithm, here, the transition from illness (class y i2) to healing (class z i2) heavily depends on human decision‐making. In any event, the regular shape of the model solution curves describe the overall behavior of the data with good enough accuracy.
FIGURE 5.
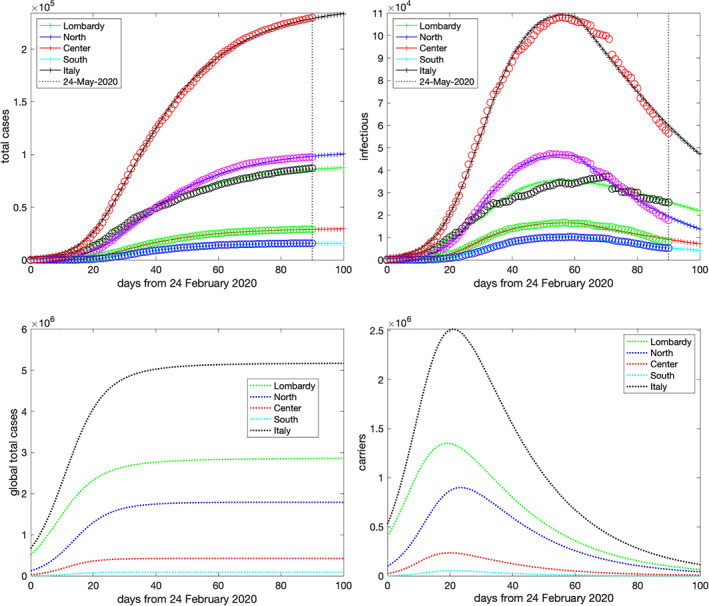
Top: simulated and actual data on May 24, 2020 (Day 90) for the total cases (left plot) and diagnosed active cases (right plot). Bottom: estimated global total cases and carriers using the parameters of May 24, 2020 (Day 90) [Colour figure can be viewed at wileyonlinelibrary.com]
After selecting the parameters, we can look at the other components of the solution which reveal the hidden side of virus diffusion in Italy. They are displayed in the two bottom pictures of Figure 5:
the bottom‐left picture shows the number of the overall infected individuals, namely, the total cases including both diagnosed and untested people. These are easily computed as the sums y i1(t) + z i1(t) + y i2(t) + z i2(t) in each macro‐region, and their sum for the whole Italy. The model reveals a very dramatic scenario with an actual attack rate far greater than the one corresponding to the confirmed cases. Table 1 summarizes the number of these global cases right after the end of lockdown on May 3, 2020, and compare them with the confirmed ones;
the bottom‐right picture shows the evolution in time of carriers, namely, the undiagnosed active cases forming the classes y i1(t) for each macro‐region and, according to Equation (7), y 1(t) for Italy. They exhibit a behavior quite different from that of the diagnosed active cases (upper‐right plot in Figure 5). The most evident difference concerns the peak day which occurs about 1 month earlier than the corresponding one in the diagnosed active cases. As is expected, it falls in proximity of the nation lockdown on March 11 (Day 16). Interestingly, our simulation reveals how the forced distancing‐measures, imposed by the government to all the nation, impacted on the infection growth curve which, after a few days, reached its maximal level and rapidly decreased during the subsequent days. Table 2 reports the day and the level of the peak in each macro‐region and in Italy.
TABLE 1.
Diagnosed and global total cases after the end of the lockdown
| Diagnosed | Global | Global/ | Immunity | ||
|---|---|---|---|---|---|
| Measured | Simulated | simulated | diagnosed ratio | rate (%) | |
| Lombardy | 78,105 | 78,910 | 2,841,561 | 36 | 28.2 |
| North | 91,600 | 89,544 | 1,792,530 | 20 | 10.1 |
| Center | 27,205 | 26,948 | 426,153 | 16 | 3.20 |
| South | 15,028 | 14,853 | 92,027 | 6 | 0.48 |
| Italy | 211,938 | 210,256 | 5,152,270 | 25 | 8.53 |
TABLE 2.
Peak of the carriers
| Lombardy | North | Center | South | Italy | |
|---|---|---|---|---|---|
| Day | 19 | 23 | 20 | 21 | 21 |
| Level | 1.4 · 106 | 9.0 · 105 | 2.4 · 105 | 5.3 · 104 | 2.5 · 106 |
The extent to which these percentages may reflect the real epidemic diffusion in Italy will be revealed once a screening of a wide random sample of population will be carried out. In any event, Table 1 discloses very different scenarios for the four analyzed macro‐areas, depending on the onset of the infection.
In the north of Italy, where the infection growth rate reached dramatic levels, the local healthcare system became overwhelmed. Consequently, a relevant number of infected people, even those experiencing symptoms, were supposed to escape any test detection. In support of this commonly shared hypothesis, one may observe that, from late February through all of March, there was a huge amount of not‐counted deaths which may indirectly be related to SARS‐Cov2. In Table 3, we summarize some results coming from a study performed by Italian Institute of Statistics (ISTAT) and ISS, dated May 4, which compares the total deaths from February 20 to March 31, 2020 (excluding February 29, 2020) with the yearly average deaths of the past 5 years. From the last column in Table 3, we see that a huge excess of morality, not ascribed to the virus lethality, has been experienced in this period by the northern regions. Among these are certainly deaths due by poor health conditions that might normally have been treated, if hospitals had not collapsed by a surge of patients needing intensive care. However, considering that deaths for and with COVID‐19 were counted only for those people who tested positive before passing away, it is not unfounded to argue that a considerable amount of such a discrepancy might be related to virus infection which, in turn, suggests a certain level of correlation between this excess of deaths and the actual proportion of population who has been infected without being diagnosed. In this respect, Table 1 shows that the estimated cumulative number of infected are about 25 times the confirmed ones in the whole of Italy, and even more in Lombardy, where an immunity rate of about 30% seems to be achieved at the end of lockdown.
TABLE 3.
Increase of mortality from February 20 to March 31, 2020
| Average | Deaths | Additional | ||
|---|---|---|---|---|
| Total deaths | total deaths | COVID‐19 | increase of | |
| 2020 | 2015–19 | 2020 | deaths 2020 | |
| Lombardy | 27,279 | 11,195 | 8,362 | 7,722 |
| North | 29,123 | 21,296 | 4,195 | 3,632 |
| Center | 13,985 | 13,120 | 749 | 116 |
| South | 20,559 | 19,981 | 404 | 174 |
| Italy | 90,946 | 65,592 | 13,710 | 11,644 |
On the contrary, in the center and south of Italy, the virus had a minor impact, and the public emergency measures were introduced in time, so that the spread was successfully contained. In particular, in the South of Italy, where the healthcare system did not go out of control, we can speculate that a great deal of untested infected people might actually be asymptomatic or pauci‐symptomatic. Under this simplifying assumption, from Table 1, we can guess that more than 80% of the simulated 92,027 individuals in the South of Italy could be mildly symptomatic. This percentage can make sense, also considering that a certain number of asymptomatic individuals is anyway detected by means of contact‐tracing policies, thus entering the class y 42 of confirmed cases.
Finally, we stress that the results illustrated above apply for the specific choice of the two static parameters γ 1 and τ in the model. A sensitivity analysis shows that, while increasing or decreasing τ of a couple of days does not produce considerable changes in the results, a variation of γ 1 seems to affect the solution more directly. In particular, diminishing the value of this parameter would result in an increase of the estimated values of the total cases so that, in this event, our results would underestimate the actual situation.
3.2. The lockdown effect
An interesting use of the model is to ascertain the benefits of lockdown, which was imposed by the authorities starting from March 11, 2020 (Day 16 starting from February 24). At that time, the spread of the disease in the regions of center and south of Italy was contained, and the data were scarce. Consequently, in our analysis of the prelockdown period (actually, before Day 24), we have discarded the data from regions in the center and south plus islands.
As was outlined above, the model (4) derives an estimate for the initial values of the susceptives, x i (0), (and thus for x(0), according to Equation 7), during the fitting phase (a). As one would expect, this number increases during the initial part of the spread of an epidemic, reflecting the space diffusion of the disease in new uninfected populated areas, until it eventually saturates the whole population of a given region.
In Figure 6, the circles are the number of susceptives in north of Italy (including Lombardy) estimated by the model (4), normalized by the whole population (about 2.7 · 107 people), with the solid line being its logistic approximation. Because of the lockdown, which is marked by the vertical dotted line at Day 16, one infers that about 20% of the whole population becomes eventually exposed to the virus. We see that, after the lockdown, the estimated susceptives continue to increase for about 10–12 days, which is consistent with the maximum period of incubation of the virus. After that, the number of susceptives stabilizes.
FIGURE 6.
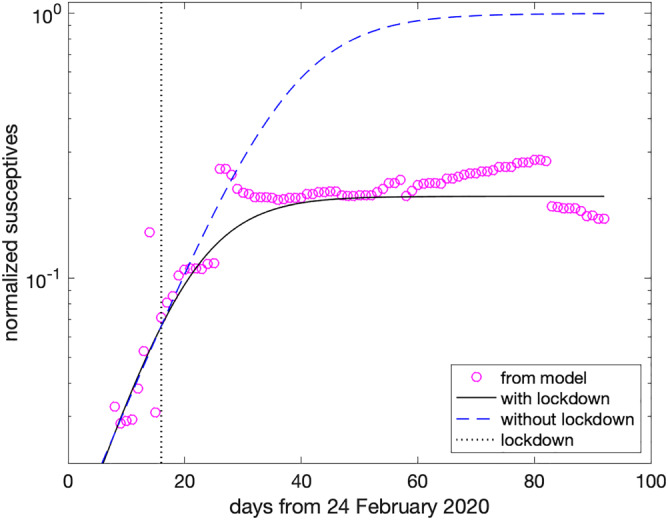
Scenario with and without lockdown in north of Italy (including Lombardy) [Colour figure can be viewed at wileyonlinelibrary.com]
To figure out how the scenario would have played out in absence of lockdown, we use the prelockdown data to define a new logistic approximation which coincides with the previous one until Day 16 (i.e., the day of lockdown) and eventually saturate the whole population. It is the dashed curve in Figure 6, showing that almost all population becomes susceptible after about 90 days (May 24, 2020). This reasoning allows us to virtually compare the real situation at Day 90, with a hypothetical one where all the parameters of the model remain fixed, but the susceptives, which are set equal to the whole population. The results are summarized in Figures 5, 7, and 8:
in Figure 5, we displayed the simulated curves (solid lines) and observed data (circles) for the total diagnosed cases and the active diagnosed cases on May 24, 2020 (i.e., Day 90). As one may see, the free parameters may be finely tuned in order to force the solution of Equation (4) to lie very close to the observed data in each macro‐region and, therefore, in the whole of Italy. Excluding the initial values x i (0) of susceptible individuals in each macro‐region, the set of parameters obtained by this simulation has then been used to infer the scenario in absence of lockdown;
in Figure 7, we report again the total cases and active diagnosed cases for the whole of Italy (solid line) in semilogarithmic scale, corresponding to the situation with lockdown, and compare them with the simulation obtained by using all the parameters as in the previous case, but the susceptives, which are set to the whole population in each macro‐region (dashed lines). As one may see, at Day 100, the forecast for the total cases passes from less than 2.5 · 105, with the lockdown, to about 5 · 106 in the no‐lockdown scenario. Correspondingly, the infectious individuals have a peak of about 105 cases, with lockdown, whereas it is more than 2 · 106 in the no‐lockdown case. Assuming the same lethality for the disease in the two scenarios, this would mean passing from about 3.4 · 104 deaths to about 7 · 105. It should be emphasized that the no‐lockdown scenario assumes that no new kind of emergency measure is introduced during the simulated period by the government or by the population itself and does not take into account a number of critical variables that would likely affect the obtained results such as, for example, the effects of overloading healthcare structures;
in Figure 8, it is depicted the simulation of the total susceptives and of undiagnosed infected people spontaneously recovered, i.e. (see Equation 7), the classes x(t) and z 1(t), with and without lockdown. As one may infer from the left plot, in the no‐lockdown case, one reaches a so‐called herd immunity, 18 with most of the population infected by the virus, even though many spontaneously recover, as is shown in the right plot of the figure.
FIGURE 7.
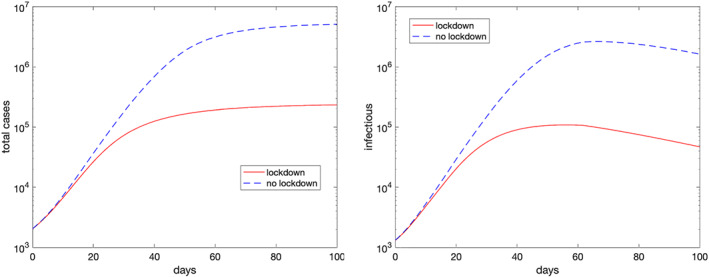
Simulated total cases (left plot) and diagnosed active cases (right plot) for the whole of Italy with and without lockdown using the parameters of May 24, 2020 (Day 90) [Colour figure can be viewed at wileyonlinelibrary.com]
FIGURE 8.
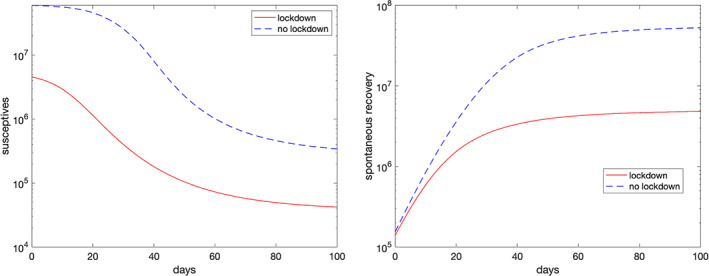
Simulated susceptives (left plot) and undiagnosed recovered (right plot) for the whole of Italy with and without lockdown using the parameters of May 24, 2020 (Day 90) [Colour figure can be viewed at wileyonlinelibrary.com]
3.3. Anticipating the lockdown
As was outlined above, the lockdown was able to stop the epidemic spread in the regions of the center and south of Italy where the contagious arrived later, whereas in the north of Italy, the situation has been much more critical, as is testified by the huge number of deaths with respect to the rest of the country. The question then arises as to when the north of Italy should have been locked down in order to share a development of the disease similar to that observed in the other regions.
To this end, in Figure 9, we plot the normalized susceptives estimated by the model in the north of Italy (including Lombardy, as we did in Figure 6), with the circles starting from Day 8, and in the center and south of Italy summed together, given by the squares starting at Day 24, since in the preceding days the cases where too few to have a sufficient statistical accuracy. Also in this case, the number of the susceptives is normalized by the population in center and south of Italy (about 3.3 · 107 people).
FIGURE 9.
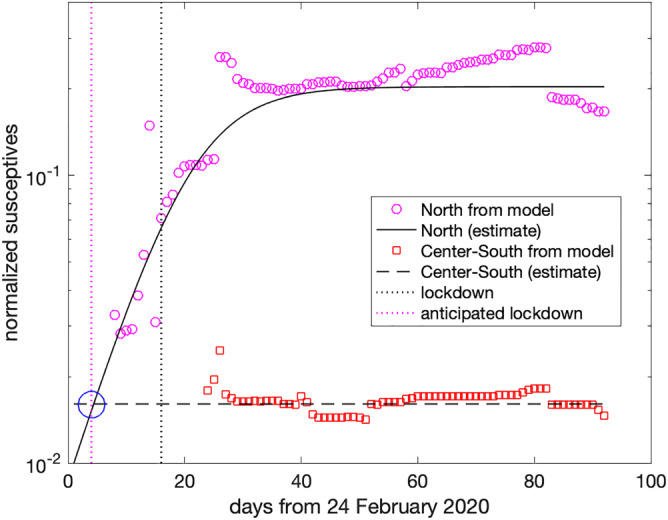
Effect of an anticipated lockdown at Day 4, instead of Day 16 [Colour figure can be viewed at wileyonlinelibrary.com]
As one may see, now the level of the susceptives exposed to the virus is much smaller (less than 2%), and this has been the main reason for the better situation in the center and south of Italy. Consequently, one infers that a similar outcome would have emerged in north of Italy, too, provided that the lockdown had started when the level of susceptives was similar. From the logistic approximation obtained before (solid line in Figure 9), one deduces that this would have been the case with the lockdown starting at Day 4, instead of Day 16 (see the circle at the intersection of the two estimates). This means that imposing a lockdown in north of Italy 2 weeks in advance would probably have guaranteed a much less dangerous spread of the epidemic.
3.4. Introducing rapid tests for screening
A way to reduce the impact of the epidemic after the end of the lockdown could be that of removing infective undiagnosed people by using rapid tests for detecting whether one is infective. Confining the analysis, for sake of simplicity, to the model (1), we then introduce an extra removal term in the second equation, thus getting:
| (8) |
where we have used the same notations as in Equation (1), with the fraction of individuals that undergoes the test. Also in this case, one verifies that the conservation property (2) holds true, with N the total number of individuals. The multiregion variant of Equation (8) is analogously derived.
In Figure 10, we show the simulation for Italy in case the lockdown is released, by using the parameters estimated at Day 90 (as we did before) but neglecting, for sake of simplicity, the migration terms. Consequently, we now allow all the people to become susceptive, though introducing a level of tests of 5%, 10%, 15%, and 20% in the population.
FIGURE 10.
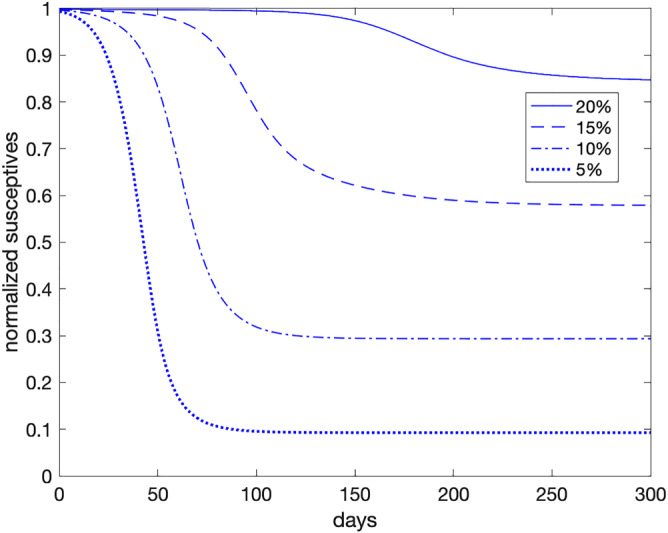
Simulated susceptives, using data on May 24, 2020 (Day 90) with the specified level of rapid tests [Colour figure can be viewed at wileyonlinelibrary.com]
As one may see, in order to get a scenario at Day 90 similar to the one yielded by the lockdown (about 15% of the population exposed to the virus), an amount of rapid tests equal to 20% of the whole Italian population should be administered on daily basis ( ). The exposed population (susceptives estimated by the model at time ) would rise to more than 40%, 70% and 90% if the tested people drop to 15%, 10%, and 5%, respectively. Even though it is not shown in the figure, a level test of 25% seems to be sufficient to make almost all population not exposed to the virus.
In conclusion, if rapid tests are administrated randomly to the population, only a high percentage amount would produce benefits comparable (or even better) to that of imposing a lockdown. Nonetheless, we could expect a significant improvement of their effectiveness, if addressing the rapid test campaign to people subject to a major risk of spreading the epidemic, such as people working in public offices, and markets.
4. CONCLUSIONS
In this paper, we have shown that the SI2R2 model and, in particular, its multiregion variant mrSI2r2, can be reliably used for predicting the evolution of the COVID‐19 epidemic in Italy. It can, therefore, represent a viable tool for optimizing the usage of a healthcare system. We have used it to asses the impact of lockdown on the management of this emergence, as well as to infer that bringing it forward by a couple of weeks would have presumably resulted into a much better outcome of the spread of the epidemic. We have also derived an estimate for the actual total infected people, i.e., both the diagnosed and the undiagnosed ones, guessing that the former are about 4% of the total. The model can be also extended to include the extensive usage of rapid tests to manage the epidemic when the lockdown is released. A further extension concerns the introduction of an age structure, in order to model the impact of the disease on the health care system more reliably. Clearly, this requires a suitable dataset to be available. At last, we would like to mention that in Equation (4), we don't consider terms related to migration from other countries, which we have indeed neglected for the lockdown period: an extension of the model could be done also in this direction.
CONFLICTS OF INTERESTS
The authors declare that this work does not have any conflict of interest.
ACKNOWLEDGEMENTS
The authors are very indebted to the wonderful team actively contributing the mrSIR project, including the “Associazione Italia Digitale.” We acknowledge the financial support of many generous donors. 19 We also wish to thank the referees for the useful comments.
Brugnano L, Iavernaro F, Zanzottera P. A multiregional extension of the SIR model, with application to the COVID‐19 spread in Italy. Math Meth Appl Sci. 2021;44:4414–4427. 10.1002/mma.7039
Footnotes
In more details, starting from 10 March it was forbidden to move from one region to another one, and every non essential activity was suspended on the 11th of March.
The acronym SI2R2 derives from the initials of the 5 classes.
This time shift is also consistent with the Italian regional data. 14
For the sake of simplicity, migration terms are neglected for the z i2 classes, also considering that these include died people. Furthermore, we also assume the migration coefficients ρ ij to be constant.
It is also worth mentioning that the numerical integration of the delay equations (4) has been done by using a high‐order Gauss–Legendre Runge–Kutta method used as spectral method in time, 15 which has allowed to greatly reduce the computational cost of the procedure, w.r.t. the use of the Matlab® function dde23.
This dataset will be also considered for later use.
REFERENCES
- 1. https://www.epicentro.iss.it/en/coronavirus/bollettino/Infografica_3giugno%20ENG.pdf, (accessed on 6 June 2020).
- 2. Luenberger DG. Introduction to Dynamic Systems: Theory, Models and Applications. New York: John Wiley and Sons; 1979:376‐378. [Google Scholar]
- 3. He X, Lau EHY, Wu P, et al. Temporal dynamics in viral shedding and transmissibility of COVID‐19. Nat Med Brief Commun. 2020;26:672‐675. 10.1038/s41591-020-0869-5 [DOI] [PubMed] [Google Scholar]
- 4. Fanelli D, Piazza F. Analysis and forecast of COVID‐19 spreading in China, Italy and France. Chaos, Solitons Fractals. 2020;134(109761). 10.1016/j.chaos.2020.109761 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Xinmiao F, Ying Q, Zeng T, Long T, Wang Y. Simulating and forecasting the cumulative confirmed cases of SARS‐CoV‐2 in China by Boltzmann function‐based regression analyses. Lett Ed/J Infect. 2020;80:578‐606. 10.1016/j.jinf.2020.02.019 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Giordano G, Blanchini F, Bruno R, et al. Modelling the COVID‐19 epidemic and implementation of population‐wide interventions in Italy. Nat Med Lett. 2020;26:855‐860. 10.1038/S41591-020-0883-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Remuzzi A, Remuzzi G. COVID‐19 and Italy: what next? The Lancet. 2020;395:1225‐1228. 10.1016/S0140-6736(20)30627-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. O Murchu E, Byrne P, Walsh KA, et al. Immune response following infection with SARS‐CoV‐2 and other coronaviruses: a rapid review. Rev Med Virol. 2020:e2162. 10.1002/rmv.2162 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Lan L, Xu D, Ye G, et al. Positive RT‐PCR test results in patients recovered from COVID‐19. JAMA. 2020;323(15):1502‐1503. 10.1001/jama.2020.2783 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Noh JY, Yoon JG, Seong H, et al. Asymptomatic infection and atypical manifestations of COVID‐19: comparison of viral shedding duration. J Infect. 2020;81:816‐846. 10.1016/j.jinf.2020.05.035 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. https://www.epicentro.iss.it, (accessed on 12 April 2020 and 4 May 2020).
- 12. https://www.protezionecivile.gov.it, (daily accessed).
- 13. https://en.wikipedia.org/wiki/COVID‐19_pandemic_in_Italy
- 14. https://www.epicentro.iss.it/coronavirus/bollettino/Bolletino‐sorveglianza‐integrata‐COVID‐19_26‐maggio‐2020_appendix.pdf, (accessed on 6 June 2020).
- 15. Amodio P, Brugnano L, Iavernaro F. Analysis of spectral Hamiltonian boundary value methods (SHBVMs) for the numerical solution of ODE problems. Numer Algoritm. 2020;83:1489‐1508. 10.1007/s11075-019-00733-7 [DOI] [Google Scholar]
- 16. https://www.mrsir.it/en/projections/
- 17. Ing AJ, Cocks C, Green JP. COVID‐19: in the footsteps of Ernest Shackleton. Thorax. 2020;75:613‐613. 10.1136/thoraxjnl-2020-215091 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Randolph HE, Barreiro LB. Herd immunity: understanding COVID‐19. Immunity. 2020;52:737‐641. 10.1016/j.immuni.2020.04.012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. https://www.mrsir.it/en/about‐us/