
Figure 1.
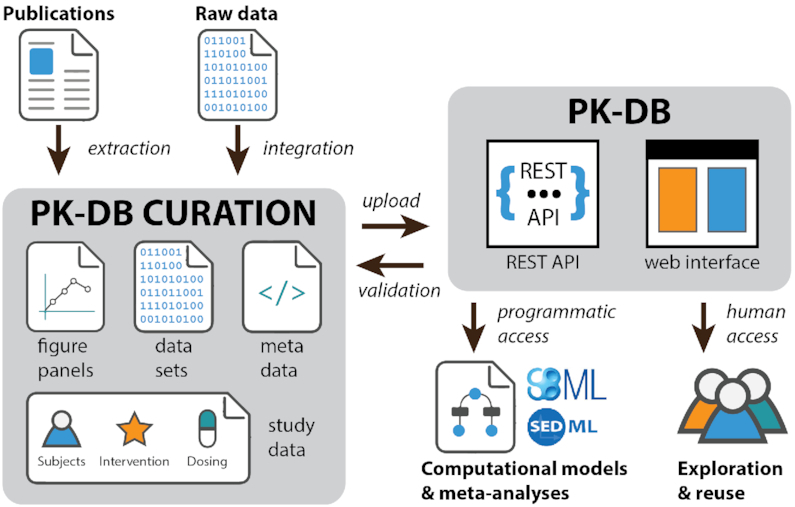
PK-DB overview. Schematic overview of the curation process and interaction with the PK-DB database. Data is either extracted from literature (digitization of figures and tables) or data sets are directly imported (from collaboration partners). Figure panels, data sets, meta-data and study information on subjects, interventions and dosing is curated. All data files and the study information are uploaded via REST endpoints. The curated data is checked against validation rules, data is normalized (e.g. units), and pharmacokinetic parameters are calculated. The uploaded study information can either be programmatically accessed via the REST API or via the web frontend.