
Figure 2:
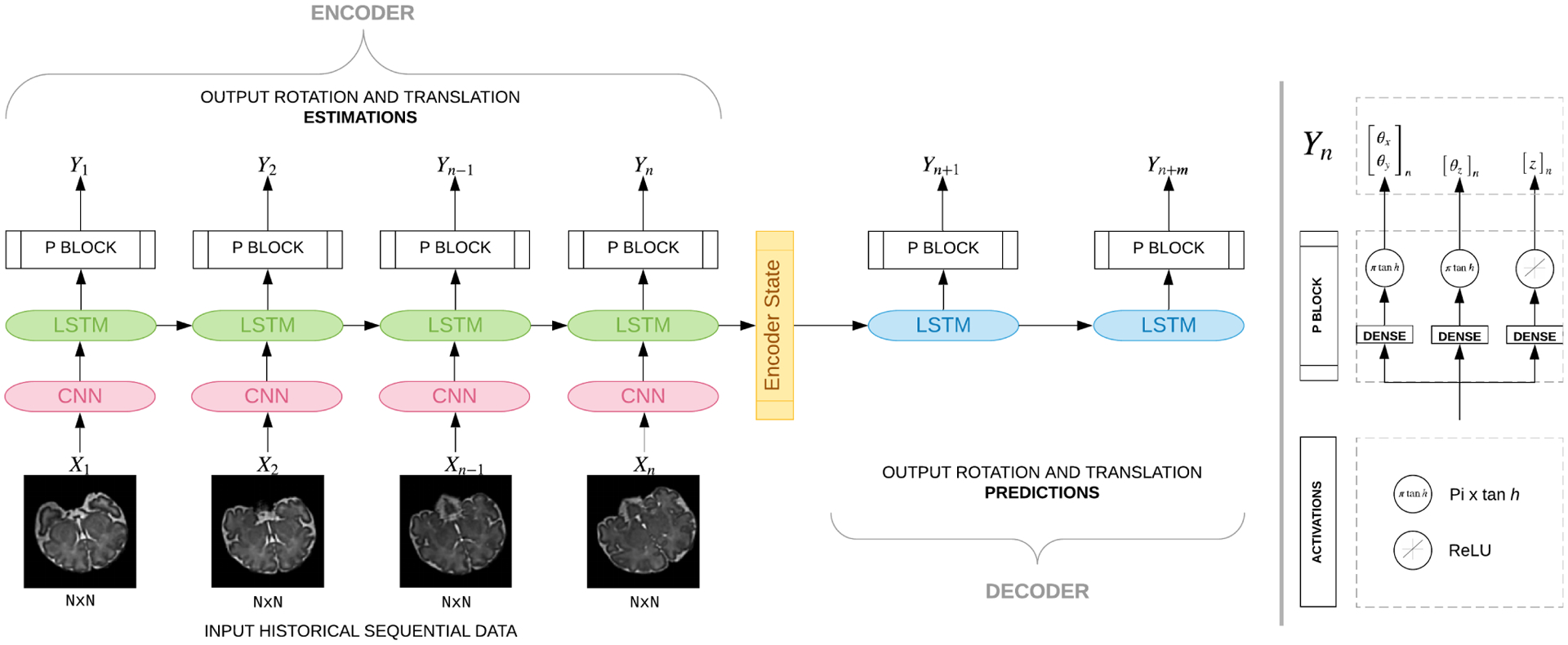
Our many-to-many Seq2Seq model that takes as input sequence of slices and estimates angles as well as predictions. Multiple LSTM units are shown since we unroll our network. All units of the same type and color share weights, hence they get the same gradient update during training. This model comprises of an encoder and a decoder component. The encoder, which contains spatial encoder (CNN) blocks followed by a temporal encoder that contains LSTM units and P blocks, encodes and learns sequence-of-image features to estimate position parameters. The encoder state is fed into the decoder network which comprises of LSTM units followed by P blocks. Each P block has three heads with πtanh activation for the rotation parameters and ReLU activation for the slice position.