
Figure 3.
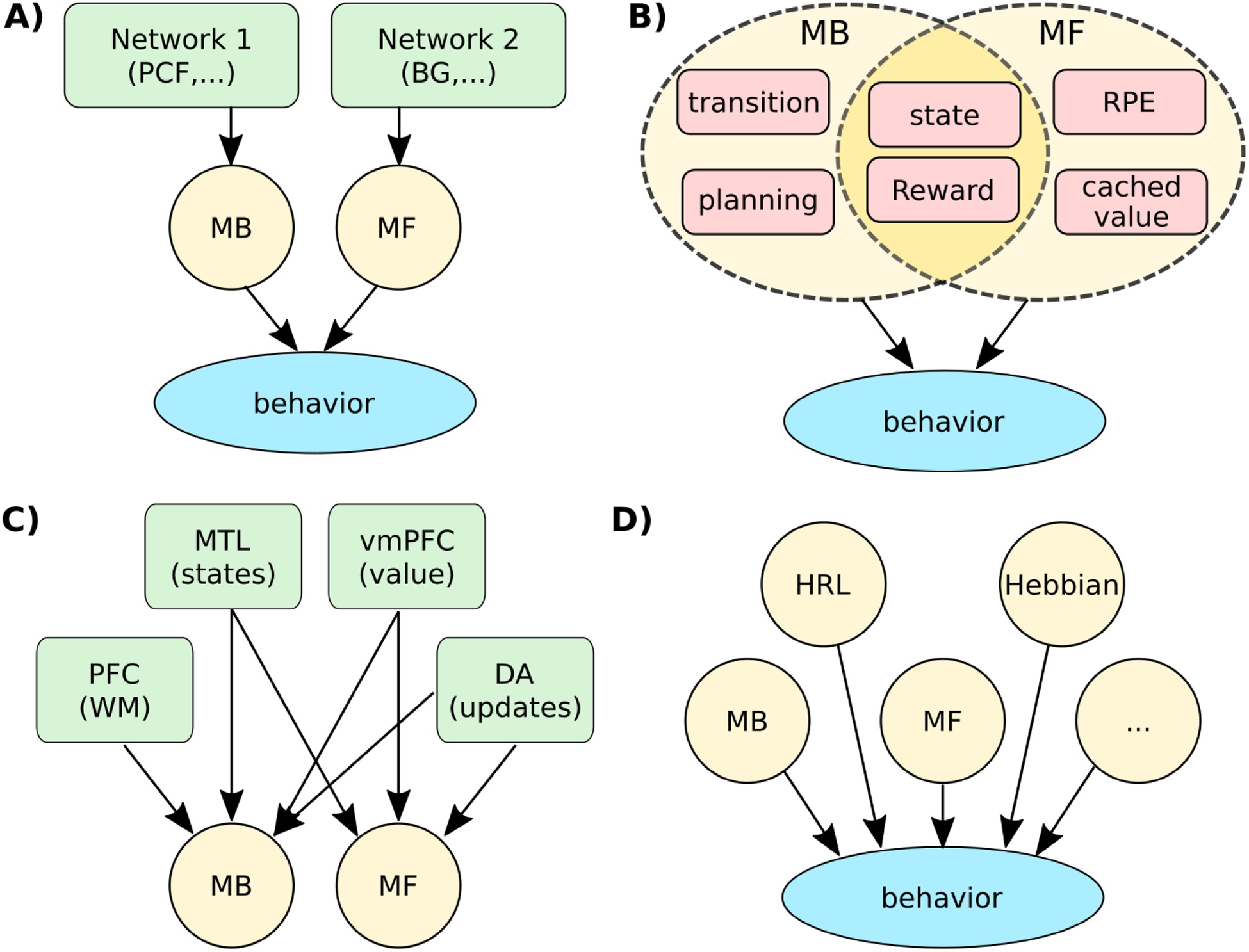
Decompositions of learning. A. Classic interpretations of the MB-MF RL theory cast the space of learning behavior as a mixture of two components, with MB and MF as independent primitives implemented in separable neural networks (green). B) In reality, MB and MF are not independent computational dimensions, and rely on multiple partially shared computational primitives (red). For example, MB planning depends on learned transitions, which in turn, relies on state representations that may be shared across MB/MF strategies. C) MB and MF’s computations do not map on to unique underlying mechanisms. For example, MB learning may rely on prefrontal (PFC) working memory to compute forward plans, medial temporal lobe (MTL) to represent states and transition, and ventro-medial (vm) PFC to represent reward expectations. MF also relies on the latter two, as well as other specific networks, non-exhaustively represented here. D) Additional independent computational dimensions are needed to account for the space of learning algorithm behaviors, such as hierarchical task decomposition (HRL) or hebbian learning.