
Figure 3. Mathematical model of T cell reconstitution after hematopoietic stem and progenitor cell (HSPC) transplantation.
(A) Schematics of the model. Each circle represents a cell compartment: T represents the HSPCs from the transplant; P, the progenitor cells in bone marrow (BM) and thymus; S and N, CD4+CCR5+ and CD4+CCR5- T cells, respectively; Tp, the protected (ΔCCR5), gene-modified cells from transplant; Pp, protected (ΔCCR5) progenitor cells in BM/thymus; Np1 and Np2 the protected (ΔCCR5) CD4+ T cells; M the CD8+ T cells with naive and central memory phenotype and E CD8+ T cells with effector memory phenotype. The initial fraction of protected cells in the product is represented by the parameter fp. Gray panels represent mature blood CD4+ and CD8+ T cells, and the green panel all ΔCCR5 cells in the model. Red, dashed arrows represent discarded terms after model selection and validation (see text for details). (B) Model predictions using the maximum likelihood estimation of the population parameters (solid black lines) for all blood T cell subsets before ATI for all animals in the transplant groups using model with ΔAIC = 0 (Figure 3—source datas 2–3). Each gray line is one animal. (C) Model predictions of the total concentration of CD4+CCR5- T cells generated by CCR5 downregulation (dashed line) or thymic export (solid line), and of the total concentration of CD4+CCR5+ T cells generated by proliferation (solid line) or by upregulation of CCR5 (dashed line) over time using the maximum likelihood estimation of the population parameters.

Figure 3—figure supplement 1. Individual fits of the best model to the blood T cell observations pre-ATI in control group from a time relative to post-transplantation in transplant groups.
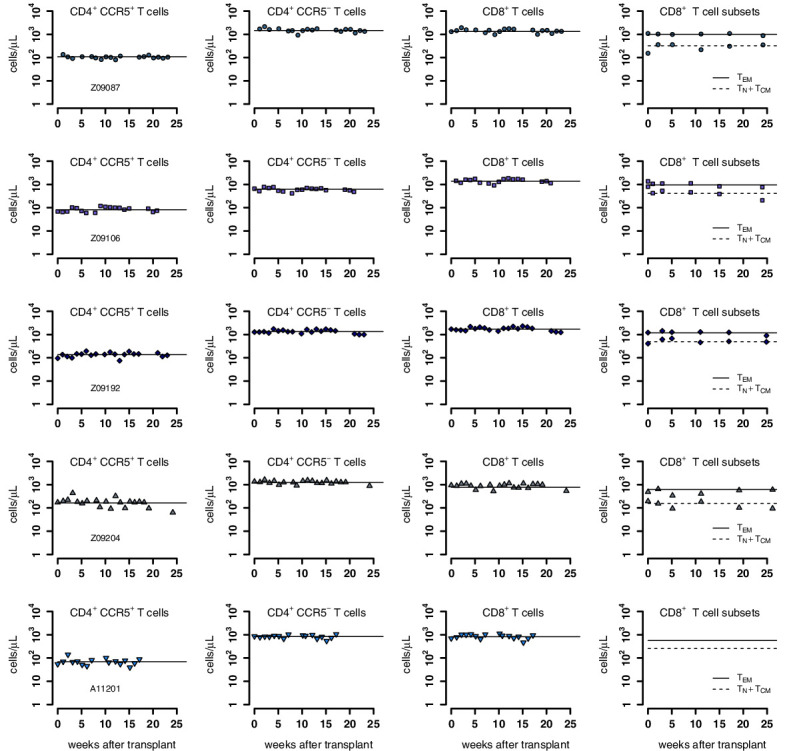
Figure 3—figure supplement 2. Individual fits of the best model to the blood T cell observations post-transplantation, pre-ATI for the wild-type-transplant group.
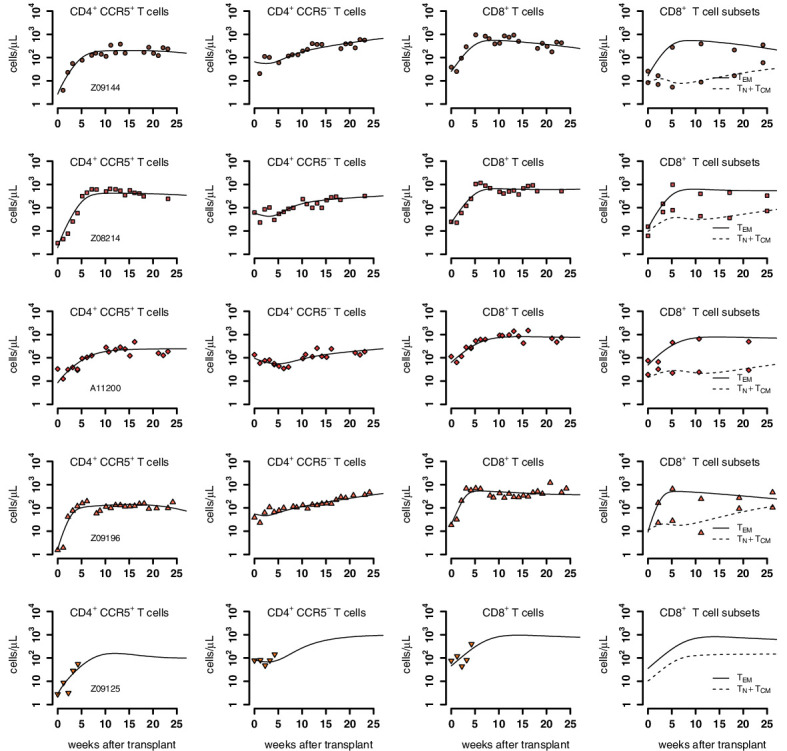
Figure 3—figure supplement 3. Individual fits of the best model to the blood T cell observations post-transplantation, pre-ATI for the ΔCCR5-transplant group.

Figure 3—figure supplement 4. Predictions of the best model for the contributors to cell expansion in CD8+ TEM cells in animals from the transplant groups.
