
Fig. 4.
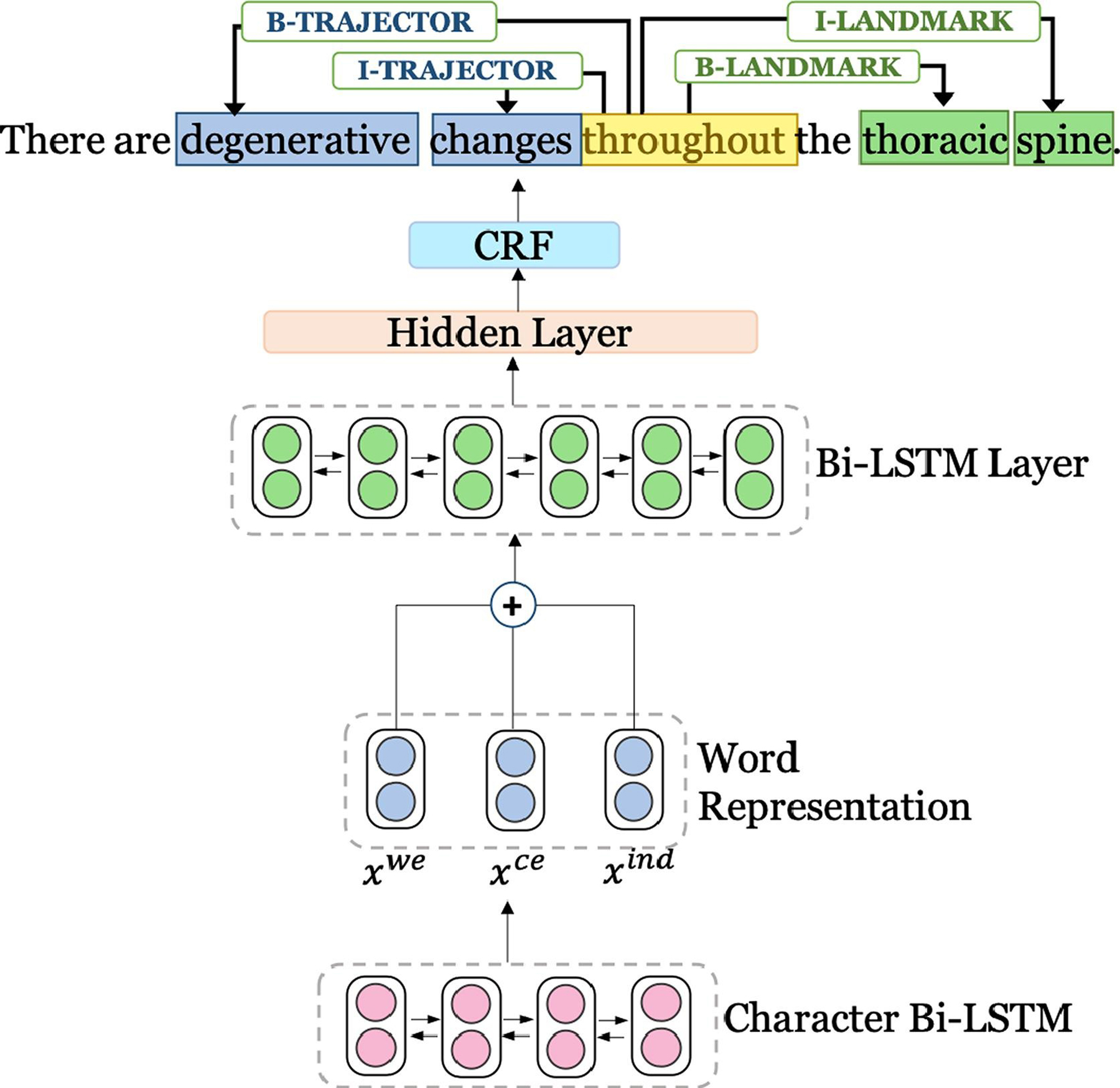
Baseline model architecture. For each word, a character representation is fed into the input layer of the Bi-LSTM network. For each word, xwe represents pre-trained word embeddings, xce represents character embeddings, and xind represents indicator embeddings. The final predictions for the spatial role labels in a sentence are made combining the Bi-LSTM’s final score and CRF score.