
Figure 8.
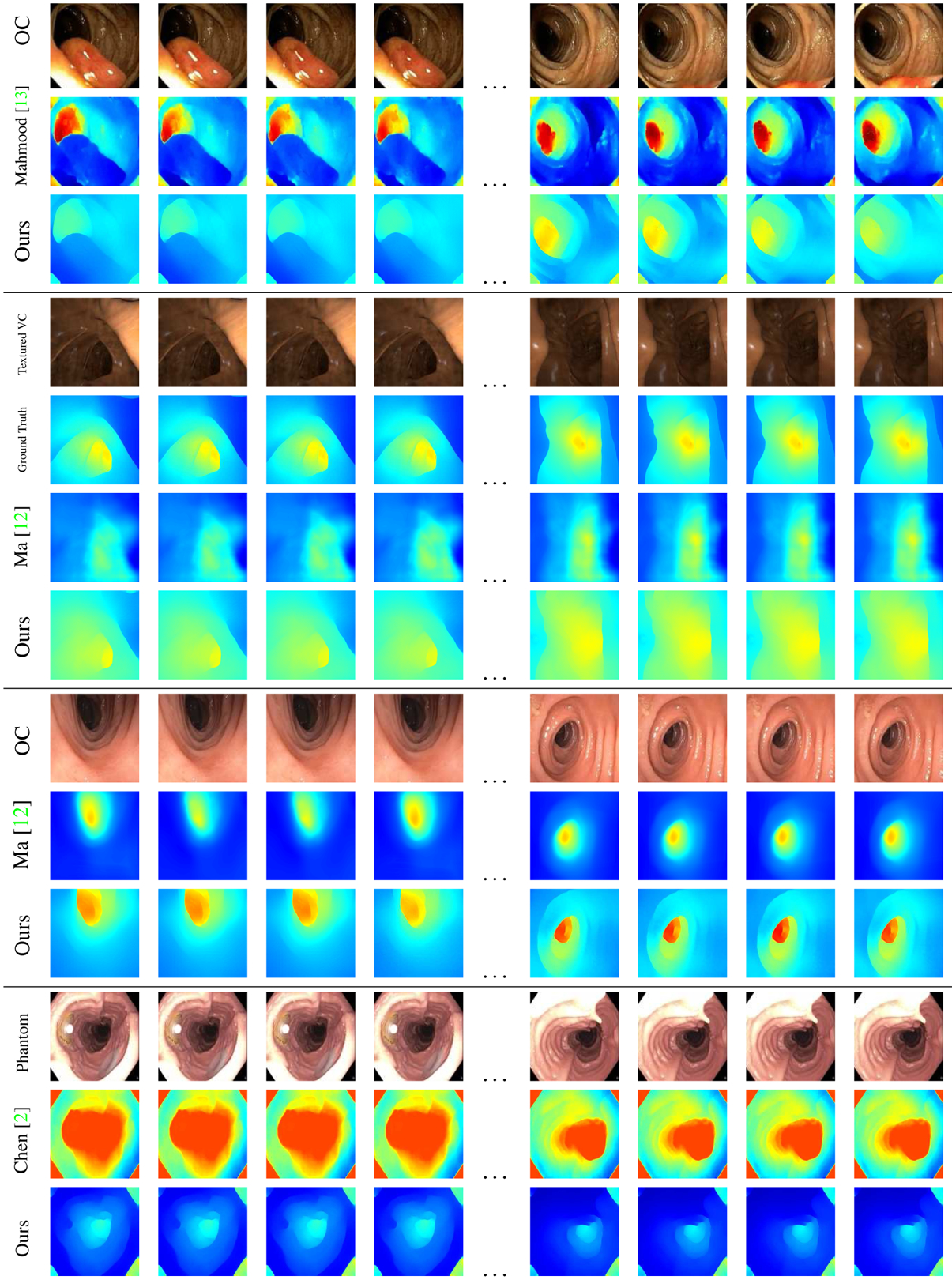
Scale-consistent depth inference on video sequences. The first (top) dataset contains a polyp video sequence with Mahmood et al.’s [13] and our results. The second dataset is successive frames from our textured VC video flythrough and the corresponding results from Ma et al. [12] and ours. The SSIM for Ma et al.’s approach is 0.637, whereas ours is 0.918. Ma et al. assume as input a chunk of successive video frames with cylindrical topology (endoluminal) view with the specular reflections and occlusions masked out. The third dataset show another sequence assuming Ma et al.’s input [12] and our corresponding results. The final dataset, shows Chen et al.’s phantom model [2] along with their results and our results. Complete videos and additional sequences are shown in the supplementary material.