
Figure 3.
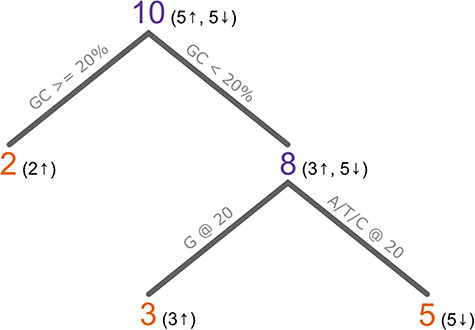
A hypothetical example of a decision tree trained on 10 samples. The first split is on an sgRNA GC content > or <20%, which separates out two samples with a GC content >20%. As both samples are ‘high efficiency’, it results in a pure node (orange). Of the eight sgRNAs with a GC content >20%, three have a high efficiency and five have a low efficiency, so this node is impure (purple). The next split is on the presence (or absence) of a G at position 20 in the sgRNA. All three sgRNAs with a G have a high efficiency and all five sgRNAs without a G have a low efficiency. The resulting nodes are pure, so training concludes. This model would classify new sgRNAs as high if ‘the GC content is >= than 20%’ or ‘the GC content is < 20% and there is a G at position 20’. In reality, such a model would be much more complex with purity not being reached so early, or possibly not at all.