

Abstract
Emotion states recognition using wireless signals is an emerging area of research that has an impact on neuroscientific studies of human behaviour and well-being monitoring. Currently, standoff emotion detection is mostly reliant on the analysis of facial expressions and/or eye movements acquired from optical or video cameras. Meanwhile, although they have been widely accepted for recognizing human emotions from the multimodal data, machine learning approaches have been mostly restricted to subject dependent analyses which lack of generality. In this paper, we report an experimental study which collects heartbeat and breathing signals of 15 participants from radio frequency (RF) reflections off the body followed by novel noise filtering techniques. We propose a novel deep neural network (DNN) architecture based on the fusion of raw RF data and the processed RF signal for classifying and visualising various emotion states. The proposed model achieves high classification accuracy of 71.67% for independent subjects with 0.71, 0.72 and 0.71 precision, recall and F1-score values respectively. We have compared our results with those obtained from five different classical ML algorithms and it is established that deep learning offers a superior performance even with limited amount of raw RF and post processed time-sequence data. The deep learning model has also been validated by comparing our results with those from ECG signals. Our results indicate that using wireless signals for stand-by emotion state detection is a better alternative to other technologies with high accuracy and have much wider applications in future studies of behavioural sciences.
Introduction
With the advancements in body-centric wireless systems, physiological monitoring has been revolutionized for improving healthcare and wellbeing of people [1–6]. These systems predominantly rely on wireless intelligent sensors that are capable of retrieving clinical information from physiological signals to interpret the progression of various ailments. A traditional sensing system can amass and process a wide range of biological signals, including electrophysiological (electroencephalogram (EEG), electrocardiogram (ECG)) [7, 8] and physiological information [9, 10], that are incessantly emanating from the human body. Apart from diagnostic and therapeutic aspects, wireless sensors have demonstrated their applications for recognizing emotions that can be extracted from a measured physiological data [11–13]. Emotions are indispensable facet of humans and can affect their physiological status during office work, travelling, decision making, entertainment and many others activities [14, 15]. The human health and work productivity are highly reliant on the intensity of emotions that can be either positive or negative. The positive emotions can help to achieve optimal well being and mental strength, whereas long term negative emotions may result in predisposing cause of chronic mental health problems, such as depression and anxiety. Furthermore, people who are experiencing frequent negative emotional states have a weaker immune response as compared to people with positive affective style [16]. The above mentioned aspects of emotions have led to further investigations in real life scenarios.
Due to the impact of aforementioned applications in our daily course of life, extensive amount of strategies have been exploited for emotion detection that primarily focus on audio [17], visual [17–19], facial [20], speech [21] and body gestures [22]. Notably, emotion recognition by statistical analysis of physiological signals (ECG, EEG, wearable sensors, etc.) has been the emerging research topic in the recent years [15, 23, 24].
While conventional machine learning (ML) algorithms have already performed optimally for emotion classification, especially under the constraint of subject dependency [25, 26], latest research is heading further to explor applications of deep learning [27, 28]. One key advantage of deep learning models over ML algorithms is the elimination of tedious extraction of hand-crafted features which is taken care by the neural network itself. In literature, a deep neural network consisting of long short-term memory (LSTM) and convolutional layers is proposed to detect emotion states from physiological, environmental and location sensor data with excellent performance in subject dependent regime [29].
A similar architecture is deployed in [30] for end-to-end learning of emotions with consistent accuracy. Unsupervised deep belief networks have also been used to extract in-depth features of physiological signals from three different sensors and classified with Fine Gaussian Support Vector Machine (FGSVM) [31]. The WiFi based emotion sensing platform, such as EmoSense has been developed to capture physical body gestures and expressions by analysing the signal shadowing and multi-path effects with traditional machine learning algorithms. However, a maximum classification accuracy of only 40% for subject independent case [22] was achieved. Moreover, in contrary to a detection scheme that relies directly on heart-beat or brain signals, the WiFi based emotion sensing can be misguided by intentional false acting of body gestures or non-expressive behaviour. Several novel deep learning architectures have been proposed for the time series data processing such as gene expression classification and clustering [32].
These approaches vary from simple multi-layer feed forward neural networks [33, 34] to more complex frameworks, such as LSTM based deepMirGene [35], recurrent neural network (RNN), autoencoder based DeepTarget [36] and fDNN. These approaches incorporate a random forest model as a feature learner from raw gene inputs and a fully-connected neural network as a classification learner [37]. Whereas, deep belief network coupled with autoencoder are employed for learning low dimensional representations of gene expressions, enabling unsupervised clustering [38]. Thus, there is an ample opportunity to reliably address the challenging task of subject independent emotion detection based on wireless signals with a carefully tapped deep learning architecture.
The recent progress in wearable electronic sensors have enabled collection of physiological data, such as heart rate, respiration rate and electroencephalography (EEG) for several physical manifestations of emotions. However, wearable sensors and devices are cumbersome during routine activities and can lead to false judgement in recognizing people’s true emotions. In [11], a wireless system is demonstrated that can measure minute variations of a person’s heartbeat and breathing rate in response to the individually prepared stimuli (memories, photos, music and videos) that evoke a certain emotion during experiment. Most of the participants in the study were actors and experienced in evoking emotions. The RF reflections off the body are preprocessed and fed to machine learning (ML) algorithms to classify four basic emotions types, such as anger, sadness, joy and pleasure. The proposed system excludes the requirements of carrying on-body sensors for emotion detection. Nevertheless, emotions were classified only using conventional ML algorithms and the quest to investigate the competence of deep learning for wireless signals classification has become an exciting research area.
This paper focuses on exploring deep neural networks for affective emotion detection in comparison to traditional ML algorithms. A framework is developed for recognizing human emotions using a wireless system without bulky wearable sensors, making it truly non-intrusive, and directly applicable in future smart home/building environments. An experimental database containing the heartbeat and breathing signals of 15 subjects was created by extracting the radio frequency (RF) reflections off the body followed by noise filtering techniques. The RF based emotion sensing systems (Fig 1) can overcome the limitations of traditional body worn devices that can encounter limited range of sensing and also cause inconvenience to people. For eliciting particular emotion in the participant, four videos have been selected from an on-line video platform. Videos were not shown to the participants before the start of experiment. Thus, our approach of evoking emotions in the participants is distinguishable from [11], in which each participant has to prepare their own stimuli (after watching photos, reminding personal memories, music, videos) before the start of the experiment and act the intended emotion during the experiment. A novel convolutional neural network (CNN) architecture integrated with long short-term memory (LSTM) sequence learning cells that leverage’s both the processed RF signal and raw RF reflection is utilized for the classification.
Fig 1. Emotion detection process in which each participant is asked to watch emotion evoking videos on the monitor while being exposed with radio waves.
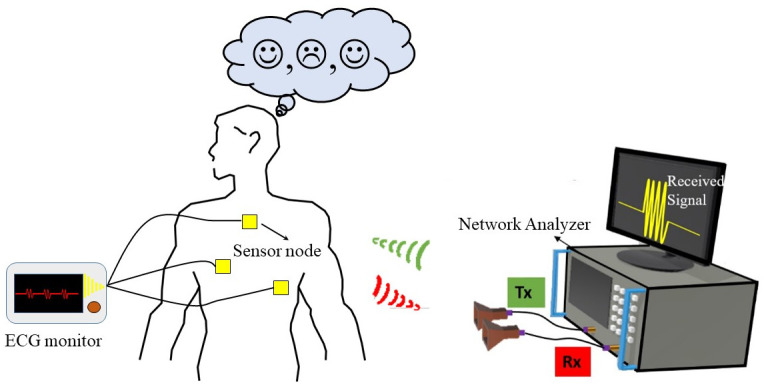
The Tx antenna is used to transmit RF signals towards the participant, whereas Rx antenna is used to receive RF reflections off the body. The ECG monitor is also connected to a participant’s chest for recording heart beats. The data received from ECG is used to correlate heart beats variations with emotion evoking videos.
The proposed network achieves state-of-the-art classification accuracy in comparison to five different traditional ML algorithms. On the other hand, a similar architecture is used for emotion recognition using the ECG signals. Our results indicate that deep learning is capable of utilizing a range of building blocks to learn from the RF reflections off the body for precise emotion detection and excludes manual feature extraction techniques. Furthermore, we propose that RF reflections can be an exceptional alternative to ECG or bulky wearables for subject-independent human emotion detection with high and comparable accuracy.
Results
Detection of emotional states
Deep learning analysis
Feature extraction is an integral part of a signal (electromagntic, acoustic, etc.) classification that can be performed manually or by using a neural network. Deploying traditional machine learning algorithms for signal classification necessitates ponderous extraction of statistical parameters from the raw data input. However, this manual approach can be tedious and may result in omission of some useful features. In contrary, deep neural networks can extract enormous amount of features from the raw data itself, whether they are significant or of minute details [39]. Therefore, we employ an appropriate DNN architecture to process the time domain wireless signal (RF reflections off the body) and the corresponding frequency domain version obtained by continuous wavelet (CW) transformation. Here, the RF reflection signal is one-dimensional (1D) and the CW transformation is an image of three dimensions (3D), represented in the format of (width, height and channels). The parameters in wavelet image can be regarded as time (x-axis), frequency(y-axis), and the amplitude. The proposed DL architecture that is shown in Fig 2 could be identified as a ‘Y’ shaped neural network that accepts inputs in two distinct forms and fuses the processed inputs at the end to produce classification probabilities related to four emotions. The neural network consists of two sets of convolutional 1D and maxpooling 1D layers, followed by a long short-term memory (LSTM) cell to capture the features and time dependency of the time domain RF signal. Another two sets of convolutional 2D and maxpooling 2D layers are used to process CW transformed image.
Fig 2. Proposed deep neural network architecture for emotion classification.

Time domain RF signal is processed through two convolutional-1D layers and an additional LSTM cell that captures the time dependency (section 1 in S1 File). The CW transformation is processed by two convolutional-2D layers (section 2.1 in S1 File). Each feature map in convolutional layers represents a unique extracted feature from the layer input. The features extracted from two distinct inputs of the model are then concatenated, leading to a broad learning capability. The detailed visualization of 32 and 64 features maps is presented in section 2.2 of S1 File.
The convolutional layers are exceptional feature extractors and often outperform humans in this regard. A convolutional layer may have many kernels in the form of matrices (e.g. 3 × 3 and 5 × 5) that embed numerical values to capture variety of different features (e.g. brightness, darkness, blurring, edges, etc., of an image) from raw data. A kernel runs through the input data as a sliding window, and at every distinct location, it performs element-wise multiplication with the overlapping input data and takes the summation to obtain the value of that particular location of the generated feature map. Maxpooling layers do not involve in feature extraction. However, they reduce the dimensions of the outputs of convolutional layers, hence reducing the computational complexity. A typical convolutional layer has 32, 64 or even 128 kernels and thus results in the same number of feature maps. As observed in Fig 2, the feature maps carry even the diminutive information available in the input image, whereas a human eye is unable to capture this level of information, making them ordinary feature extractors.
The accuracy of classification is evaluated with leave-one-out cross validation (LOOCV) [40]. Although, cross validation is immensely used with ML models to observe the generalizability of the model, it is somewhat unconventional to perform cross validation with deep learning due to; (1) extreme computational complexity and (2) difficulty in tracking overfitting/underfitting conditions with a fixed number of iterations while training the model. However, in order to make a fair judgement on our DL predictions, we first used the full database and performed LOOCV, despite being the most computational intensive form of K-fold cross validation. In K-fold cross validation, the database is split into k subsets, out of which, one is kept as the test set and the other k − 1 are put together to form the training set. This process is repeated k times such that every data point gets to be in the test set exactly once, eliminating the effect of biased data division into train and test sets. LOOCV is achieved by making the value of k equal to N, number of data points in the database.
The proposed DL model yielded in 71.67% LOOCV accuracy. This is quite a high percentage, considering the fact that human emotions are highly dependent on the level of stimulation generated in their brains by the same audio-video stimuli, capable of inducing emotions intensity differently from one person to another. It is tempting to conclude that the performance of model is solely based on the classification accuracy. However, a model with a high classification accuracy can still perform suboptimally, especially when the database is unbalanced as some classes contain a high number of data points and the others do not. In order to have a better description of the model, we often adopt other performance metrics such as precision, recall and F1-score. Precision indicates how many selected instances are relevant (a measure of quality), whereas recall indicates how many relevant instances are selected (a measure of quantity). F1-score reveals the trade-off between precision and recall, and can be correlated with effective resistance of the two parallel resistors (precision and recall) in a closed loop circuit. F1-score becomes low if either of these figures is low in comparison to the other, thus illustrating the reliability of the model across all classes. Although, these parameters are defined for binary classification, they can be extended to multi-class problems by calculating inter-class mean and standard deviation. The calculated values of precision, recall and F1-score after LOOCV are 0.713, 0.716 and 0.714 respectively, implying that the model has achieved good generalizability.
Machine Learning (ML) analysis
We have employed traditional ML algorithms process by means of data pre-processing, feature extraction, model training and classifications (section 3, S5 Fig in S1 File). In our experiment, the RF reflected signals off the body encompass human body movements and random noise that is mostly contributed from the environment, equipments (VNA, cables, etc,…) and other moving objects. For this reason, it is essential to filter the noise from received RF signals for further processing. Moreover, we have also implemented data normalization technique to circumvent the influence of intensity variations on body movement for each participant.
Feature extraction process can be regarded as a core step of ML algorithms to analyse data. Considering the importance of ML for feature extraction, an efficient algorithm can significantly improve the classification accuracy while reducing the impact of interfering redundant RF signals and random noise. In the literature, a variety of feature extraction parameters are studied that are mostly in the field of affective recognition and biological engineering [41–43]. Permutation entropy is a widely used nonlinear parameter to evaluate the complexity of sequence that is a prevalent approach to estimate the pattern of biological signals, such as Electrocardiogram (ECG) and electroencephalogram (EEG). It is also capable of detecting real-time dynamic characteristics, and also has strong robustness.
Apart from the entropy value, it is well documented that the power spectral density (PSD) and statistical (variance, skewness, kurtosis) parameters are also related to the affective state of participants [44]. In our analysis, the permutation entropy, PSD in the range of 0.15–2 Hz, 2–4 Hz and 4–8 Hz, and the variance, skewness and kurtosis values are extracted from the pre-processed signals. Therefore, overall seven parameters are tapped in the feature extraction process (section 3, S5 Fig in S1 File).
Analysis of deep learning and machine learning results
The confusion matrices obtained using LOOCV for CNN+LSTM model and five classical ML algorithms are depicted in Fig 3. As tabulated in Table 1, deep learning outperforms conventional machine learning algorithms in all performance metrics. We identify two main reasons that explain why deep learning is superior in the current learning problem. First, having both the time domain wireless signal and CW transformed image as an input is a rich source of learning for the CNN+LSTM model whereas the ML algorithms are trained with extracted features as inputs, that are sensitive to the level of human judgement on selecting features as well as the obvious loss of information from the original data. Second, CNNs are self learners that learn even the diminutive information, hidden in raw data that aids to reconstruct its target values, given the correct hyper-parameters. ML algorithms are somewhat reliant on human to figure out meaningful statistical parameters (or a combination of parameters) from raw data to be fed to the model. Nevertheless, these ML models still report an acceptable performance that can be used as a criterion for measuring how well the implemented DL model can perform.
Fig 3. Confusion matrices obtained by LOOCV for DL and ML models.

Table 1. ML vs DL results comparison based on average performance metrics.
The metric ‘Accuracy’ refers to LOOCV accuracy.
| Accuracy (%) | Precision | Recall | F1-score | |
|---|---|---|---|---|
| CNN + LSTM | 71.67 | 0.713 (±0.08) | 0.716 (±0.12) | 0.714 (±0.10) |
| Random forest | 63.33 | 0.646 (±0.27) | 0.633 (±0.29) | 0.634 (±0.18) |
| SVM | 63.33 | 0.645 (±0.17) | 0.63 (±0.04) | 0.637 (±0.08) |
| KNN | 61.7 | 0.64 (±0.21) | 0.616 (±0.18) | 0.615 (±0.19) |
| Decision tree | 55.0 | 0.554 (±0.30) | 0.549 (±0.23) | 0.55 (±0.14) |
| LDA | 51.7 | 0.544 (±0.36) | 0.516 (±0.27) | 0.526 (±0.28) |
Data visualization
Data visualization is pivotal for basic identification of patterns and trends in data that helps to understand and elaborate the results obtained from the machine learning models. However, high dimensional data as obtained by feature extraction, needs to be compressed into a lower dimension for visualization. T-distributed stochastic neighbour embedding (t-SNE) is a nonlinear dimensionality reduction machine learning algorithm often used for visualising high dimensional data by projecting it onto a 2D or 3D space (section 4 in S1 File). Fig 4 shows the t-SNE plots of RF and ECG databases, representing all 15 subjects. Fig 4a supports ML classification results for RF signals as the emotions ‘Relax’ and ‘Disgust’ are rather easily separable from the rest of emotions. The self assessment scaling acquired from the subjects after participating in the experiment also complement our findings as most of them stated that the video stimuli of ‘Relax’ and ‘Disgust’ really evoked the calmness and disgust emotions respectively (section 5, S6 Fig in S1 File).
Fig 4. t-SNE plots representing the full RF and ECG databases.
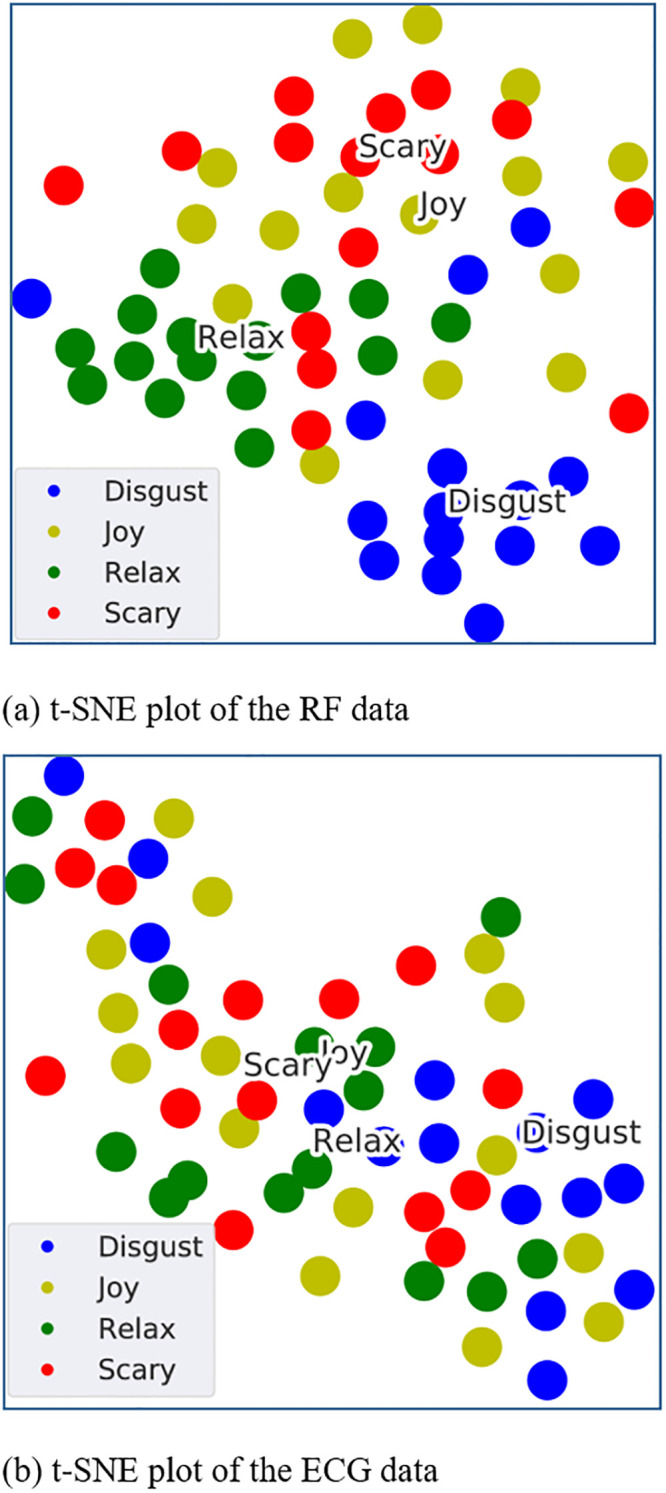
The plots were obtained by reducing the dimensions of the continuous wavelet images of each signal. It can be observed that the wavelet images of RF signals (panel (a)) demonstrate a better separability between emotions than that of ECG signals (panel (b)).
Discussion
It is understood that the emotions evoked by the audio-visual stimuli are highly subject dependent and therefore difficult to classify on a common ground. Due to this reason, it is essential to assess the capability of models to distinguish between classes. A receiver operating characteristic (ROC) curve is a probability curve obtained by plotting sensitivity against (1-specificity). Area under the curve (AUC) represents the degree of separability. ROC is defined for a binary classifier system, however, can be extended for a multiclass classification by building a single classifier per class, known as one-vs.-rest or one-against-all strategy. ROC curve and AUC for each class obtained using the SVM model are illustrated in Fig 5. AUCs indicate that the emotions ‘Disgust’ and ‘Relax’ have a higher degree of separability, complying well with the DL and ML classification results. It should be noted that four video stimuli of respective emotions were displayed to the subjects with minimum delay between the videos and hence it is possible for evoked emotions in the preceding video to persist in the initial part of the following video before it completely vanishes.
Fig 5. ROC-AUC representing the degree of separability between classes.

The emotions ‘Disgust’ and ‘Relax’ are highly separable from the rest. Micro-average aggregates the contribution from all classes to compute the average ROC curve. Macro-average computes the ROC metric for each class independently and takes the average, hence treating all classes equally.
We have used CNN+LSTM model to predict the variations of emotion probabilities across all the videos for a randomly selected subject from the test set. Fig 6 depicts the probability variation of emotions over the time and mean probabilities.
Fig 6. Variations of probability of different emotions over time, predicted for a randomly selected subject from the test set.

Smooth probability curves are generated by interpolating the discrete probability values.
RF vs ECG performance comparison
Human clinical conditions, either physical or mental, cause subtle variations in heart rate that is also reflected in the ECG signal. Therefore, the existing health condition monitoring systems predominantly depend on ECG data for discovering the underlying reasons and categorizing the conditions. In order to make a comparison with RF results, we utilize simultaneously extracted the ECG signal data to train a similar DNN architecture as shown in Fig 2. Likewise, the Wavelet Transformation is applied to ECG data (Fig 7a). As observed in the Fig 4b, CW transformation alone is not enough to distinguish between emotions. Therefore, we calculated 81 features from the ECG signal, known as inter beat interval (IBI) features and further applied minimum redundancy maximum relevance (mRmR) feature selection [45] method to reduce the dimensions, resulting in 30 features. Since the features do not form a time sequence, we have omitted the LSTM cell from the DL architecture. The extracted features and the CW transformations are used to train the CNN model for emotion recognition. To identify the threshold performance, we have trained a SVM model with the extracted 30 features. Table 2 demonstrates the performance metrics in ECG classification. The confusion matrices of CNN and SVM models are shown in Fig 7b and 7c respectively. In general, the deep learning classification performances of RF and ECG (Fig 7) are high and very similar (both having 71.67% LOOCV accuracy), indicating that RF signals can describe the underlying emotion of a person as good as an ECG signal with added benefits of being wireless and more practical. Furthermore, we tested the performance of the proposed deep learning architecture on the well established DREAMER ECG database [41] for emotion recognition. The model achieved 68.48% subject independent LOOCV classification accuracy with 0.678, 0.685, 0.680 precision, recall and F1-score values respectively (section 6 in S1 File). Thus, it is evident that the proposed novel DL architecture can be employed across different databases generated under diverse conditions.
Fig 7. CW transformed ECG inputs fed to the CNN model and the confusion matrices representing the ECG classification performances of CNN and SVM ML models.
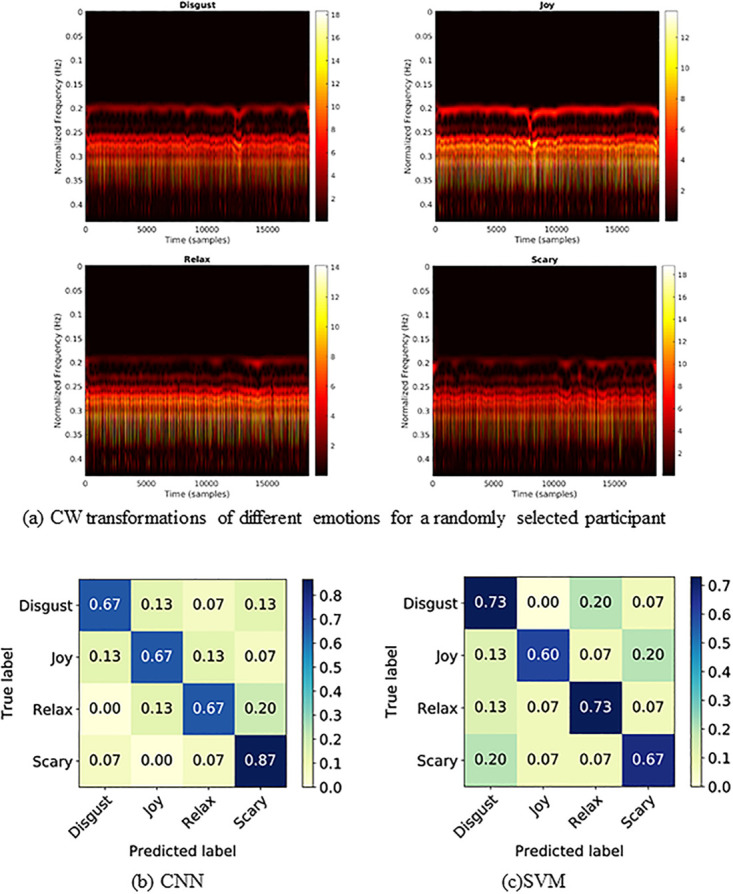
Table 2. ML vs DL results comparison for ECG classification.
The metric ‘Accuracy’ refers to LOOCV accuracy.
| Accuracy (%) | Precision | Recall | F1-score | |
|---|---|---|---|---|
| CNN | 71.67 | 0.720 (±0.03) | 0.716 (±0.09) | 0.714 (±0.03) |
| SVM | 68.33 | 0.692 (±0.07) | 0.68 (±0.05) | 0.681 (±0.02) |
Experimental study and data processing
Ethical approval
All experimental study was approved by Queen Mary Ethics of Research Committee of Queen Mary University of London under QMERC2019/25. All research was performed in accordance with guidelines/regulations approved by Ethics of Research Committee. Written informed consent was obtained from the participants involved in the study.
Participants
The experiment was performed on 15 participants. All participants were English speaking, aged between 22—35 years. The participants were briefly explained about the measurement details before the start of the experiment. They were provided with comfortable environment so that they can only focus on watching videos with minimum distractions.
Stimuli: Emotions evoking videos
For inducing emotions in the participants, individual videos were selected that can induce four emotional states (relax, scary, disgust, and joy) in the participants (section 7, S8 Fig in S1 File). The duration of each video clip was from 3—4 minutes. A survey was prepared and provided to the participants, where the emotions can be mapped and graded according to the intensity of emotions felt during the experiment [46]. Participants were asked to record the intensity of emotions in the survey after watching each video. Self assessment results indicated that videos are capable of inducing a particular emotion in the participant during the experiment (section 5, S6 Fig in S1 File). However, it is also observed that some participants have experienced multiple emotions while watching a single video. For instance, while watching video corresponding to the happy emotions, participants indicated on the survey that they didn’t find the video content happy enough and they remained relax while watching the video. This implies that emotion detection require complex procedure to distinguish emotions of a participant.
Emotion detection experiment
Measurement set-up
Measurements were performed in the anechoic chamber to reduce any interfering noise emanating from external environment that might alter the emotions of a participant during experiment (section 8, S11 Fig in S1 File). A pair of Vivaldi type antennas is used to form the radar, operating at 5.8 GHz (section 8, S10 Fig in S1 File). One antenna is used for RF signal transmission towards the body (Green Signal, Fig 1), while the second antenna was used for receiving RF reflections off the body (Red Signal, Fig 1). A pair of coaxial cables were used to connect both antennas to the programmable vector network analyzer (Rohde & Schwarz, N5230 C) through coaxial cables. A laptop was used to play videos and the participants were asked to wear headphones so that they can effectively focus on the audio. The distance between the antennas and the participants was 30 cm as illustrated in the measurement set-up (S2 Fig in S1 File).
Detection of RF reflections from the participants
The videos were shown one at a time to the participant who was sitting on the chair in-front of the displaying monitor at a distance of approximately 1 meter. The participants were exposed with RF power level of 0 dBm. After the end of each video, the participant was asked to relax before the start of next video. While each video was playing, RF reflections from the participant’s body were detected through the receiving Vivaldi antenna, that was connected the VNA. In our experiment, the phase difference of RF reflections is captured using radar techniques. We have employed the procedure that can calculate the phase difference between the transmitted and RF reflections off the body. For instance, the transmitted signal is given as:
| (1) |
where ω0 is the frequency of transmitted signal(operating frequency of 5.8 GHz), whereas φ0 is initial phase of the transmitted signal. Distance between the participant and Tx antenna is:
| (2) |
where d is the static distance between the participant and Tx antenna and f(t′) corresponds to the movement of participant’s body. The received signal can be expressed as:
| (3) |
where is the time duration that the transmitting RF signal takes to reach the participant’s body and is the reflection coefficient from the participant. By considering the participant’s body movement can be regarded as quasi-periodic signals, the expression, f(t′) can be transformed as . The extended expression of the received signal is given below:
| (4) |
The phase difference between transmitted signal and received signal is:
| (5) |
Where C0 is a constant. The amplitude of Φ(t′) is proportional to the frequency of VNA ω0 and body movements Ai. We can infer from above mentioned equation that the variations of phase difference corresponds to the participant’s body movement. We have analysed the emotions on the last 120 seconds of each video. This is to make sure that the intensity of emotions will be high by the end of video as compared to the start of every video.
Data acquisition using ECG
The ECG signals have been extensively explored in literature for emotion detection, particularly in the field of affective computing. The emotional states of a person are effectively associated with psychological activities and cognition of humans. In our experiment, we have used an ECG monitor (PC-80B) to extract the heartbeat variations of a participant during experiment. The ECG monitor is convenient to use and has three electrodes that can be mated to the participant’s chest conveniently.
Signal processing analysis
ECG signals, We have employed signal processing techniques on ECG signals to extract the information about heartbeat variation, owning to the elicited emotions in the participants. Generally, the ECG signals occupy bandwidth in the range of 0.5—45 Hz. For this reason, to remove the baseline drift in the ECG signal, re-sampling is applied at the frequency of 154 Hz and a bandpass Butterworth filter is used to perform filtering from 0.5—45 Hz. In the next step, we have used Augsburg Biosignal Toolbox (AuBT) of Matlab to extract statistical features from ECG signals for different emotional states (section 9 in S1 File). The extracted features are essential for further classification of emotions. The classification results indicate audio-visual stimulus successfully evoke discrete emotional states and can be recognized in terms of psychological activities.
RF signals, After pre-processing the raw data (section 3, S5 Fig in S1 File), the next step is to extract feature and transform from processed data. The extracted parameters for ML have been discussed in the previous section, and the transformation based on continuous wavelet transform (CWT) is introduced.
For further classifications, we have used continuous wavelet transform (CWT) to modify 1-D RF signals into 2-D scaleogram. In the field of mathematics, CWT is a formal (i.e., non-numerical) tool that provides a complete representation of a signal and provides the capability to continuously alter the scale parameters of wavelets. Based on CWT, the 1-D RF signals can be transformed into 2-D scaleogram that represents an image format. Although a scaleogram is beneficial for in-depth understanding of the dynamic behaviour of body movements, individual body movements of participants while watching videos can also be distinguished individually. The normalized time series and its Fourier transform sequence are extracted as the 1-D features. The 2-D scaleogram that is stored as an image format can be considered as the 2-D features. In the classification section, the combination between 1-D features and 2-D features is used to classify different emotional states of participants.
Conclusions
Emotion detection has emerged as a paramount area of research in neuroscientific studies as well as in many other strands of well-being, especially for mentally ill elderly people that are susceptible to physiological fatigue and undergo interactive therapy for the treatment. In this study, we have proposed a novel deep learning architecture that fuses time-domain wirelessly received raw data with those from the frequency domain can achieve state-of-the-art emotion detection performance. We have experimentally demonstrated that four different human emotions can be recognized in a subject independent manner with over 71% accuracy, even in a data limited regime. Moreover, our results indicate that deep learning offers superior performance in the present classification task in comparison to five different machine learning algorithms. We further tested the performance of proposed DL architecture on simultaneously extracted ECG data. It was established that wireless RF measurements could be a better alternative to other invasive methods such as ECG and EEG for human emotion detection. We further evaluated the generalizability of our DL model across other databases by validating it on a well established ECG database. We believe the framework proposed in the present study is a low-cost, hassle-free solution for carrying emotion related research and it offers high detection accuracy in comparison with other alternative approaches.
Supporting information
(PDF)
(RAR)
Data Availability
All relevant data are within the paper and Supporting information files.
Funding Statement
This work was supported by IET AF Harvey Research Prize.
References
- 1. Hall PS, Hao Y. Antennas and propagation for body-centric wireless communications. Artech house; 2012. [Google Scholar]
- 2. Munoz MO, Foster R, Hao Y. Exploring Physiological Parameters in Dynamic WBAN Channels. IEEE Transactions on Antennas and Propagation. 2014;62(10):5268–5281. 10.1109/TAP.2014.2342751 [DOI] [Google Scholar]
- 3. Li C, Un K, Mak P, Chen Y, Muñoz-Ferreras J, Yang Z, et al. Overview of Recent Development on Wireless Sensing Circuits and Systems for Healthcare and Biomedical Applications. IEEE Journal on Emerging and Selected Topics in Circuits and Systems. 2018;8(2):165–177. [Google Scholar]
- 4. Dilmaghani RS, Bobarshad H, Ghavami M, Choobkar S, Wolfe C. Wireless Sensor Networks for Monitoring Physiological Signals of Multiple Patients. IEEE Transactions on Biomedical Circuits and Systems. 2011;5(4):347–356. 10.1109/TBCAS.2011.2114661 [DOI] [PubMed] [Google Scholar]
- 5. Wang X, Le D, Cheng H, Xie C. All-IP wireless sensor networks for real-time patient monitoring. Journal of biomedical informatics. 2014;52:406–417. 10.1016/j.jbi.2014.08.002 [DOI] [PubMed] [Google Scholar]
- 6. Dias D, Paulo Silva Cunha J. Wearable health devices—vital sign monitoring, systems and technologies. Sensors. 2018;18(8):2414 10.3390/s18082414 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Jeong JW, Yeo WH, Akhtar A, Norton JJS, Kwack YJ, Li S, et al. Materials and Optimized Designs for Human-Machine Interfaces Via Epidermal Electronics. Advanced Materials. 2013;25(47):6839–6846. 10.1002/adma.201370294 [DOI] [PubMed] [Google Scholar]
- 8. Yilmaz T, Foster R, Hao Y. Detecting vital signs with wearable wireless sensors. Sensors. 2010;10(12):10837–10862. 10.3390/s101210837 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Schwartz G, Tee BCK, Mei J, Appleton AL, Kim DH, Wang H, et al. Flexible polymer transistors with high pressure sensitivity for application in electronic skin and health monitoring. Nature communications. 2013;4:1859 10.1038/ncomms2832 [DOI] [PubMed] [Google Scholar]
- 10. Webb RC, Bonifas AP, Behnaz A, Zhang Y, Yu KJ, Cheng H, et al. Ultrathin conformal devices for precise and continuous thermal characterization of human skin. Nature materials. 2013;12(10):938–944. 10.1038/nmat3755 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Zhao M, Adib F, Katabi D. Emotion recognition using wireless signals. In: Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking; 2016. p. 95–108.
- 12. Hossain MS, Muhammad G. Emotion-Aware Connected Healthcare Big Data Towards 5G. IEEE Internet of Things Journal. 2018;5(4):2399–2406. 10.1109/JIOT.2017.2772959 [DOI] [Google Scholar]
- 13. Chanel G, Rebetez C, Bétrancourt M, Pun T. Emotion Assessment From Physiological Signals for Adaptation of Game Difficulty. IEEE Transactions on Systems, Man, and Cybernetics—Part A: Systems and Humans. 2011;41(6):1052–1063. 10.1109/TSMCA.2011.2116000 [DOI] [Google Scholar]
- 14. Dolan RJ. Emotion, cognition, and behavior. science. 2002;298(5596):1191–1194. 10.1126/science.1076358 [DOI] [PubMed] [Google Scholar]
- 15. Shu L, Xie J, Yang M, Li Z, Li Z, Liao D, et al. A review of emotion recognition using physiological signals. Sensors. 2018;18(7):2074 10.3390/s18072074 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Rosenkranz MA, Jackson DC, Dalton KM, Dolski I, Ryff CD, Singer BH, et al. Affective style and in vivo immune response: Neurobehavioral mechanisms. Proceedings of the National Academy of Sciences. 2003;100(19):11148–11152. 10.1073/pnas.1534743100 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Zeng Z, Pantic M, Roisman GI, Huang TS. A Survey of Affect Recognition Methods: Audio, Visual, and Spontaneous Expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2009;31(1):39–58. 10.1109/TPAMI.2008.52 [DOI] [PubMed] [Google Scholar]
- 18. Kragel PA, Reddan MC, LaBar KS, Wager TD. Emotion schemas are embedded in the human visual system. Science Advances. 2019;5(7). 10.1126/sciadv.aaw4358 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Kahou SE, Bouthillier X, Lamblin P, Gulcehre C, Michalski V, Konda K, et al. Emonets: Multimodal deep learning approaches for emotion recognition in video. Journal on Multimodal User Interfaces. 2016;10(2):99–111. 10.1007/s12193-015-0195-2 [DOI] [Google Scholar]
- 20. Emotion recognition using facial expressions. Procedia Computer Science. 2017;108:1175–1184. 10.1016/j.procs.2017.05.025 [DOI] [Google Scholar]
- 21. El Ayadi M, Kamel MS, Karray F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognition. 2011;44(3):572–587. 10.1016/j.patcog.2010.09.020 [DOI] [Google Scholar]
- 22. Gu Y, Wang Y, Liu T, Ji Y, Liu Z, Li P, et al. EmoSense: Computational Intelligence Driven Emotion Sensing via Wireless Channel Data. IEEE Transactions on Emerging Topics in Computational Intelligence. 2020;4(3):216–226. 10.1109/TETCI.2019.2902438 [DOI] [Google Scholar]
- 23. Egger M, Ley M, Hanke S. Emotion recognition from physiological signal analysis: A review. Electronic Notes in Theoretical Computer Science. 2019;343:35–55. 10.1016/j.entcs.2019.04.009 [DOI] [Google Scholar]
- 24. Zhang J, Yin Z, Chen P, Nichele S. Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review. Information Fusion. 2020;59:103–126. 10.1016/j.inffus.2020.01.011 [DOI] [Google Scholar]
- 25. Domínguez-Jiménez JA, Campo-Landines KC, Martínez-Santos JC, Delahoz EJ, Contreras-Ortiz SH. A machine learning model for emotion recognition from physiological signals. Biomedical Signal Processing and Control. 2020;55:101646 10.1016/j.bspc.2019.101646 [DOI] [Google Scholar]
- 26.Ragot M, Martin N, Em S, Pallamin N, Diverrez JM. Emotion recognition using physiological signals: laboratory vs. wearable sensors. In: International Conference on Applied Human Factors and Ergonomics. Springer; 2017. p. 15–22.
- 27. Ferreira PM, Marques F, Cardoso JS, Rebelo A. Physiological Inspired Deep Neural Networks for Emotion Recognition. IEEE Access. 2018;6:53930–53943. 10.1109/ACCESS.2018.2870063 [DOI] [Google Scholar]
- 28.Ranganathan H, Chakraborty S, Panchanathan S. Multimodal emotion recognition using deep learning architectures. In: 2016 IEEE Winter Conference on Applications of Computer Vision (WACV); 2016. p. 1–9.
- 29. Kanjo E, Younis EMG, Ang CS. Deep learning analysis of mobile physiological, environmental and location sensor data for emotion detection. Information Fusion. 2019;49:46–56. 10.1016/j.inffus.2018.09.001 [DOI] [Google Scholar]
- 30.Keren G, Kirschstein T, Marchi E, Ringeval F, Schuller B. End-to-end learning for dimensional emotion recognition from physiological signals. In: 2017 IEEE International Conference on Multimedia and Expo (ICME); 2017. p. 985–990.
- 31. Hassan MM, Alam MGR, Uddin MZ, Huda S, Almogren A, Fortino G. Human emotion recognition using deep belief network architecture. Information Fusion. 2019;51:10–18. 10.1016/j.inffus.2018.10.009 [DOI] [Google Scholar]
- 32. Deep learning models in genomics; are we there yet? Computational and Structural Biotechnology Journal. 2020;18:1466–1473. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Schmauch B, Romagnoni A, Pronier E, Saillard C, Maillé P, Calderaro J, et al. A deep learning model to predict RNA-Seq expression of tumours from whole slide images. Nature communications. 2020;11(1):1–15. 10.1038/s41467-020-17678-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Chen Y, Li Y, Narayan R, Subramanian A, Xie X. Gene expression inference with deep learning. Bioinformatics. 2016;32(12):1832–1839. 10.1093/bioinformatics/btw074 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Thomas J, Sael L. Deep neural network based precursor microRNA prediction on eleven species. arXiv preprint arXiv:170403834. 2017;.
- 36.Lee B, Baek J, Park S, Yoon S. deepTarget: end-to-end learning framework for microRNA target prediction using deep recurrent neural networks. In: Proceedings of the 7th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics; 2016. p. 434–442.
- 37. Kong Y, Yu T. A deep neural network model using random forest to extract feature representation for gene expression data classification. Scientific reports. 2018;8(1):1–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Gupta A, Wang H, Ganapathiraju M. Learning structure in gene expression data using deep architectures, with an application to gene clustering. In: 2015 IEEE International Conference on Bioinformatics and Biomedicine (BIBM); 2015. p. 1328–1335.
- 39.Ren Y, Wu Y. Convolutional deep belief networks for feature extraction of EEG signal. In: 2014 International Joint Conference on Neural Networks (IJCNN); 2014. p. 2850–2853.
- 40. Kohavi R, et al. A study of cross-validation and bootstrap for accuracy estimation and model selection In: Ijcai. vol. 14 Montreal, Canada; 1995. p. 1137–1145. [Google Scholar]
- 41. Katsigiannis S, Ramzan N. DREAMER: A Database for Emotion Recognition Through EEG and ECG Signals From Wireless Low-cost Off-the-Shelf Devices. IEEE Journal of Biomedical and Health Informatics. 2018;22(1):98–107. 10.1109/JBHI.2017.2688239 [DOI] [PubMed] [Google Scholar]
- 42. Ghasemzadeh H, Ostadabbas S, Guenterberg E, Pantelopoulos A. Wireless Medical-Embedded Systems: A Review of Signal-Processing Techniques for Classification. IEEE Sensors Journal. 2013;13(2):423–437. 10.1109/JSEN.2012.2222572 [DOI] [Google Scholar]
- 43. Sabeti M, Katebi S, Boostani R. Entropy and complexity measures for EEG signal classification of schizophrenic and control participants. Artificial Intelligence in Medicine. 2009;47(3):263–274. 10.1016/j.artmed.2009.03.003 [DOI] [PubMed] [Google Scholar]
- 44. Davidson RJ. Affective neuroscience and psychophysiology: Toward a synthesis. Psychophysiology. 2003;40(5):655–665. 10.1111/1469-8986.00067 [DOI] [PubMed] [Google Scholar]
- 45. Ramírez-Gallego S, Lastra I, Martínez-Rego D, Bolón-Canedo V, Benítez JM, Herrera F, et al. Fast-mRMR: Fast minimum redundancy maximum relevance algorithm for high-dimensional big data. International Journal of Intelligent Systems. 2017;32(2):134–152. 10.1002/int.21833 [DOI] [Google Scholar]
- 46. Nummenmaa L, Glerean E, Hari R, Hietanen JK. Bodily maps of emotions. Proceedings of the National Academy of Sciences. 2014;111(2):646–651. 10.1073/pnas.1321664111 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
(PDF)
(RAR)
Data Availability Statement
All relevant data are within the paper and Supporting information files.