
Figure 1. Typical workflow of the machine learning approach.
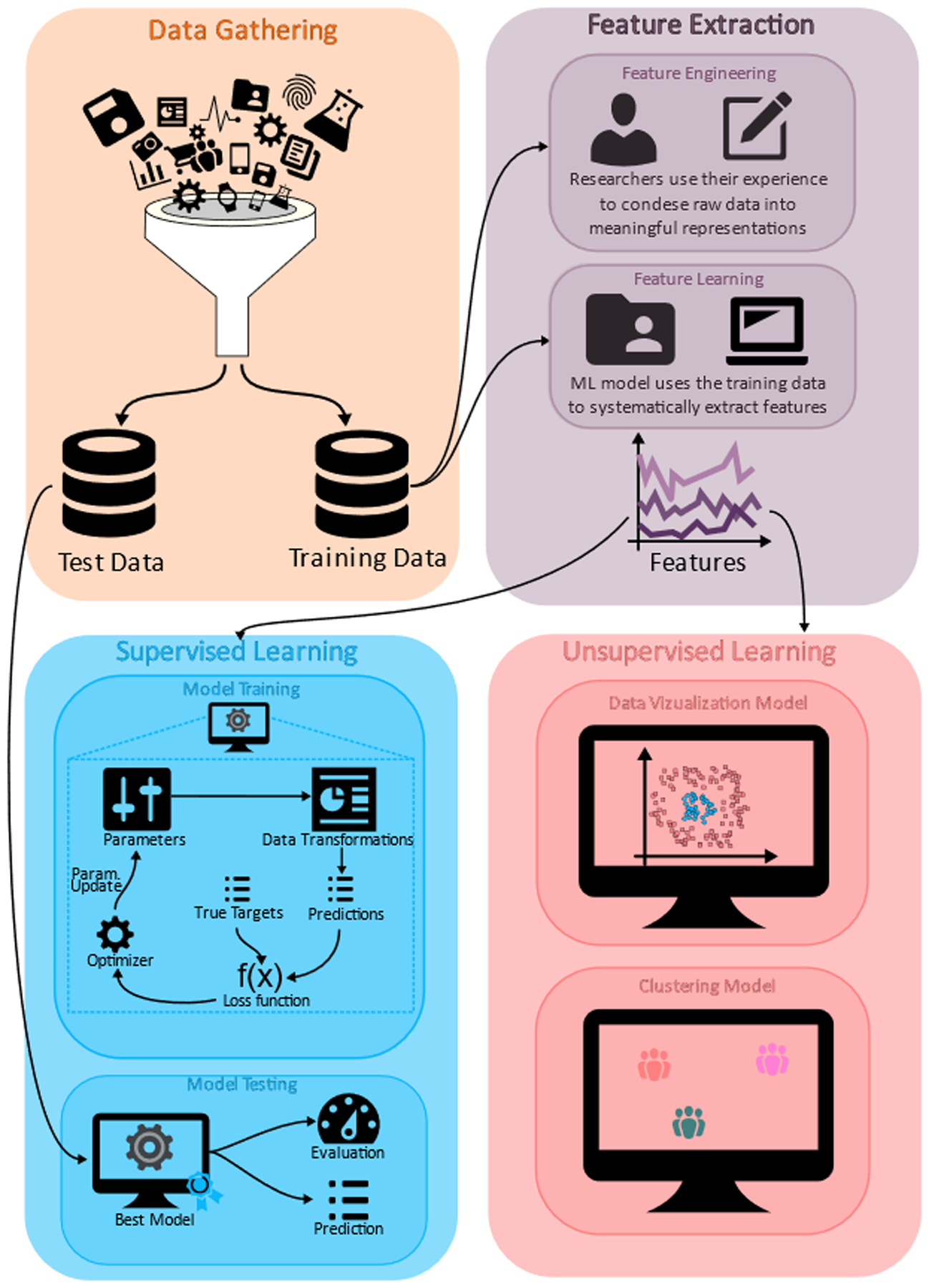
After the data gathering step, data is split into a train set and a test set. Features (useful representations of the data) are then extracted from the training data, either by performing researcher-defined transformations of the data (feature engineering) or using machine learning techniques (feature learning). Depending on the availability of targets (expected answers from the data) and the desired machine learning task, features can be used in either a supervised or unsupervised setting. In the supervised setting, a model is trained by iteratively minimizing a loss function, which adjusts the model’s parameters such that predictions and targets match. The resulting best model is then used on the test data. In the unsupervised setting in which there are no targets available, data can be used for visualization or identifying sub-groups with common characteristics, i.e., clusters.