
Fig. 2. Distribution of prediction scores for both the ICA-TC- and PCA-TC-based method.
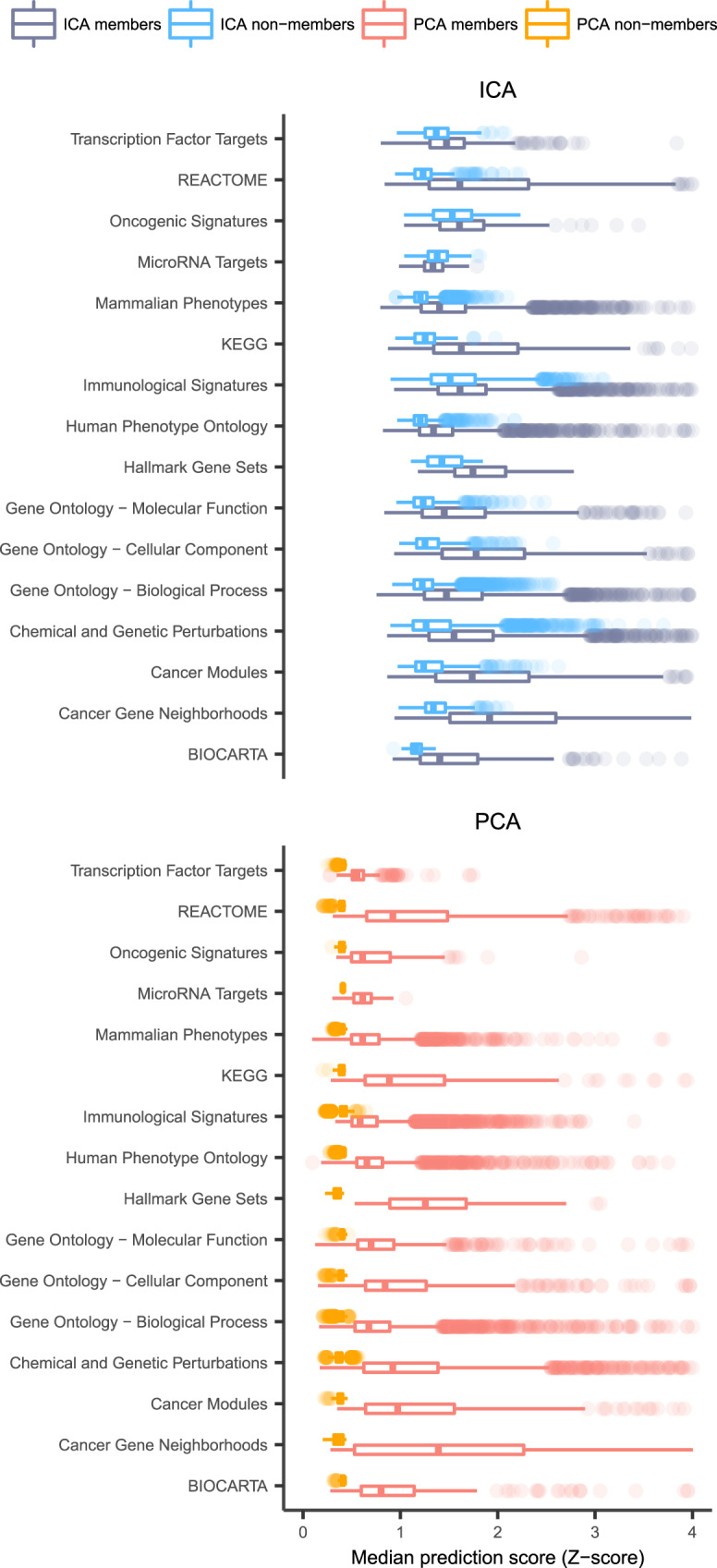
Boxplot of median prediction scores (x-axis) calculated from the ICA-TC-based (blue) and PCA-TC-based (red) methodology for each of the 16 gene set collections (y-axis). Median prediction scores are calculated separately for each gene set using both the ICA-TC- and the PCA-TC-based method for member (saturated) and nonmember genes (less saturated) and plotted side to side. Prediction scores of ICA-TC-based method are higher for both the members and the nonmember gene subset. ICA-TC-based predictions outperformed PCA-TC by obtaining higher median prediction scores for current member genes in all gene set collections (area under the curves (AUCs) calculated from two-sided Mann–Whitney U test range 0.7–0.99). Hinges of boxes represent second and third quartiles and whiskers extend by half that interquartile range. Center of box corresponds to median.