
Fig. 3.
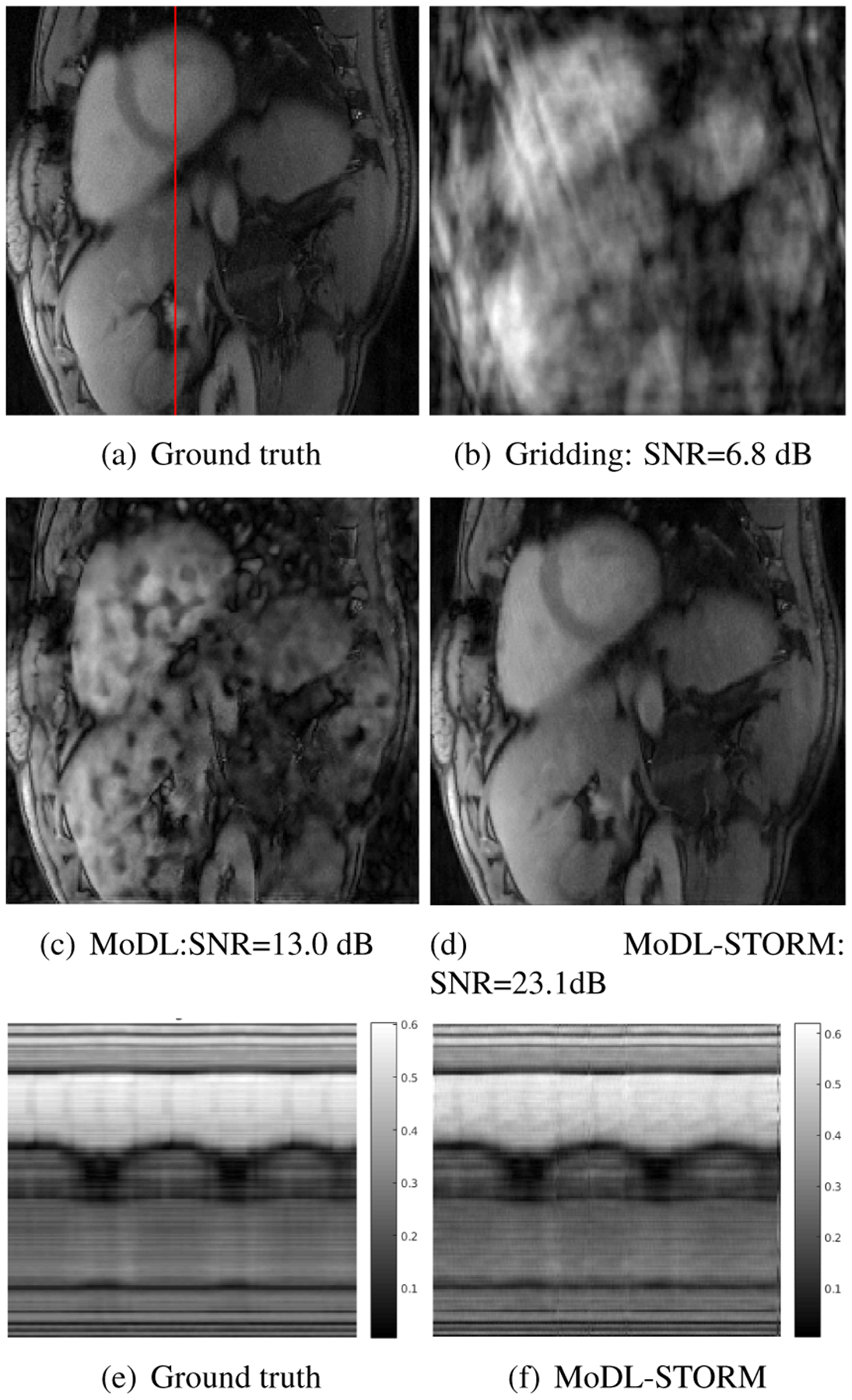
Reconstruction results at 16 fold acceleration. The ground truth data, recovered from 50 second (1000 frames) acquisition using STORM is shown in (a). The data from a subset of 204 frames is retrospectively downsampled assuming single channel acquisition and tested using different algorithm. The zero-filled IFFT reconstruction is shown in (b). A reconstructed frame using a network similar to ours without STORM priors (only CNN) is shown in (c). Note that the exploitation of the local similarities enabled by CNN alone is insufficient to provide good reconstructions at 16 fold acceleration. In contrast, the combination of deep learning and STORM priors yield reconstructions that are comparable in quality to the ground truth. The temporal profiles of the ground truth and MoDL-STORM reconstructions are shown in (e) and (f), respectively