
Fig. 3.
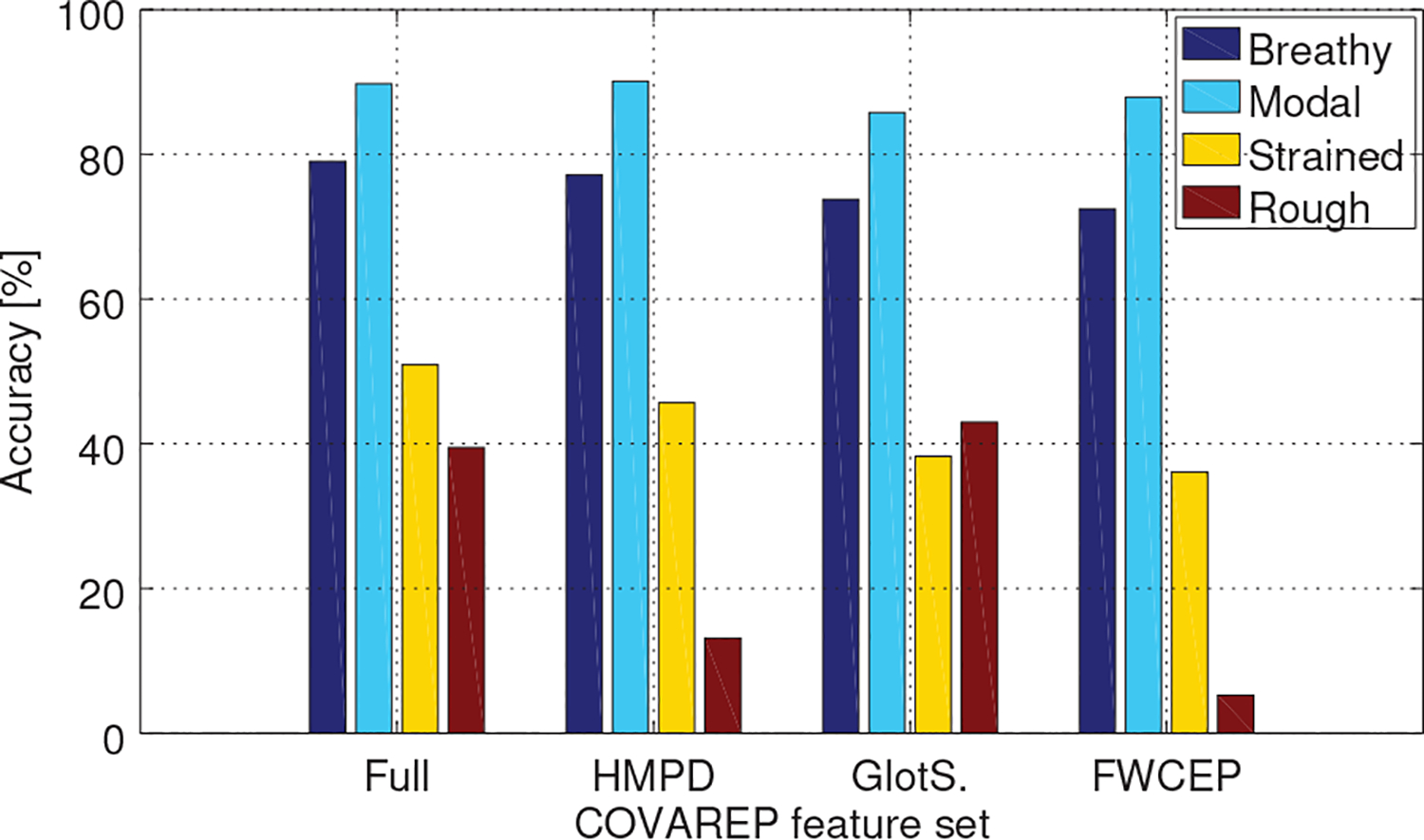
Average accuracy for breathy, modal, strained and rough modes for DNN, RF and SVM classifiers using the full COVAREP feature set.
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
Average accuracy for breathy, modal, strained and rough modes for DNN, RF and SVM classifiers using the full COVAREP feature set.