
Figure 3. Data preparation and modeling pipeline.
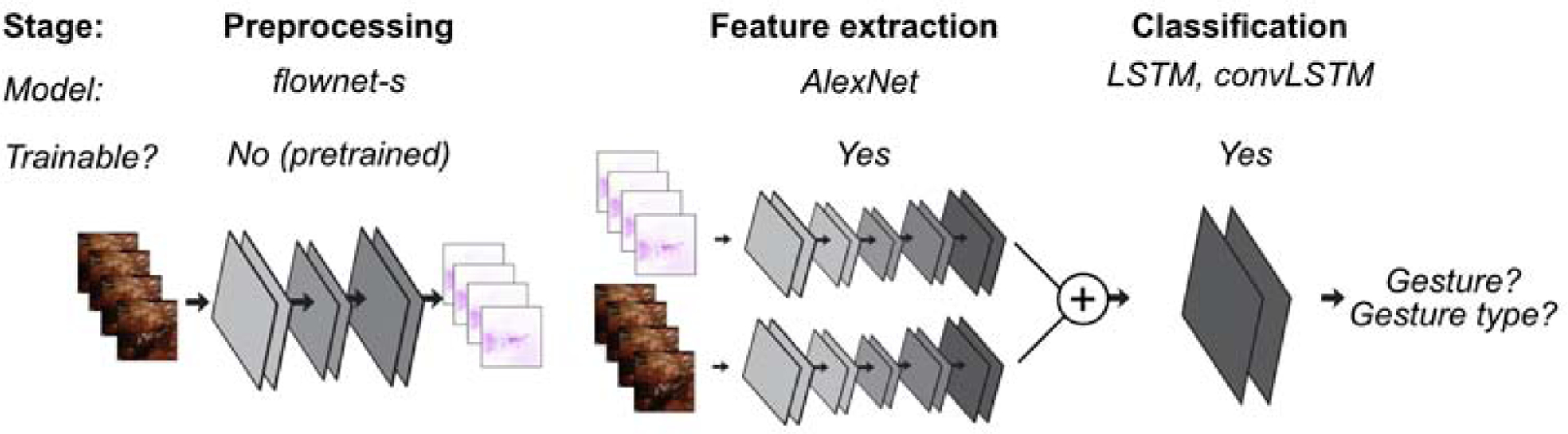
Schematic of the overall approach to developing a model for gesture presence and gesture type. Preprocessing: Prior to applying inputs to any trainable model, we pass the raw RGB video frames through a pre-trained deep network designed to produce optical flow estimates of the video. We code this optical flow into RGB using the hue as direction and saturation as magnitude. We pass this optical flow representation of the video alongside the RGB frames into the subsequent feature extractor networks. Feature extraction: We train two feature extractors (one for RGB, one for optical flow) initialized from ImageNet pertained deep networks. Outputs of these two networks are concatenated before passing to the classification layer. Classification: We train one of two varieties (LSTM, convolutional LSTM) of temporally recurrent classification layers on top of the features extracted. Depending on the task, these models are trained to either produce a 2-class label prediction (gesture identification) or a 5- class label prediction (gesture classification).