
Fig. 2:
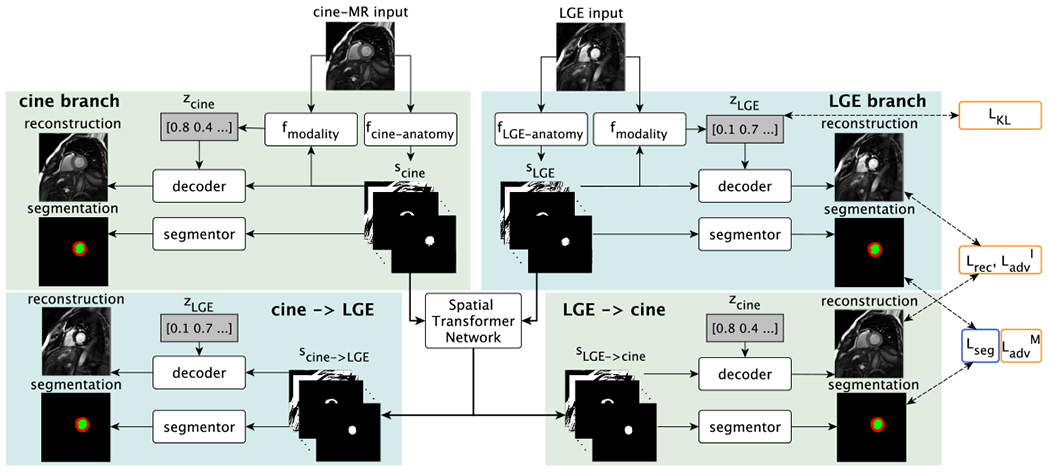
Training schematic with cine-MR and LGE input images. Each input image is disentangled into anatomical and modality factors. With a Spatial Transformer Network the deformation branches (lower parts) enable cross-modal synthesis and segmentation by deforming the anatomy factors scine and sLGE. Losses are indicated on the right and are also symmetrically applied to the cine-MR branch outputs. Yellow or blue outlines indicate if a loss is used when training with zero or full supervision, respectively. is not shown. See text for definitions.