
Figure 1.
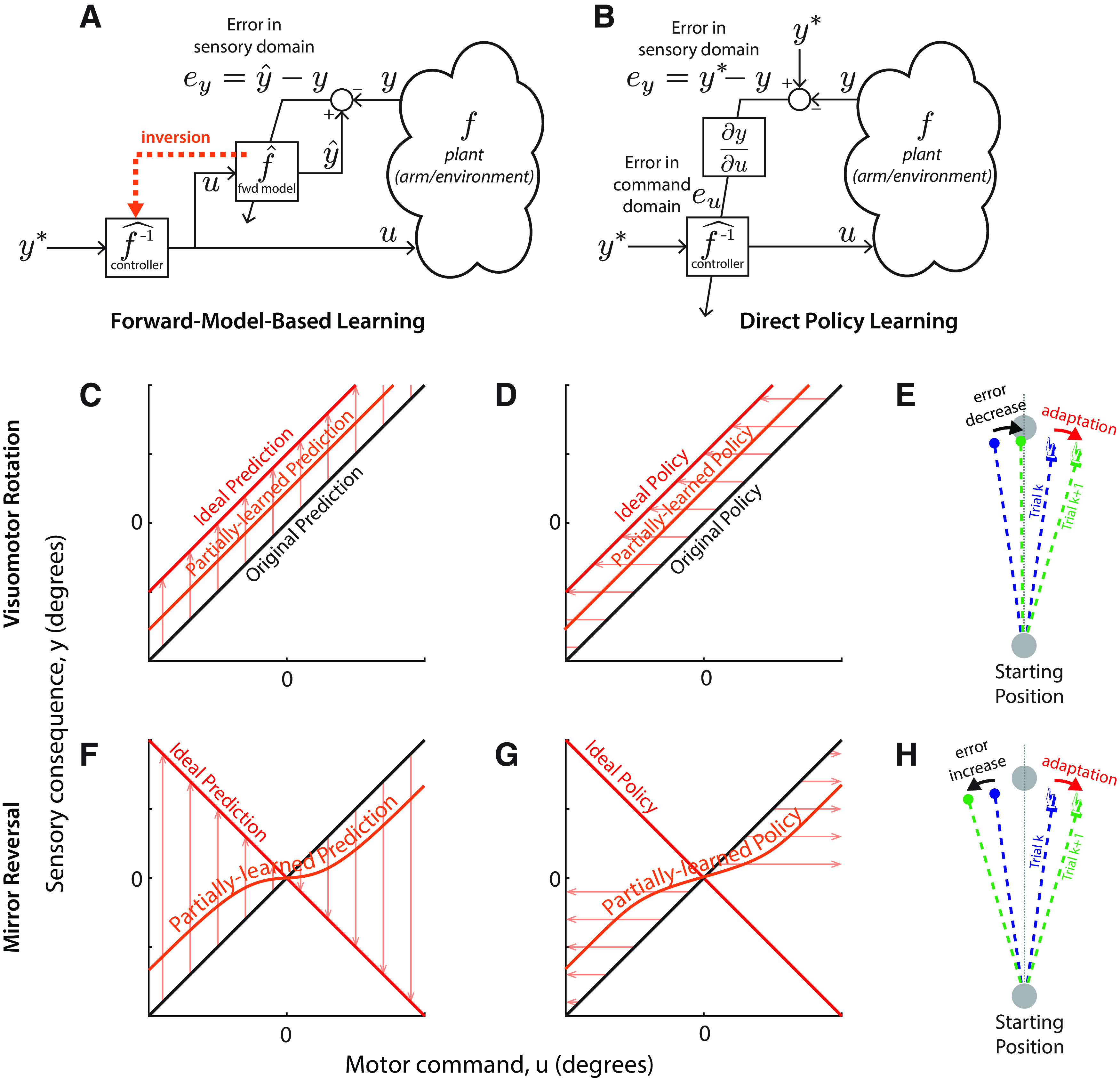
Forward-model-based learning and direct policy learning under visuomotor rotation and mirror reversal. A, Forward-model-based learning relies on updating an internal forward model that predicts the sensory consequences (y) of motor commands (u). In the case of simple cursor perturbations, we take u to be the direction the hand moves (motor command) and y to be the direction the cursor will move (sensory outcome). When the predicted sensory outcome (ŷ) differs from the observed one (y), the resulting error can be used to update the forward model without further assumptions. Given the desired sensory outcome, y*, the updated forward model can then be inverted to yield the appropriate motor command. B, In direct policy learning, sensory errors are used directly to update the policy (also often called an “inverse model”). Here, the policy is a function mapping movement goals (y*), represented in terms of desired sensory outcomes, to appropriate motor commands (u). Sensory errors must be translated to the motor domain, but this mapping depends on knowledge of the plant f (in mathematical terms, knowledge of the sensitivity derivative ∂f/∂u). In practice, direct policy learning must use an assumed mapping (Abdelghani and Tweed, 2010). C, D, Performance of forward-model-based learning (C) and direct policy learning (D) under visuomotor rotation. For forward-model-based learning, the arrows indicate the direction updates to the forward model; for direct policy updates, the arrows indicate the direction of changes to the control policy. In this example, y = u at baseline (black line), and direct policy updating therefore assumes that ey = eu. The red line represents the perturbed mapping (a visuomotor rotation by an angle θ, y = u + θ) and thus the ideal forward model prediction; the orange line represents a partially learned prediction. Under both models, adaptive changes are appropriate for the shifted visuomotor map: the forward model adjusts to predict the shifted sensory outcomes of efferent motor commands, whereas direct policy updates drive motor output in a direction that reduces error. E, Response of direct policy learning to errors resulting from a visuomotor rotation. In response to a leftward error, motor output is shifted rightward, reducing error in the next trial. F, G, forward-model-based learning (F) and direct policy learning (G) under mirror reversal. Here, 0 denotes the mirroring axis. Under the mirror reversal, y = –u, and therefore the relationship between task errors and motor errors is inverted: ey = –eu. If the sensitivity derivative used for direct policy learning is not updated accordingly, policy updates will occur in the wrong direction, driving motor output further and further away from that necessary to counter the mirror reversal. By contrast, there is no such difficulty associated with learning an updated forward model under the mirror reversal and therefore forward-model-based learning can occur without any issue. H, Response of direct policy learning to errors resulting from a mirror reversal. In response to a leftward error, motor output is shifted rightward, exactly as in E. Under the mirror reversal, however, this shift leads to an increase in error on the next trial.