
Figure 5.
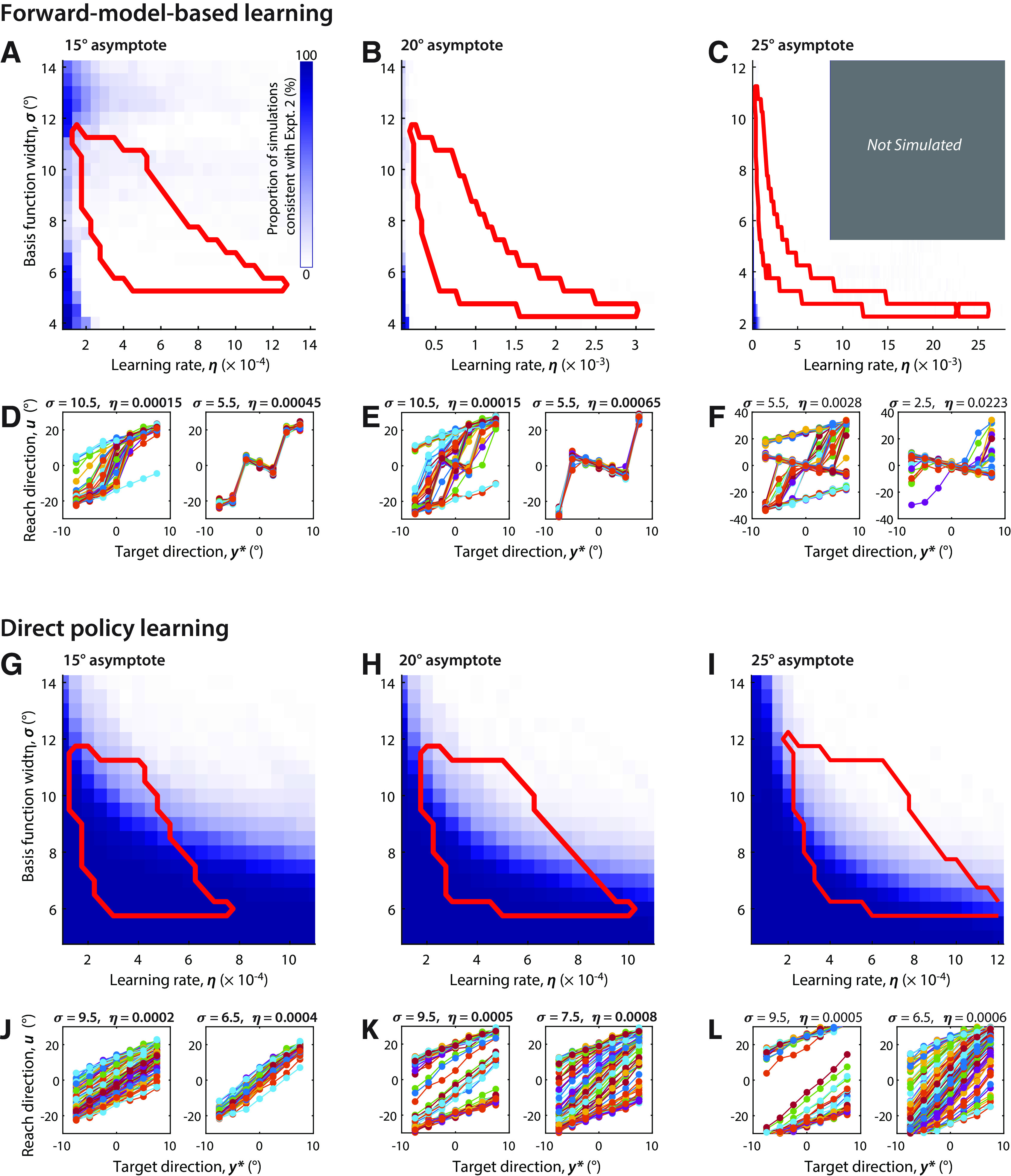
Simulations of forward-model-based learning and direct policy learning. A–J, Simulations of forward-model-based learning are inconsistent with the data and well characterized attributes of implicit adaptation. A–C, The extent to which simulations under different model parameters could qualitatively match the patterns of behavior observed in experiment 2, given an assumed asymptote of 15°, 20°, and 25° respectively. The color gradient indicates the proportion of pseudorandom simulations that resulted in both expansion (slope, >1.25) and smooth changes in reach direction across targets (dispersion of differences across targets, <6) given different values for basis function width and learning rate. The red border encloses parameter values consistent with known patterns of learning and generalization of visuomotor adaptation, based on the findings in the study by Morehead et al. (2017). The gray rectangle in C indicates (η, σ) pairs not simulated as they were well outside the red border. D–F, simulated steady-state relationships between target direction and reach direction (comparable to empirical data shown in Fig. 4G) for selected parameter values. For forward-model-based learning, there was no overlap between regions of parameter space for which simulated data were consistent with data in experiment 2 (regions shaded in blue), and regions of parameter space consistent with established properties of implicit adaptation (red-bordered region). G–L, same as A–F but for direct policy learning. G–I show that a wide range of model parameters for direct policy learning are qualitatively consistent with both empirical data in experiment 2 (regions shaded in blue) and with established properties of implicit adaptation (red-bordered regions).