
Figure 6.
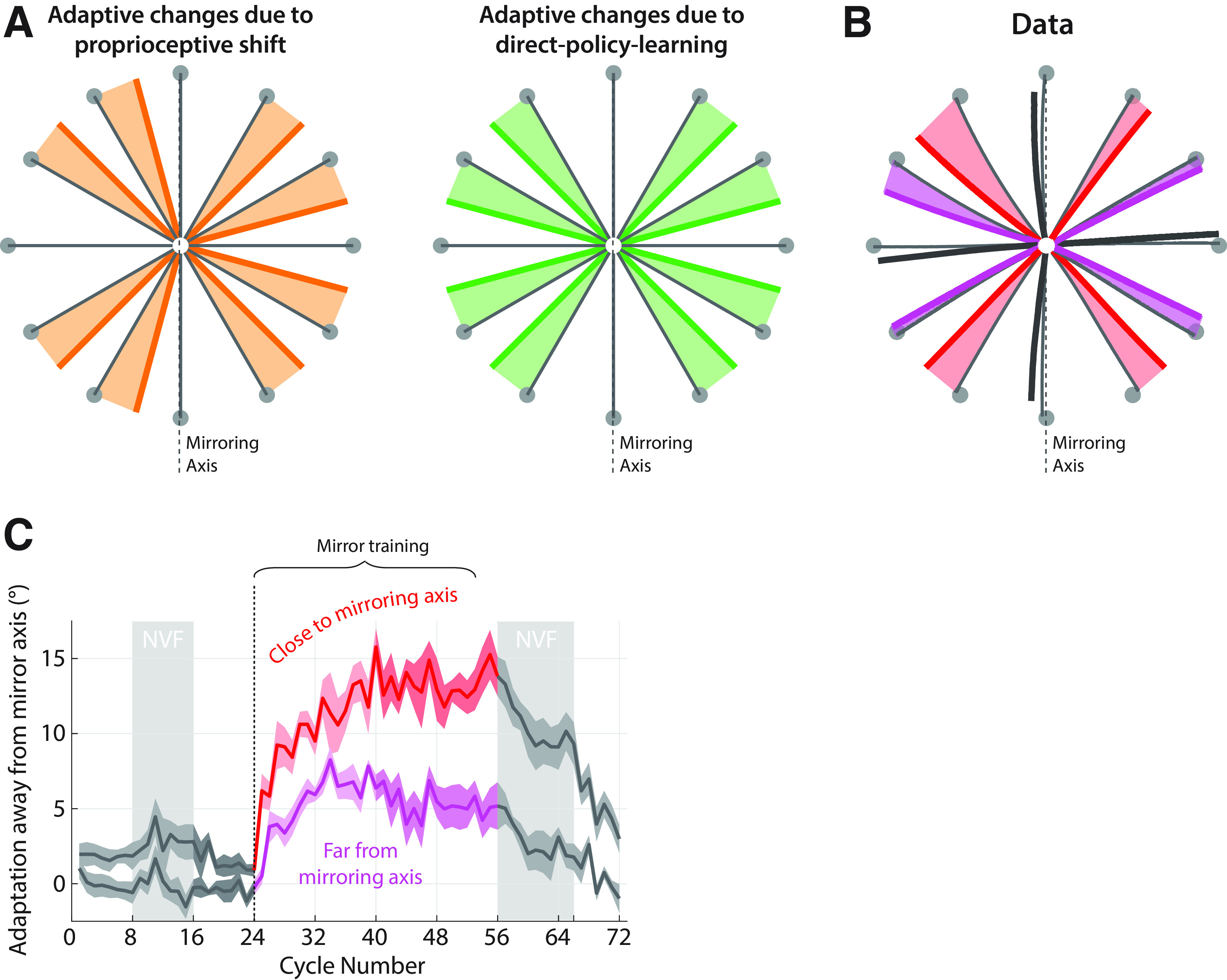
Adaptive changes to a mirror reversal when reaching to off-axis targets are consistent with direct policy learning, not forward-model-based learning or proprioceptive shifts. A, Expected pattern of changes in reach direction based on proprioceptive shift of the starting position (thick orange lines) versus direct policy learning adaptive changes (thick green lines). If the observed adaptive changes were because of a leftward shift in the perceived location of the hand at the start of each movement (Sober and Sabes, 2003), this would lead to systematic shift of all movements toward the rightward target. By contrast, drifts because of errant direct policy learning would always be directed away from the mirroring axis. Shading covers the area between baseline and adapted trajectories to highlight the predicted direction of changes. B, Average reaching trajectories in experiment 3 during baseline (thin black lines) and asymptote training (last two blocks; thick lines). Red, Off-axis targets close to the mirroring axis; magenta, off-axis targets far from the mirroring axis; gray, targets on the mirroring axis or perpendicular to it. Arrows show the direction of adaptive changes as a result of training. Shading highlights these changes in a similar way as in A. C, Trial-to-trial adaptation away from the mirroring axis for targets close to and far from the mirroring axis (red and magenta, respectively, as in A; darker shades illustrate the last block of training). Baseline adaptation levels are highlighted in dark gray; shading represents SEM. NVF, No visual feedback.