
Fig. 3.
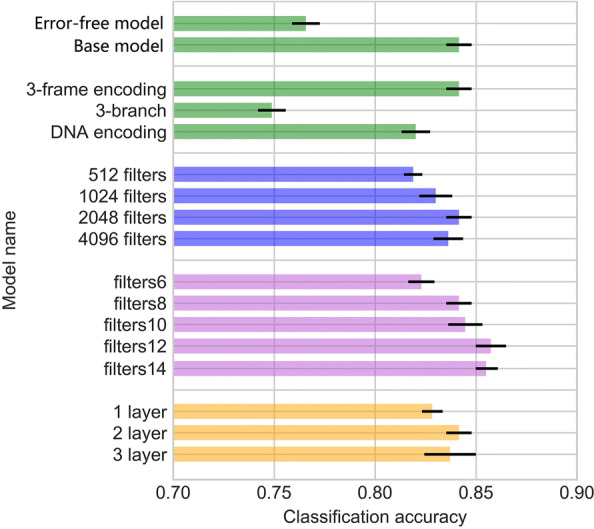
The mean and standard deviation of classification accuracy of different network architectures. Different colors represent different group of comparison: green bars for encoding and dataset; blue bars for number of filters; purple bars for different filter sizes; orange bars for different convolutional layers. Error-free model: the training data only contain the error-free reads; Base model: the training data contain both error-free reads and reads with error rate of 10%; 3-frame encoding: the encoding strategy in the base model; 3-branch: 3 branches structure for translated reads; DNA encoding: use one-hot encoding of DNA reads as input; 512 filters: use 512 filters in total in the 2nd convolutional layer; 1024 filters: use 1024 filters in total in the 2nd convolutional layer; 2048 filters: use 2048 filters in total in the 2nd convolutional layer; 4096 filters: use 4096 filters in total in the 2nd convolutional layer; filters6: filter sizes of 2nd convolutional layer =[6,9,12,15,18,21,24,27]; filters8: filter sizes of 2nd convolutional layer =[8,12,16,20,24,28,32,36]; filters10: filter sizes of 2nd convolutional layer =[10,15,20,25,30,35,40,45]; filters12: filter sizes of 2nd convolutional layer =[12,18,24,30,36,42,48,54]; filters14: filter sizes of 2nd convolutional layer =[12,18,24,30,36,42,48,54,60]; 1 layer: only keep the last convolutional layer; 2 layer: use two convolutional layers; 3 layer: add an extra convolutional layer with 64 filters of size 3