
Figure 2.
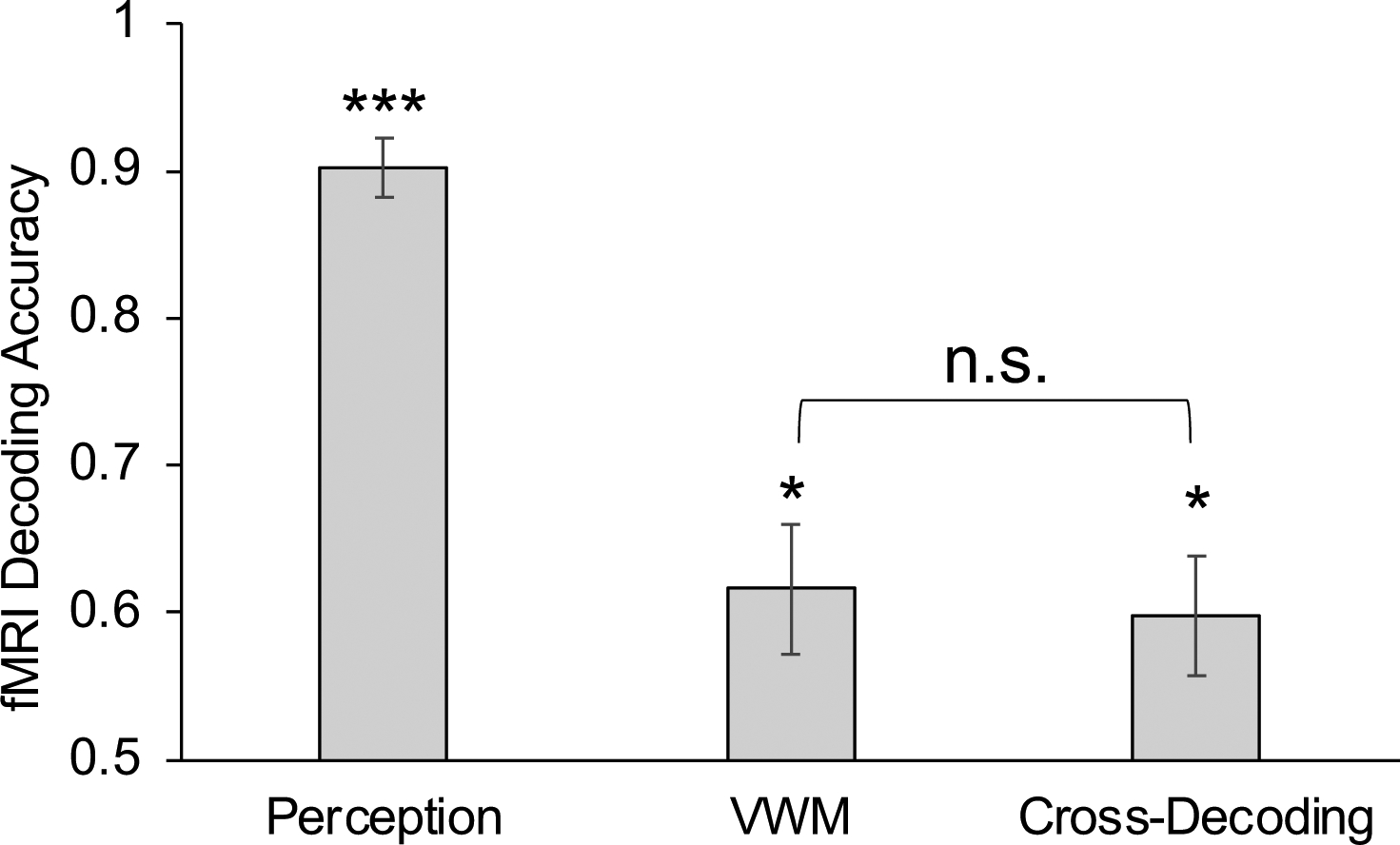
To examine the cross-decoding between VWM and perceptual representations in superior IPS, we asked seven participants (six females) to perform a VWM task and a perceptual task (Bettencourt & Xu, 2015). The VWM task adopted the same paradigm we used before (see Betterncourt & Xu, 2016a) but always with an unfilled delay period (i.e., no distractors) and with either a face or a gazebo image as the target instead of oriented gratings. In the perceptual task, participants viewed a sequential presentation of either faces or gazebos and performed a 1-back repetition detection task on the letter string shown at fixation. For within-task decoding, we performed training and testing on data within the same task; and for cross-task decoding, we trained the decoder on the data from the perception task and then tested it on the data from the VWM task. Error bars indicate s.e.m. * p < .05; *** p < .001; n.s., not significant. Stats reported here are corrected for multiple comparisons using the Benjamini-Hochberg method (Benjamini & Hochberg, 1995).