
Fig. 2.
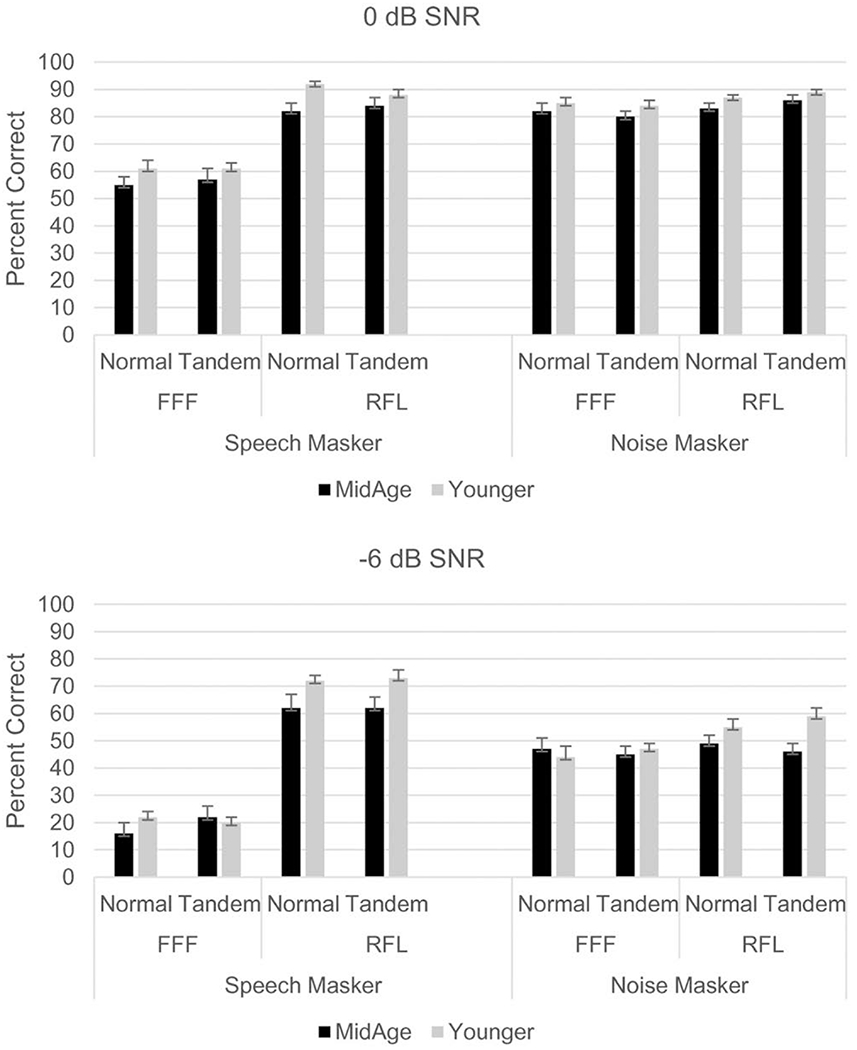
Percent-correct speech recognition data by participant group, listening condition, and stance. Upper panel = data collected at 0 dB SNR; bottom panel = data collected at −6 dB SNR. FFF = spatially-coincident target and masker; RFL = spatially separated target and masker. Error bars represent the standard error.