
Figure 1. Deep reinforcement learning.
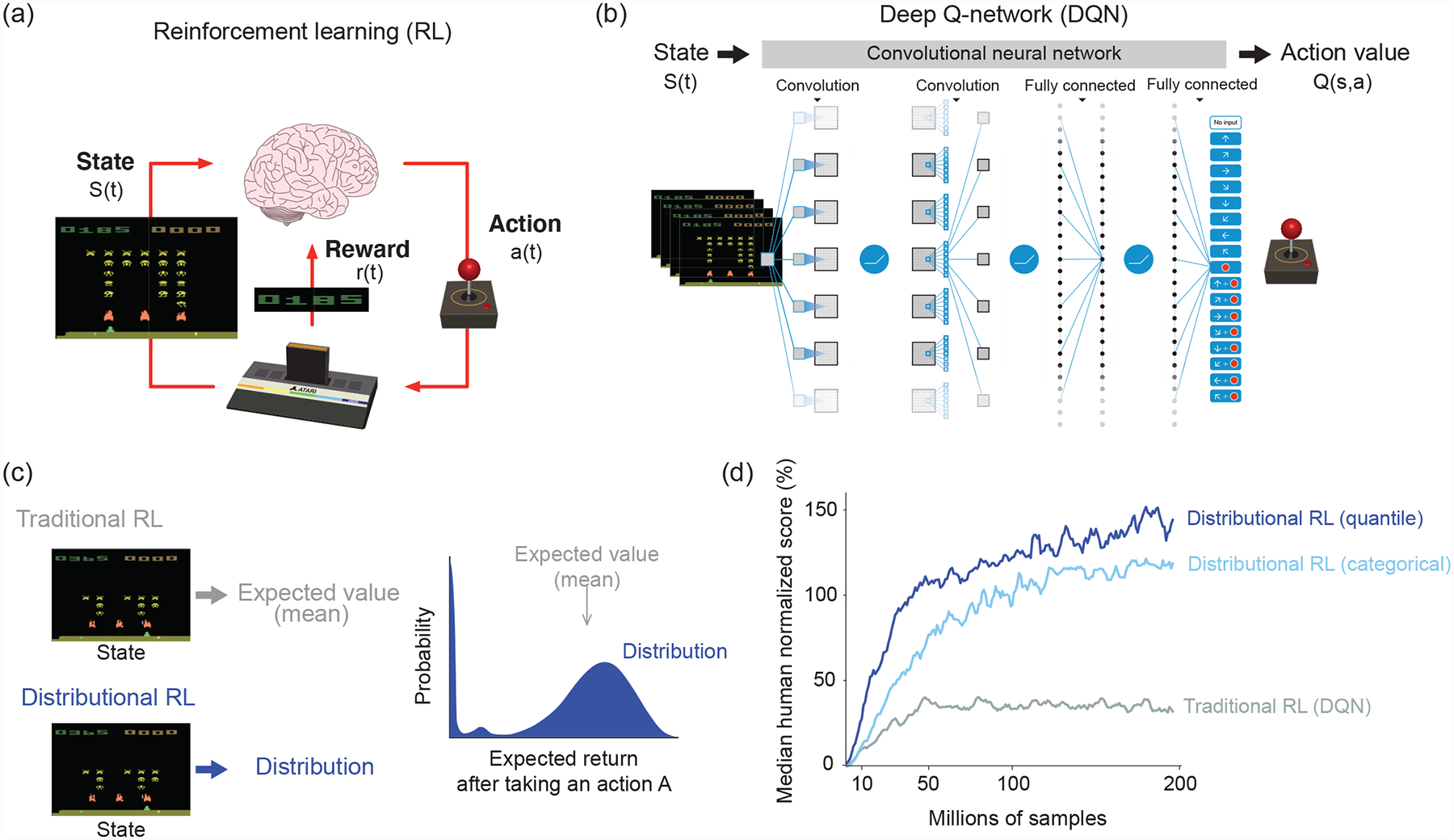
(a) A formulation of reinforcement learning problems. In reinforcement learning, an agent learns what action to take in a given state in order to maximize the cumulative sum of future rewards. In video games such as in an Atari game (here the Space Invader game is shown), an agent chooses which action (a(t), joystick turn, button press) to take based on the current state (s(t), pixel images). The reward (r(t)) is defined as the points that the agent or player earns. After David Silver’s lecture slide (https://www.davidsilver.uk/teaching/).
(b) Structure of deep Q-network (DQN). A deep artificial neural network (more specifically, a convolutional neural network) takes as input a high-dimensional state vector (pixel images of 4 consecutive Atari game frames) along with sparse scalar rewards, and returns as output a vector corresponding to the value of each possible action given that state (called action values or Q-values and denoted Q(s, a)). The agent chooses actions based on these Q-values. To improve performance, the original DQN implemented a technique called “experience replay,” whereby a sequence of events are stored in a memory buffer and replayed randomly during training [2]. This helped remove correlations in the observation sequence, which had previously prevented RL algorithms from being used to train neural networks. Modified after [2].
(c) Difference between traditional and distributional reinforcement learning. Distributional DQN estimates a complete reward distribution for each allowable action. Modified after [6].
(d) Performance of different RL algorithms in DQN. Gray, DQN using a traditional RL algorithm [2]. Light blue, DQN using a categorical distributional RL algorithm (C51 algorithm [6]). Blue, DQN using a distributional RL based on quantile regression [7]. Modified after [7].