
Figure 3. Distributional RL as minimizing a loss function.
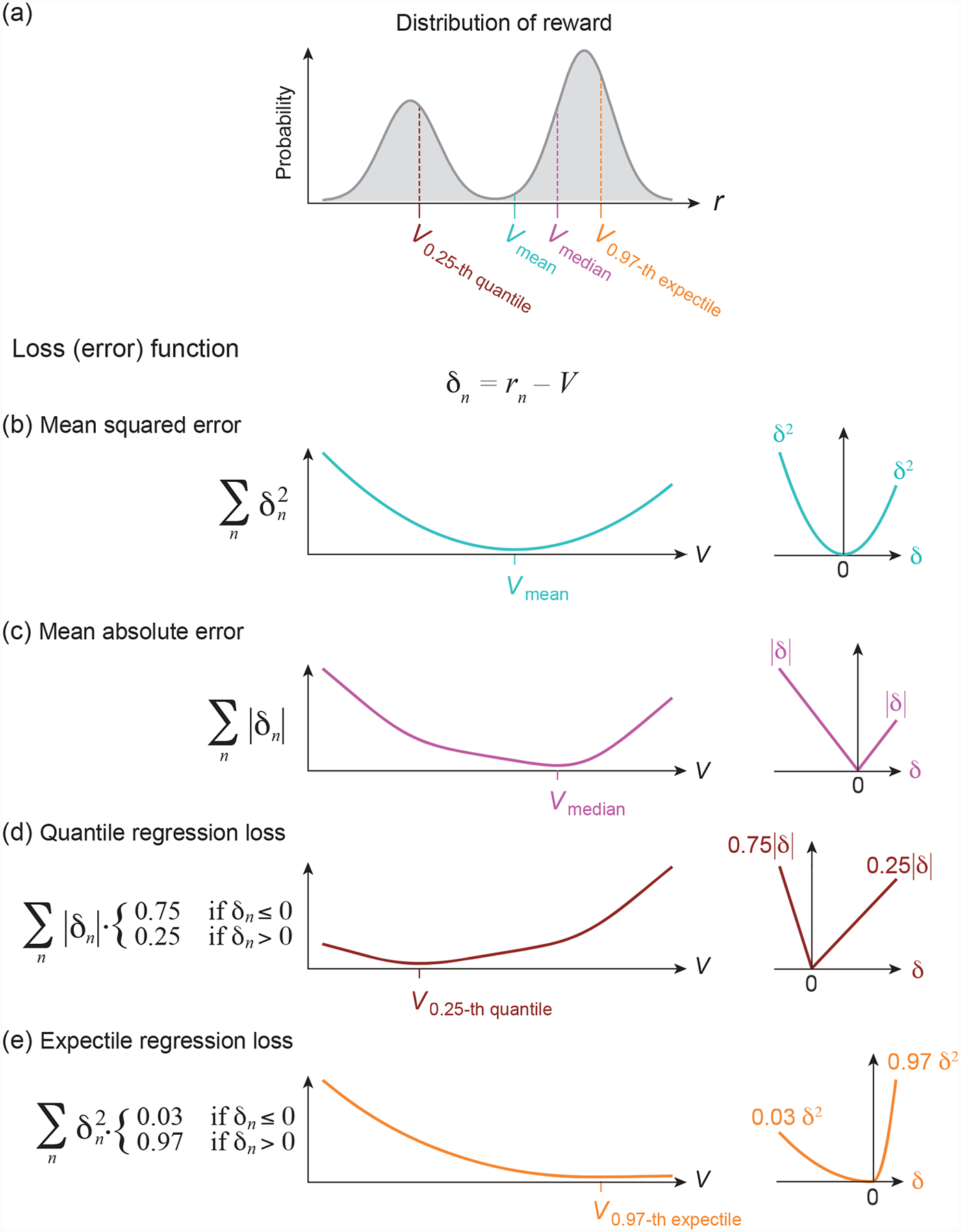
(a) The reward probabilities of an example reward distribution. Mean Vmean, median Vmedian, 0.25-quantile V0.25-quantile and 0.97-expectile V0.97-expectile of this distribution are indicated with different colors.
(b-e) Loss as a function of the value estimate V (left) when the rewards follow the distribution presented in (a), illustrating that V = Vmean minimizes the mean squared error (b), V = Vmedian minimizes the mean absolute error (c), V = V0.25-quantile minimizes the quantile regression loss for τ = 0.25 (d), and V = V0.97-expectile minimizes the expectile regression loss for τ = 0.97 (e). The right panels show the loss as a function of the RPE δ.