
Figure 1.
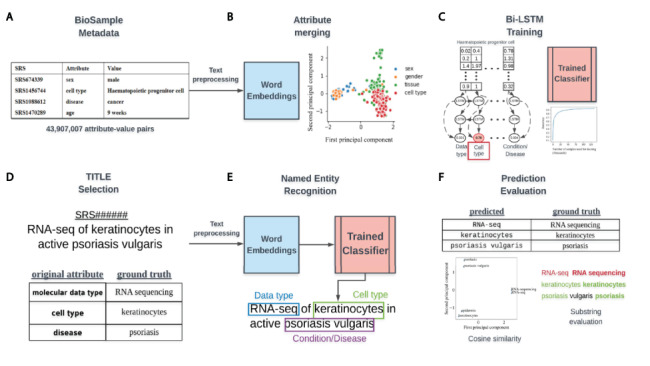
Overview of classifier training and metadata prediction workflow. (A) A few examples of the 44 million attribute-value pairs in SRA BioSample. (B) Word embeddings of preprocessed values allowed for the clustering and merging of attributes that were similar in the embedding space. (C) A subset of attribute-value pairs was split into a training and test set and a bi-LSTM classifier was trained to identify 11 metadata categories. (D) TITLEs were selected as the free-text for NER using the trained model. An example TITLE with associated ground truth labels is shown. (E) These TITLEs were preprocessed into n-grams and fed into the trained classifier after word embedding to generate metadata predictions for the 11 categories. (F) Comparisons to ground truth metadata were done using substring matching and cosine similarity in the word embedding space.