
Fig. 3.
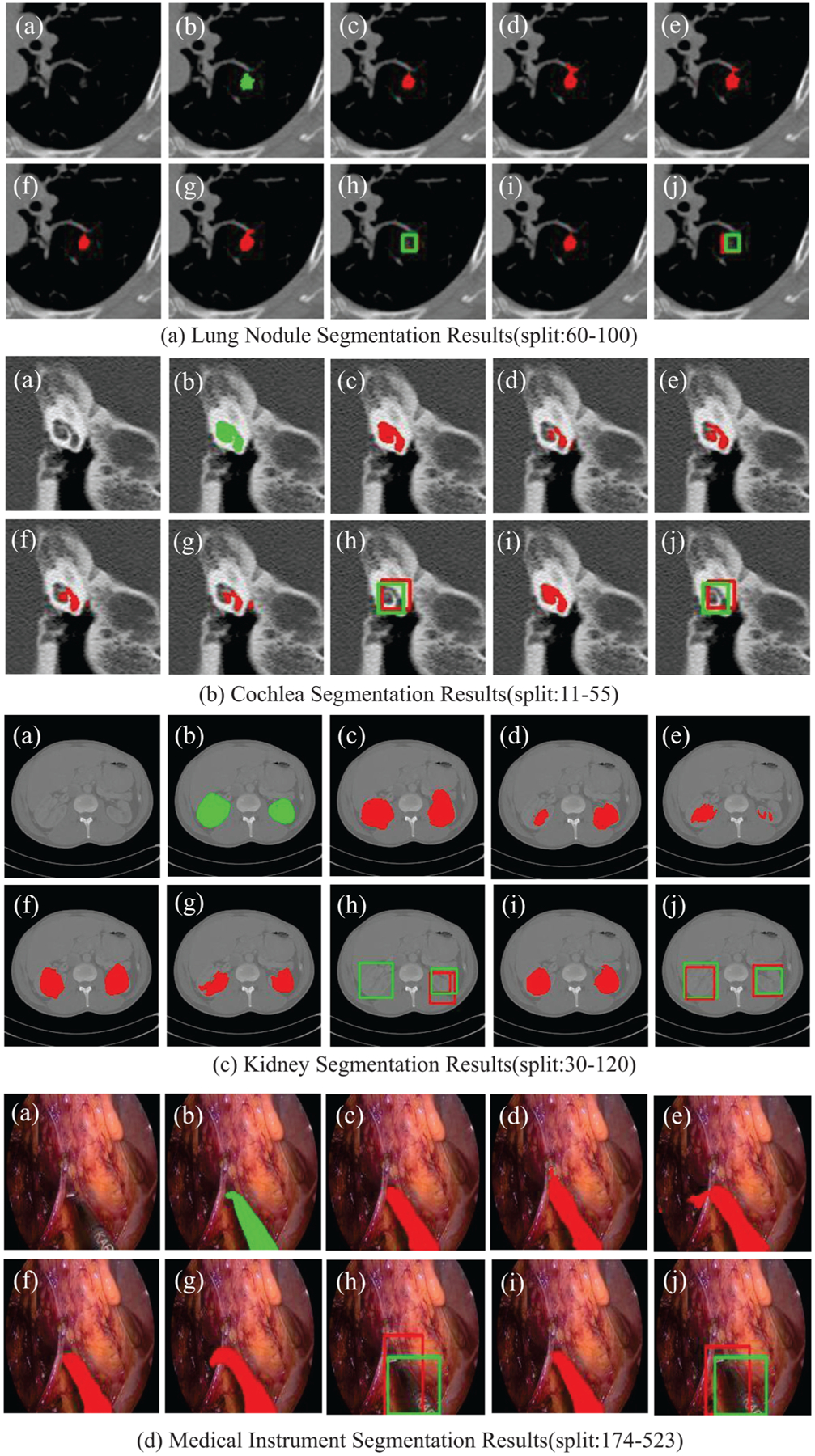
(a) Original image. (b) Ground truth. (c) U-Net trained in full-supervised manner. (d) U-Net trained with only strongly-annotated data. (e) U-Net+Unary sSE. (f) MSDN. (g) and (h) Segmentation and detection results of Variant MS-Net. (i) and (j) Segmentation and detection results of MSDN.