
Figure 2.
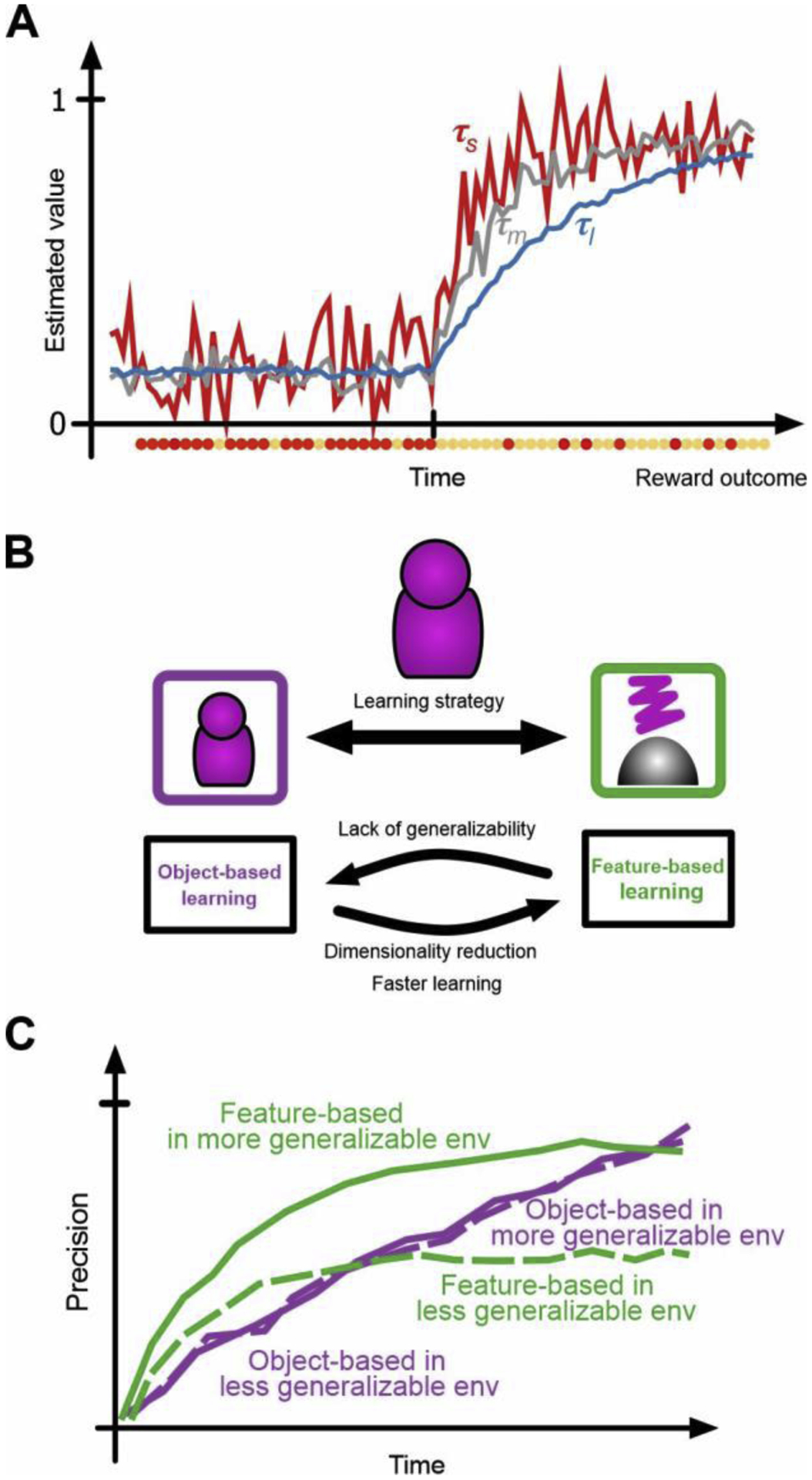
Adaptability-precision tradeoff in the integration of reward feedback. (A) Different timescales of reward integration allow different speeds for updating estimated values (adaptability) and different levels of accuracy for those estimates (precision). (B) Learning about multi-dimensional stimuli/options could be achieved by strategies with different levels of adaptability and precisions. (C) Accuracy in estimated values over time using feature-based or object-based learning in two environments with different levels of generalizability. With more generalizability, it takes longer for the object-based strategy to surpass the level of precision achieved by the feature-based strategy.