
Extended Data Fig. 1: Diagram of the RNN architecture.
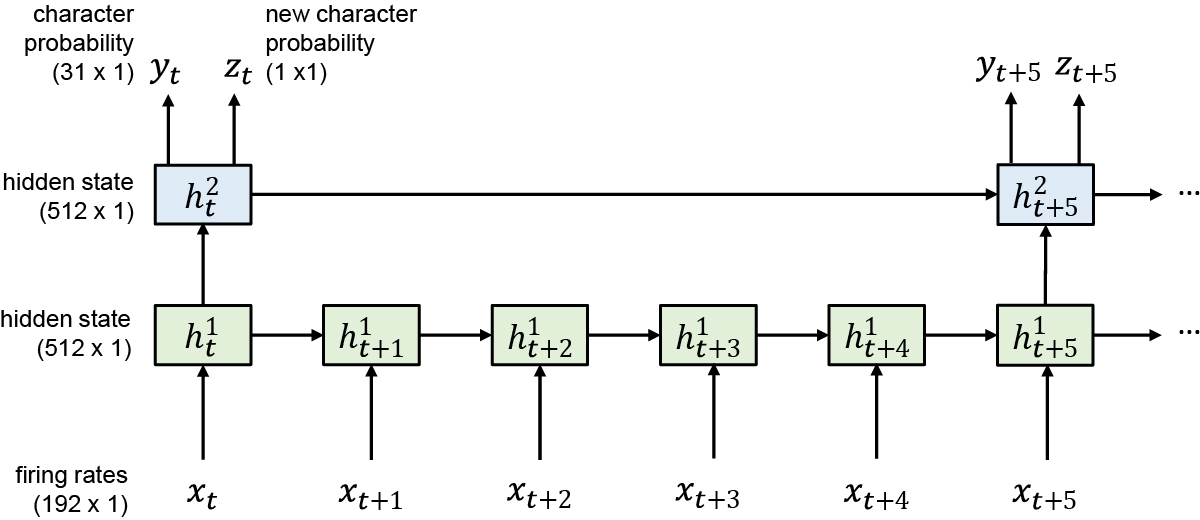
We used a two-layer gated recurrent unit (GRU) recurrent neural network architecture to convert sequences of neural firing rate vectors xt (which were temporally smoothed and binned at 20 ms) into sequences of character probability vectors yt and ‘new character’ probability scalars zt. The yt vectors describe the probability of each character being written at that moment in time, and the zt scalars go high whenever the RNN detects that T5 is beginning to write any new character. Note that the top RNN layer runs at a slower frequency than the bottom layer, which we found improved the speed of training by making it easier to hold information in memory for long time periods. Thus, the RNN outputs are updated only once every 100 ms.