
Extended Data Fig. 2: Overview of RNN training methods.
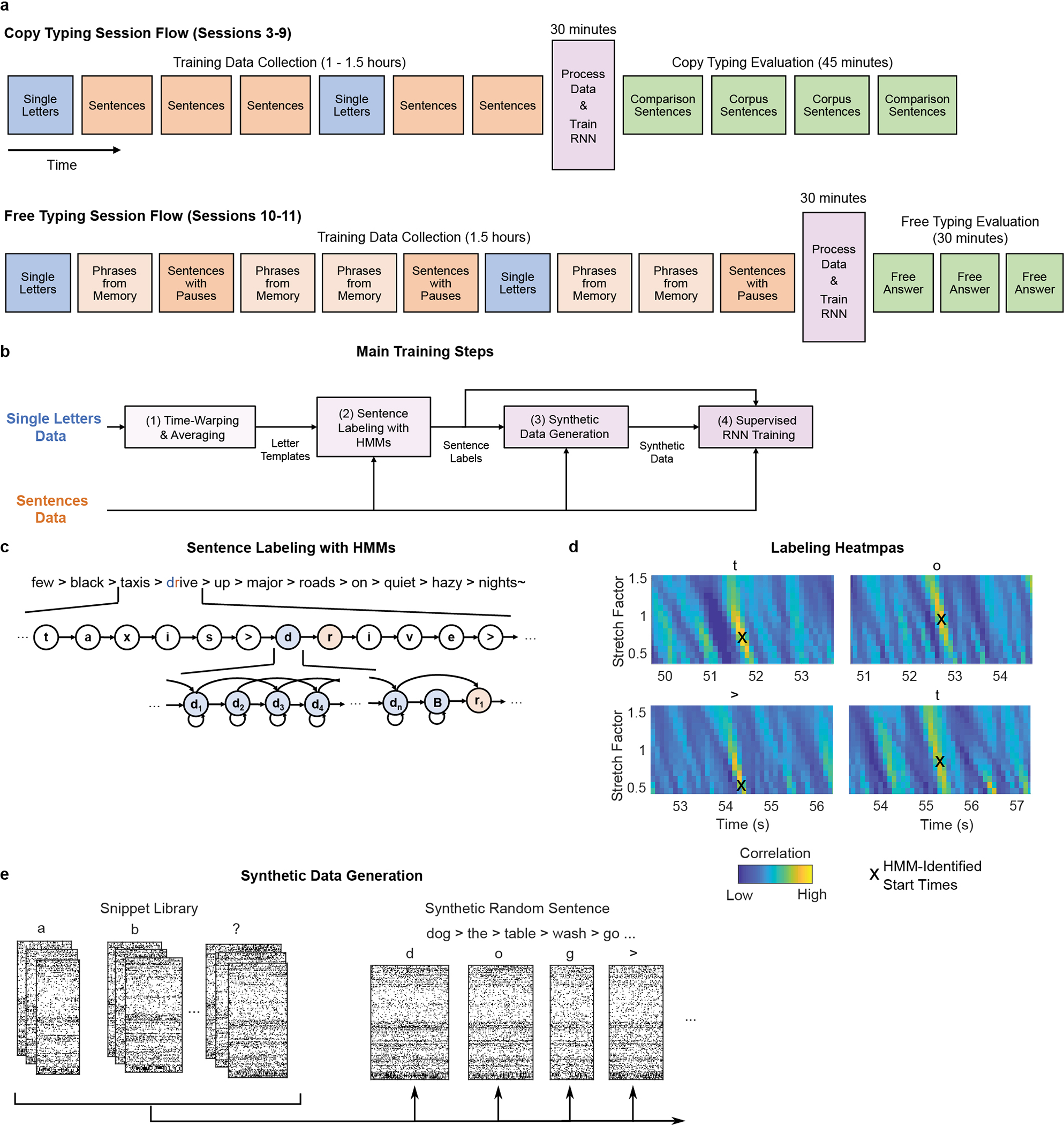
a, Diagram of the session flow for copy typing and free typing sessions (each rectangle corresponds to one block of data). First, single letter and sentences training data is collected (blue and red blocks). Next, the RNN is trained using the newly collected data plus all previous days’ data (purple block). Finally, the RNN is held fixed and evaluated (green blocks). b, Diagram of the data processing and RNN training process (purple block in a). First, the single letter data is time-warped and averaged to create spatiotemporal templates of neural activity for each character. These templates are used to initialize the hidden Markov models (HMMs) for sentence labeling. After labeling, the observed data is cut apart and rearranged into new sequences of characters to make synthetic sentences. Finally, the synthetic sentences are combined with the real sentences to train the RNN. c, Diagram of a forced-alignment HMM used to label the sentence “few black taxis drive up major roads on quiet hazy nights”. The HMM states correspond to the sequence of characters in the sentence. d, The label quality can be verified with cross-correlation heatmaps made by correlating the single character neural templates with the real data. The HMM-identified character start times form clear hotspots on the heatmaps. Note that these heatmaps are depicted only to qualitatively show label quality and aren’t used for training (only the character start times are needed to generate the targets for RNN training). e, To generate new synthetic sentences, the neural data corresponding to each labeled character in the real data is cut out of the data stream and put into a snippet library. These snippets are then pulled from the library at random, stretched/compressed in time by up to 30% (to add more artificial timing variability), and combined into new sentences.