
Figure 9.
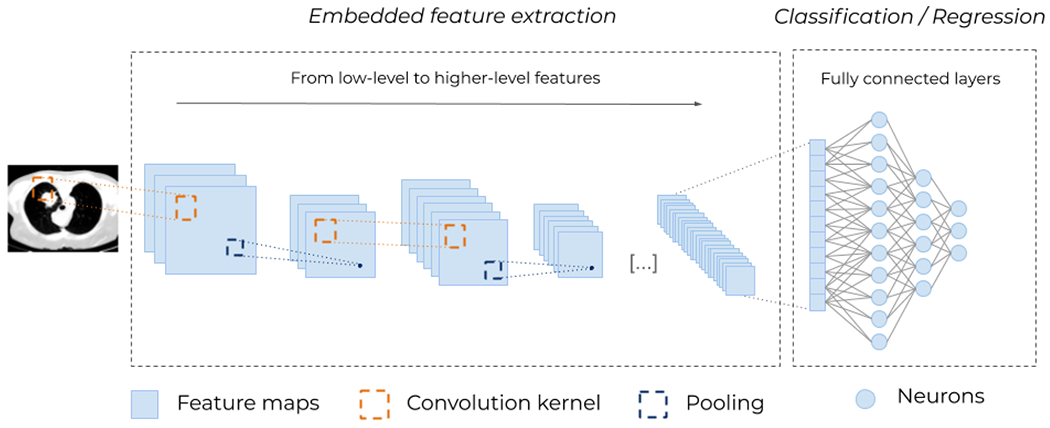
Typical architecture for a (deep) Convolutional Neural Network (CNN). Different convolutional kernels scan the input images leading to several feature maps. Then, down-sampling operations, such as max-pooling (i.e., taking the maximum value of a block of pixels), are applied to reduce the size of the feature maps. These two operations, convolution and pooling, are applied multiple times to extract higher-level features. At the end, the feature maps are flattened and passed through fully connected layers of neurons (see Figure 5), to obtain a final prediction. The embedded (automatic and unsupervised) feature extraction (Figure 4) is what enables CNNs to remove all handcrafted operations and makes them so powerful.