

Abstract
Background: Functional connectomes (FCs) have been shown to provide a reproducible individual fingerprint, which has opened the possibility of personalized medicine for neuro/psychiatric disorders. Thus, developing accurate ways to compare FCs is essential to establish associations with behavior and/or cognition at the individual level.
Methods: Canonically, FCs are compared using Pearson's correlation coefficient of the entire functional connectivity profiles. Recently, it has been proposed that the use of geodesic distance is a more accurate way of comparing FCs, one which reflects the underlying non-Euclidean geometry of the data. Computing geodesic distance requires FCs to be positive-definite and hence invertible matrices. As this requirement depends on the functional magnetic resonance imaging scanning length and the parcellation used, it is not always attainable and sometimes a regularization procedure is required.
Results: In the present work, we show that regularization is not only an algebraic operation for making FCs invertible, but also that an optimal magnitude of regularization leads to systematically higher fingerprints. We also show evidence that optimal regularization is data set-dependent and varies as a function of condition, parcellation, scanning length, and the number of frames used to compute the FCs.
Discussion: We demonstrate that a universally fixed regularization does not fully uncover the potential of geodesic distance on individual fingerprinting and indeed could severely diminish it. Thus, an optimal regularization must be estimated on each data set to uncover the most differentiable across-subject and reproducible within-subject geodesic distances between FCs. The resulting pairwise geodesic distances at the optimal regularization level constitute a very reliable quantification of differences between subjects.
Impact statement
Functional connectomes (FCs) have a reproducible individual fingerprint, making it possible to study neurological and psychiatric phenomena at an individual level. But this requires an accurate way to compare FCs to establish individual-level associations with behavior and/or cognition. Although the canonical methods of comparing FCs (e.g., correlation, Euclidean) are adequate, geodesic distance provides a more principled and accurate way of comparing FCs by utilizing the underlying non-Euclidean geometry of correlation matrices. We demonstrate that by combining geodesic distance with an optimal amount of regularization, we can get substantially more reliable estimates of relative distances between FCs and thus uncover individual-level differences.
Keywords: brain connectomics, FC fingerprinting, geodesic distance, individual fingerprint, regularization
Introduction
Brain activity can be estimated, indirectly, by measuring the blood oxygenation level dependent (BOLD) signal using magnetic resonance imaging (MRI) (Bandettini et al., 1992; Frahm et al., 1992; Kwong et al., 1992; Ogawa et al., 1990, 1992). This is the standard technique to generate brain images in functional MRI (fMRI) studies. Functional connectivity between two distinct brain regions is then defined as the statistical dependence between the corresponding BOLD signals, canonically estimated with Pearson's correlation coefficient (Bravais, 1846; Galton, 1886). A whole-brain functional connectivity pattern can be represented as a full symmetric correlation matrix denominated functional connectome (FC) (Fornito et al., 2016; Sporns, 2018). FCs have been used to study the changes in brain connectivity with aging (Zuo et al., 2017), cognitive abilities (Shen et al., 2017; Svaldi et al., 2019), and across a wide range of brain disorders (Fornito and Bullmore, 2015; Fornito et al., 2015; van den Heuvel and Sporns, 2019). Recently, it has also been shown that FCs have a recurrent and reproducible individual fingerprint (Abbas et al., 2020; Amico and Goñi, 2018; Finn et al., 2015; Gratton et al., 2018; Mars et al., 2018; Pallarés et al., 2018; Rajapandian et al., 2020; Satterthwaite et al., 2018; Seitzman et al., 2019; Venkatesh et al., 2020), which has opened the possibility of personalized medicine for neuro/psychiatric disorders (Satterthwaite et al., 2018), aided by improved acquisition parameters and the availability of large data sets with open data policy (Allen et al., 2014b; Amunts et al., 2016; Miller et al., 2016; Okano et al., 2015; Poo et al., 2016; Van Essen et al., 2012, 2013).
A clinically useful individual-level biomarker must have high interindividual differentiability, which in turn requires an accurate way of comparing individual FCs. FCs are compared traditionally by computing the Pearson's correlation coefficient between their upper-triangular vectorized versions (Amico andand Goñi, 2018; Bari et al., 2019; Finn et al., 2015). This approach enables us to assess to what extent it is possible to identify a participant from a large population of participants, a process known as fingerprinting or subject identification. The success rate of subject identification is known as identification rate (Finn et al., 2015) and has been also referred to as participant identification (Venkatesh et al., 2020). Although comparing FCs using Pearson's correlation coefficient is intuitive and computationally simple, it ignores the underlying geometry of the correlation-based FCs (Venkatesh et al., 2020) and hence has had only limited success in terms of identification rates (Finn et al., 2015).
A geometry-aware approach (Venkatesh et al., 2020) has recently been introduced to establish a more accurate way of measuring distance between any two FCs. FCs computed using Pearson's correlation coefficient between BOLD signals of all brain regions are objects that lie on or inside a nonlinear surface or manifold called the positive semidefinite cone (Fig. 1). This non-Euclidean geometry of FCs suggests that the distances between FCs are better measured along a geodesic of the cone. This contrasts with using correlation which is equivalent to the cosine of the angle between demeaned and normalized FCs, or the Euclidean distance which is equivalent to the straight-line distance between FCs. Venkatesh and colleagues (2020) applied the geodesic approach of comparison to the problem of individual fingerprinting and showed that it improves identification rates robustly compared with a dissimilarity measure based on Pearson's correlation coefficient. The improvement was observed across most conditions (resting-state [REST] and seven fMRI tasks) from the Human Connectome Project (HCP) data set.
FIG. 1.

Incremental regularization of FCs and its effect on the estimates of geodesic distance. We illustrate the geodesic distance between two FCs of size (denoted here by a circle and a triangle) and how it changes with increasing regularization (τ) of FCs. All the positive-definite (full rank) FCs comprise the cone interior, whereas all the rank-deficient positive semidefinite FCs (having at least one 0 eigenvalue) reside on the cone boundary. Different magnitudes of τ reallocate FCs within the positive semidefinite cone. We should also highlight that for FCs of higher dimensions, a three-dimensional visualization of the positive semidefinite cone is not possible. FCs, functional connectomes. Color images are available online.
The non-optimality of conventional metrics to compare FCs can be shown in another way. When comparing FCs using the conventional Pearson or Spearman-based correlations, the FCs are vectorized and then correlated. Implicit in this process is the assumption that all the elements of FCs are uncorrelated features. This is not the case. Since FCs are correlation matrices (Q), they live on or inside a positive semidefinite cone, that is, for all non-zero vectors y (Pennec et al., 2006). This means that elements of Q are interrelated, which violates the implicit uncorrelated feature assumption when conventional metrics are used to compare FCs. Geodesic distance treats Q as a single object, instead of treating each element separately, which results in much more accurate comparisons of FCs evidenced by robustly higher identification rates (Venkatesh et al., 2020).
The definition of geodesic distance between two positive definite matrices of the same size (say Q1 and Q2) requires that at least one of the matrices being compared is invertible (Pennec et al., 2006). When this is not the case (rank deficient matrices with at least one eigenvalue equal to 0), both Q1 and Q2 can be regularized by adding a scaled identity matrix, , to both, which increases the eigenvalues of both matrices by τ, ensuring that they become invertible. This process was used by Venkatesh and colleagues (2020) with a fixed, for all fMRI tasks, when computing geodesic distances between (otherwise) rank-deficient matrices. Rank-deficient FCs may occur typically when the number of time points (from the BOLD time-series) is smaller than the number of brain regions of the parcellation used. It may also happen when using very high-resolution parcellations, even if the number of time points is larger than the number of brain regions. Venkatesh and colleagues (2020) demonstrated that even with rank-deficient matrices, with the help of regularization, higher identification rates were achieved using geodesic distance when compared with identification rates based on correlation dissimilarity. Please note that regularization does not affect similarities or dissimilarities between FCs based on Pearson's correlation coefficient as the main diagonal is not even considered for comparison purposes.
Using a regularization of ensures that FCs were invertible and hence permits to use geodesic distance for assessing subject fingerprints as measured by identification rate. However, one could use any positive value of the regularization parameter, τ, and repeat the process of subject identification to assess performance. Geodesic distance is mostly influenced by the eigenvalues of the FCs being compared, which are in turn impacted by the values in their main diagonal. Hence, intuitively, increasing main diagonal regularization is equivalent to shifting and shrinking the space occupied by the matrices within the manifold (Fig. 1). Indeed, as τ tends to infinity all distances between FCs tend toward zero. It can be hypothesized that such regularized shrinking will affect not only absolute but also relative distances between FCs, which in turn would affect identification rates. In such a scenario, full rank and invertible FCs may also benefit from the same regularization procedure to improve identification rates.
In this article, we explore the effect of the magnitude of the regularization parameter (τ) on the geodesic distance between FCs and its impact on identification rates. We assess this effect for different scanning lengths, number of frames for a fixed scanning length, parcellations, and fMRI tasks and evaluate which levels of regularization maximize identification rates. In this manner, we aim to develop a procedure to uncover individual fingerprints by shifting FC data to an optimal location of the semidefinite cone where test/retest FCs are more differentiable across subjects. The existence of an optimal regularization would be critical to obtain the corresponding geodesic distances between FCs. An optimal amount of regularization should lead to higher identification rates in FCs (i.e., higher individual fingerprint), and hence, these optimally regularized FCs and particularly their corresponding pairwise distances would be better suited for establishing associations between functional connectivity and cognition, behavior, and neurological diseases at the individual level.
Methods
Data set
We included the unrelated subjects from the HCP 1200 participants release (Van Essen et al., 2013). This subset of unrelated subjects was chosen from the overall data set to ensure that no two subjects have a shared parent. The criterion to exclude siblings (whether they share one or both parents) was crucial to avoid confounding effects in our analyses due to family-structure confounders. Data from REST and seven fMRI tasks were used: emotion processing (EM), gambling (GAM), language (LAN), motor (MOT), relational processing (REL), social (SOC), and working memory (WM). In this study, we will refer to the resting-state plus all the tasks as conditions.
For each condition, subjects underwent two sessions corresponding to two different acquisitions (left to right or LR, and right to left or RL). The resting-state fMRI scans were acquired on two different days with a total of four sessions (coded as REST1 and REST2). The two sessions from REST1 were used for most of the analyses in this study. REST2 sessions were only used in the generalizability analysis (see the Subject Identification section). The HCP scanning protocol was approved by the institutional review board at Washington University in St. Louis. Full details on the HCP data set have been published previously (Glasser et al., 2013; Smith et al., 2013; Van Essen et al., 2012).
Brain parcellations
Two gray matter parcellations were used in this study:
The Destrieux atlas (Destrieux et al., 2010), or “aparc.2009s” in FreeSurfer nomenclature, defined using “Rules and algorithm that produced labels consistent with anatomical rules as well as automated computational parcellation,” featuring 75 regions in each hemisphere (74+Medial Wall), with the particularity of separating gyral and sulcal areas (a total of 150 brain regions).
MMP1.0 atlas (Glasser et al., 2016), a multimodal parcellation of the human cerebral cortex, with 180 brain regions in each hemisphere (a total of 360 brain regions).
For completeness, 14 subcortical regions were added to each parcellation, as provided by the HCP release (filename Atlas_ROI2.nii.gz). To do so, this file was converted from NIFTI to CIFTI format using the HCP workbench software (Glasser et al., 2016; Marcus et al., 2011). This resulted in a total of 164 and 374 brain regions for Destrieux and MMP1.0 parcellations, respectively.
Preprocessing
The data processed using the “minimal” preprocessing pipeline from the HCP were employed in this work (Glasser et al., 2013). This pipeline included artifact removal, motion correction, and registration to standard template. Full details on this pipeline can be found in earlier publications (Glasser et al., 2013; Smith et al., 2013).
We added the following steps to the “minimal” processing pipeline. For resting-state fMRI data: (i) we regressed out the global gray matter signal from the voxel time courses (Power et al., 2014), (ii) we applied a bandpass first-order Butterworth filter in the forward and reverse directions [0.001–0.08 Hz (Power et al., 2014); MATLAB functions butter and filtfilt], and (iii) the voxel time courses were z-scored and then averaged per brain region, excluding any outlier time points that were outside three standard deviation from the mean (workbench software, command -cifti-parcellate). For task fMRI data, we applied the same steps as mentioned above, but a more liberal frequency range was adopted for the band-pass filter (0.001–0.25 Hz) (Amico et al., 2019), since the relationship between different tasks and optimal frequency ranges is still unclear (Cole et al., 2014).
Table 1 shows the number of frames per run and the scanning length for all fMRI conditions. It also shows the number of participants for whom this number of frames per run was available after the preprocessing. Any runs where we could not fully process the data or were left with fewer frames were left out of the analyses.
Table 1.
Summary of the Number of Unrelated Participants Available (of a Total of 426) for Each Parcellation and Condition After Complete Preprocessing of the Functional Magnetic Resonance Imaging Data with Corresponding Number of Frames per Run
| Condition | REST | EM | GAM | LAN | MOT | REL | SOC | WM |
|---|---|---|---|---|---|---|---|---|
| Total participants—Destrieux | 407 | 408 | 408 | 409 | 409 | 409 | 409 | 409 |
| Total participants—MMP1.0 | 405 | 406 | 406 | 407 | 407 | 407 | 407 | 407 |
| Frames per run | 1190 | 166 | 243 | 306 | 274 | 222 | 264 | 395 |
| Scanning length, min | 14.28 | 1.99 | 2.92 | 3.67 | 3.29 | 2.66 | 3.17 | 4.74 |
EM, emotion processing; GAM, gambling; LAN, language; MOT, motor; REL, relational processing; REST, resting-state; SOC, social; WM, working memory.
Whole-brain FCs
As described in the Preprocessing section, for a given brain parcellation, time series data for each voxel were z-scored and averaged within each brain region. Pearson's correlation coefficient (MATLAB command corr) was used to estimate the functional connectivity between all pairs of brain regions, resulting in a symmetric correlation matrix of size , where m is the number of brain regions in the parcellation being used. This object is referred to as a FC. A whole-brain FC was computed for each of the two runs of each participant and each condition (resting-state and seven tasks).
As mentioned above, FCs are correlation matrices and it is well known that correlation matrices are symmetric positive semidefinite (SPSD), which means that their eigenvalues are greater than or equal to zero (Bhatia, 2009). If all the eigenvalues of an FC are strictly greater than zero, then it is a symmetric positive definite (SPD) FC matrix. The rank and invertibility of an FC are also directly related to its eigenvalues: if one or more eigenvalues are zero, then that FC is rank-deficient and not invertible. When all the eigenvalues are greater than zero for an FC, it is full-rank and hence invertible (Bhatia, 2009). The rank of an FC depends on the number of brain regions in the parcellation (m) and the number of samples in the time series (T) such that:
For all the conditions, the FCs generated using Destrieux parcellation were full-rank if the number of samples (frames) in the time series used was (e.g., when using entire scanning for any condition), whereas the FCs generated using MMP1.0 parcellation were always rank-deficient, regardless of the number of samples in the time series (Table 1).
Geometry of FCs
FCs estimated using Pearson's correlation coefficient are objects that lie on or inside a nonlinear surface, or manifold, called the positive semidefinite cone. Although a three-dimensional visualization of this manifold is only possible for FCs (Fig. 1), a manifold with exactly the same properties exists for FCs with higher dimensions (Bhatia, 2009). Pearson's correlation coefficient is the canonical way to estimate similarity/dissimilarity between FCs (Amico and Goñi, 2018; Finn et al., 2015), whereas other related approaches, such as Euclidean distance between the vectorized matrices (Ponsoda et al., 2017) and the so called Manhattan (L1) distance (Allen et al., 2014a), have also been used. Considering the non-Euclidean geometry of FCs, it is natural to measure the distance between FCs along the curvature of the positive semidefinite cone (Bhatia, 2009). The geodesic distance between two points inside the cone, thus between two SPD FCs Q1 and Q2, is the shortest path between them along the manifold and is unique for any two such points (Bhatia, 2009; Pennec et al., 2006).
Let 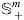 be the set of all symmetric positive matrices of dimension M, which lie on or inside an SPSD cone of dimension M. The positive-definite matrices would comprise the interior of the cone while all the rank-deficient semidefinite matrices would reside on the cone boundary. Now assume that
be the set of all symmetric positive matrices of dimension M, which lie on or inside an SPSD cone of dimension M. The positive-definite matrices would comprise the interior of the cone while all the rank-deficient semidefinite matrices would reside on the cone boundary. Now assume that 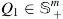 and
and 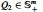 are two SPD matrices of size (here, or 374). Let us denote , then
are two SPD matrices of size (here, or 374). Let us denote , then 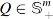 and its corresponding m eigenvalues satisfy . Then, the geodesic distance between Q1 and Q2 is computed as (Bhatia, 2009; Pennec et al., 2006):
and its corresponding m eigenvalues satisfy . Then, the geodesic distance between Q1 and Q2 is computed as (Bhatia, 2009; Pennec et al., 2006):
| (1) |
where is the matrix log operator. This definition of geodesic distance requires that the matrix Q1 is invertible (or equivalently SPD or full-rank). When this is not the case, we can regularize both Q1 and Q2 by adding to each of them a scaled identity matrix, , which increases the value of their eigenvalues by τ, ensuring that they are now invertible matrices. Importantly, this regularization reallocates both matrices within the positive semidefinite cone (Fig. 1).
Venkatesh and colleagues (2020) used with the specific purpose of ensuring full rank matrices. However, theoretically, one could use any positive value of the regularization parameter, τ, to ensure that both matrices (Q1 and Q2) are full rank. As mentioned earlier, all correlation matrices are either positive definite or positive semidefinite, which means that either all their eigenvalues are positive or at least one of them is zero (they cannot have negative eigenvalues). Thus, even a small positive perturbation to a rank-deficient correlation matrix using a scaled identity matrix would make it full rank and invertible (i.e., all eigenvalues greater than zero).
Subject identification
Subject identification is the process of identifying an individual's FC from a population of FCs, given another FC of that individual. All conditions (resting-state and seven tasks) in our data set contain two runs (LR and RL acquisition orientation), which we denominate here Test and Retest. To avoid any bias due to the acquisition orientation, runs were randomly assigned to either Test or Retest for each subject. This process was repeated for each condition separately.
An FC from the Retest data was labeled with the participant's identity in the Test data that was closest to it in the Test data. We repeated this process for all the FCs in the Retest data and defined the identification rate as:
This process was repeated by reversing the roles of test and retest sessions, as introduced by Finn and colleagues (2015). The final identification rate was obtained by averaging the two values.
The identification rates were computed for each condition separately. To study the effects of regularization on the identification rates, this process was repeated for a wide range of regularization parameter values, τ, in particular:
Different values of τ for the two parcellations were chosen based on preliminary exploration of the change in identification rates with τ.
To understand the effect of scanning length, for each value of τ, the identification process was repeated by selecting frames sequentially of the total time series, starting from 50 frames to the maximum number of frames, in steps of 50 (see Table 1 for maximum number of available frames and the corresponding scanning length for all eight fMRI conditions).
To understand the effect of number of frames when the scanning length is fixed, the identification process was repeated for each value of τ using the maximum scanning length. The number of frames was adjusted by choosing alternating frames from the time series, that is, by picking every second, third, fourth … frame. Note that this process is equivalent to assessing identification rates for longer repetition times (TRs). The maximum gap between chosen frames was decided for each condition to keep at least 50 frames in the final time series.
To assess variability in identification performance due to differences in samples, we used sampling without replacement. For every run, we randomly selected 80% of the participants and performed subject identification process. This procedure was repeated 100 times for each value of τ and for each number of frames evaluated.
The above mentioned “sampling without replacement” process would also serve as a proxy exploration of the generalizability of the optimal regularization magnitude for outside data sets of same or similar acquisition parameters as the ones used in this study. To explore generalizability of the optimal regularization magnitude across different sessions of the same subjects, two sessions from REST2 were used to compare the identification rates for varying values of τ with REST1, using the entire scanning length.
Results
We explored the effect of using different values of the regularization parameter (τ) on the geodesic distance, and the uncovering of individual fingerprint in FCs. Identification rate (Finn et al., 2015; Venkatesh et al., 2020) was used as a metric to quantify the individual fingerprint. Identification rate was computed by the Subject Identification process, which is the process of identifying an individual's FC from a population of FCs, given another FC of that individual. Identification rate is simply the percentage of accurately identified individuals. Through a small example, we show evidence of regularization affecting not only the global geodesic distance but also relative distance between FCs, which ultimately may affect identification rates. Then, we systematically studied how regularization affects identification rates for FCs, with different fMRI conditions (resting-state and seven fMRI tasks), parcellations, varying scanning lengths, and finally, varying number of frames for a fixed scanning length. The generalizability of the optimal regularization magnitude for different sessions of the same subjects and for different subjects for whom fMRI data were acquired with exactly same acquisition parameters was also investigated.
We first provided an example to develop an intuitive understanding of how regularization affects geodesic distances between FCs. To do so, we assessed the effect of regularization on geodesic distances among FCs when subjects are performing the emotion processing task. Figure 2A shows that as regularization (τ) increases, average geodesic distance across all subjects and sessions (global geodesic distance), exponentially decreases. We then assessed the effect of regularization on the relative geodesic distances between FCs. Figure 2B shows the proximity-rank in terms of distance. Briefly, the proximity-rank of an FC B with respect to an FC A quantifies how many FCs in that data set are closer to FC A than FC B. Taking as reference subject Atest, we tracked the proximity-rank of the subjects Aretest, Bretest, and Cretest at different levels of τ. At , compared with Bretest, there are many more FCs closer to Atest than Cretest. However, the situation is reversed at . In addition, at , Bretest is closer Atest than Aretest. Last but not least, the proximity-rank of the Aretest also changes with respect to Atest with regularization.
FIG. 2.

Effect of regularization (τ) on global and relative geodesic distances. We have chosen the emotion processing FCs to illustrate how geodesic distances across subjects and/or sessions change with regularization magnitude. (A) Global geodesic distance (in this case averaged geodesic distance between test and retest sessions of all subjects for the emotion processing task) decreases exponentially with increasing regularization. (B) Shows how close (in terms of proximity-rank with respect to all the other subjects) retest sessions of subjects A, B, and C are to the test session of subject A. Note that the three proximity-ranks fluctuate with regularization. (C) Identifiability matrix based on geodesic distance for low () regularization for a subsample of 25 subjects performing the emotion processing task. (D) Identifiability matrix based on geodesic distance for high () regularization for the same subsample of 25 subjects performing the emotion processing task. Color images are available online.
Results above show that regularization not only affects the global geodesic distance among FCs but also the relative distance, which may ultimately affect identification rates. Figure 2C and D shows the identifiability matrices for 25 subjects chosen arbitrarily (for ease of visualization) performing the emotion processing task at a low () and a high () value of regularization. An entry in an identifiability matrix here shows the geodesic distance between the test FC of the ith and the retest FC of the jth subject. Since the order of the subjects is the same across rows and columns, a main diagonal entry represents the geodesic distance between test and retest session of the same subject. Thus, a brighter main diagonal in Figure 2D, compared with Figure 2C, indicates that the test and retest sessions of the same subject are closer to each other than other subjects at than at , which should translate into higher identification rates.
Intuitively, these results tell us that asymptotically, geodesic distances between FCs approach zero as τ tends to infinity. In addition to affecting the absolute magnitude of the distances, τ also affects the relative distances between FCs and we have preliminary evidence that there is an optimal value/range of τ, which would affect relative distances in such a way that FCs from the two sessions of the same subject are closer to each other than any other FCs. These findings motivate us to assess changes in subject identification rates with varying magnitudes of τ.
Figure 3 shows the effect of τ on identification rates for all fMRI conditions (using the entire scanning length) and for both the Destrieux and MMP1.0 parcellations. Identification rates for all conditions and different parcellations appeared to be highly sensitive and roughly concave functions of τ. In most cases, we observed the presence of a clearly identifiable optimal τ (from now on denominated τ*) value for which the identification rate is maximized. For a few cases for the MMP1.0 parcellation, it seems that there was a wide range of optimal τ that produced very similar identification rates (e.g., resting-state, emotion).
FIG. 3.

Effect of regularization (τ) on identification rates. Identification rates for all eight conditions (utilizing maximum available scanning length) with variable magnitudes of τ, using Destrieux (left; 164 ROIs) and MMP1.0 (right; 374 ROIs) parcellations. Filled circles indicate the mean identification rate, whereas error bars indicate the standard error of the mean across samplings with replacement (error bars are small enough that they are hidden behind the circles). Legend indicates the eight conditions along with maximum available number of frames. Along each curve, the circle not filled indicates the optimal value of τ, which maximizes the identification rate. Color images are available online.
Using the entire scanning length, τ* depended not only on the condition but also on the parcellation (Fig. 3). The τ* values were smaller for the Destrieux parcellation than for the MMP1.0 parcellation for any given condition. Resting-state, language, and working memory had the highest, whereas the emotion task had the lowest identification rates at τ* for both parcellations. At τ*, the identification rates were either approximately equal (for resting-state) or higher when using MMP1.0 parcellation, compared with Destrieux, except for working memory and social tasks. For both parcellations, resting-state condition reached greater than 99% identification rate at τ*.
We then assessed the effect of scanning length on identification rate and how it interacts with τ. Results are shown in Figure 4 (Destrieux) and Figure 5 (MMP1.0). With the Destrieux parcellation (164 brain regions), in general, τ* was particularly small () for resting-state compared with most tasks (), with identification rates decreasing slowly with increasing magnitudes (Fig. 4). Overall, for resting-state compared with tasks, the scanning length used to compute FCs played a much bigger role in identification rates than the regularization magnitude. For a given τ, the identification rates tended to increase with increasing scanning length for all conditions, with maximal identification rates achieved with entire scanning length (see Table 2; resting-state and language conditions being the exceptions). With shorter scanning lengths, a broader range of τ optimized the identification rates. But as the scanning length increased, this range became narrower and hence maximal identification rates required more specific regularization. Also, the drop off in identification rates was sharper when the optimal τ range became narrower. This pattern is less clear with the emotion processing task, perhaps due to emotion processing being the fMRI condition with the shortest scanning length than the other tasks (Table 1).
FIG. 4.

Identification rates as a function of regularization (τ) and scanning length used to compute FCs using Destrieux parcellation. The panel shows identification rates, averaged across samplings without replacement, for all eight fMRI conditions. For any given condition, the scanning length was adjusted by selecting frames sequentially of the total time series ranging from 50 to maximum number of frames available, in steps of 50. fMRI, functional magnetic resonance imaging. Color images are available online.
FIG. 5.

Identification rates as a function of regularization (τ) and scanning length used to compute FCs using MMP1.0 parcellation. The panel shows identification rates, averaged across samplings without replacement, for all eight fMRI conditions. For any given condition, the scanning length was adjusted by selecting frames sequentially of the total time series ranging from 50 to maximum number of frames available, in steps of 50. Color images are available online.
Table 2.
Optimal Identification Rates for All Eight Functional Magnetic Resonance Imaging Conditions Using Destrieux Parcellation, and the Corresponding Values of the Optimal Scan Length, Percentage of Maximum Available Frames, and the Optimal Regularization Magnitude (τ*)
| Condition | REST | EM | GAM | LAN | MOT | REL | SOC | WM |
|---|---|---|---|---|---|---|---|---|
| Optimal ID rate | 0.98 | 0.59 | 0.76 | 0.90 | 0.73 | 0.71 | 0.84 | 0.90 |
| Optimal scan length, min:sec | 13:48 | 1:59 | 2:55 | 3:36 | 3:17 | 2:40 | 3:10 | 4:44 |
| % of frames | 97 | 100 | 100 | 98 | 100 | 100 | 100 | 100 |
| τ* | 0.2 | 1.9 | 1.3 | 0.5 | 0.2 | 1.8 | 0.5 | 0.1 |
ID, identification.
With MMP1.0 parcellation (374 brain regions), we observed similar results. Just as with the Destrieux parcellation, resting-state behaved differently than tasks. First, for any given scanning length, τ* values were much smaller for resting-state than for tasks (Fig. 5). Second, the identification rates for resting-state were more dependent on the scanning length than on the regularization. For a given τ, identification rates tended to increase with increasing scanning length for all conditions, with maximal identification rates achieved with entire scanning length (Table 3). Finally, the optimal ranges of τ were broader with shorter scanning length and more specific with increasing scanning length. In comparison to the Destrieux parcellation, the narrowing of the optimal τ range required longer scanning length for MMP1.0 for any given condition.
Table 3.
Optimal Identification Rates for All Eight Functional Magnetic Resonance Imaging Conditions Using MMP1.0 Parcellation, and the Corresponding Values of the Optimal Scan Length, Percentage of Maximum Available Frames, and the Optimal Regularization Magnitude (τ*)
| Condition | REST | EM | GAM | LAN | MOT | REL | SOC | WM |
|---|---|---|---|---|---|---|---|---|
| Optimal ID rate | 0.98 | 0.63 | 0.81 | 0.92 | 0.76 | 0.75 | 0.83 | 0.88 |
| Optimal scan length, min:sec | 14:17 | 1:59 | 2:55 | 3:40 | 3:17 | 2:40 | 3:10 | 4:44 |
| % of frames | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| τ* | 4.0 | 5.5 | 5.0 | 3.0 | 2.5 | 6.0 | 2.5 | 2.5 |
We also assessed the effect of number of frames on the identification rates, when maintaining the entire scanning length. Overall, for a given condition, the identification rate was not severely affected by decreasing the number of frames (Fig. 6). When the number of frames became too small (different for each condition), identification rates dropped more drastically for the Destrieux parcellation than for the MMP1.0. It is interesting to note that with ∼170 or more frames, identification rates reach a plateau for all fMRI conditions and parcellations.
FIG. 6.

Effect of number of frames on identification rates using the entire scanning length. Identification rates for all eight fMRI conditions (utilizing optimal regularization magnitude [τ*]—see Table 1) with variable number of frames, using Destrieux (left; 164 ROIs) and MMP1.0 (right; 374 ROIs) parcellations. Maximum scanning length was always maintained for each condition by choosing alternate points from BOLD time series. For instance, 397 frames were obtained for resting-state by choosing every third time point. Filled circles indicate the mean identification rate, whereas error bars indicate the standard error of the mean across samplings with replacement (error bars are small enough that they are hidden behind the dots). Legend indicates the eight fMRI conditions along with the maximum number of frames available. BOLD, blood oxygenation level dependent. Color images are available online.
A very low standard error of mean was observed for all the analyses discussed above (Figs. 3–6), highlighting the generalizability of the optimal regularization magnitude to FCs from different subjects. Optimal regularization magnitude and the corresponding identification rates for REST2 were found to be similar to REST1 (Fig. 7) highlighting the generalizability across different sessions of the same subjects. It should be noted that for both REST1 (Fig. 3) and REST2 (Fig. 7), there is a range of τ where the corresponding identification rates are approximately equal to the optimal identification rate. In addition, the scatter plots between identification rates of REST1 and REST2 show how similarly the two samples behave with respect to τ (Fig. 7; insets).
FIG. 7.

Generalizability: effect of regularization (τ) on identification rates for REST2. Identification rates for the two sessions (LR and RL) from REST2 (utilizing maximum available scanning length) with variable magnitudes of τ, using Destrieux (left; 164 ROIs) and MMP1.0 (right; 374 ROIs) parcellations. Filled circles indicate the mean identification rate, whereas error bars indicate the standard error of the mean across samplings with replacement (error bars are small enough that they are hidden behind the circles). Legend indicates the REST2 condition along with maximum available number of frames. Along each curve, the circle not filled indicates the optimal value of τ, which maximizes the identification rate. The insets in both plots are the scatter plots between REST1 and REST2 of the mean identification rates (across samplings) for the entire range of τ. Both x- and y-axes indicate identification rates and the dotted line is identity line. LR, left to right; REST, resting-state; RL, right to left. Color images are available online.
Discussion
In this work, we explored the effects of different magnitudes of regularization on geodesic distance and subsequently its impact on subject identification rates in FCs. We explored these effects for eight fMRI conditions from the HCP data—resting-state, emotion, gambling, language, motor, relational, social, and working memory. We found that the optimal value of the regularization parameter, which maximized the identification rates, is dependent on the condition, parcellation, scanning length, and the number of frames used to the compute the FCs. In addition, the deviation from the optimal point could affect the identification rates drastically depending on the condition, scanning length, and/or the number of frames used. We also found that the magnitude of optimal regularization is generalizable across different subjects and different sessions of the same subjects, when the acquisition parameters are the same. In short, we found that geodesic distance, which has been shown to be a more accurate way of comparing FCs than canonical methods (Venkatesh et al., 2020), can be further refined by choosing an optimal regularization magnitude for each data set and fMRI condition.
Increased regularization reduces geodesic distance globally and alters relative distances between FCs
Geodesic distance is highly determined by the eigenvalues of the FCs being compared [Eq. (1)]. When those FCs are regularized by adding a constant value to their main diagonal, it increases their eigenvalues by the same amount, thus affecting the geodesic distance between them. As the regularization magnitude increases, the eigenvalues of the FCs, and hence the geodesic distance between them, becomes dominated by it. Since the regularization value added to both FCs is always equal, for a large enough regularization magnitude, their eigenvalues also become approximately numerically equal, leading to a decreased geodesic distance. Intuitively, increasing main diagonal regularization is equivalent to shifting and shrinking the space occupied by the matrices within the manifold. Thus, as the regularization magnitude increases, it was expected that the geodesic distance between FCs would decrease, as observed in Figure 2A.
It was less intuitive that the relative magnitude of the distances would also change with regularization. As the regularization magnitude increased, the relative distance between FCs changed in different directions as shown in Figure 2B with FC Bretest and Cretest. Furthermore, for an optimal value of regularization, the distances between sessions of the same subjects became smaller than between subjects, which lead to better identification of the subjects when comparing the test and the retest sessions, as shown in Figure 2C and D identifiability matrices.
Overall, we can think of increasing regularization as a nonlinear shrinking procedure, which does not preserve relative distances between FCs. By tracking the effects of regularization on three subjects, we demonstrated that the local distance information is not preserved for different magnitudes of regularization (Fig. 2B). This result must be taken into account when using geodesic distance to compare FCs. Then, the question is how to decide what magnitude of regularization to choose? The answer lies in the implicit hypothesis that the FCs from two sessions of the same subject should be closer to each other than FCs from any session of any other subject. If we can find a regularization magnitude where for most subjects, this statement is true, then that is the spot where the distances between FCs are the most meaningful, if not accurate. This optimal spot can be discovered by tracking identification rates as they change with regularization, as was done in this study.
Identification rate is a concave function of the regularization parameter
We observed that for any condition and parcellation, there was a specific value or a range of values for the regularization parameter where identification rate peaked (Fig. 3). In other words, identification rate was a concave function of the regularization parameter for all fMRI conditions and parcellations tested here. We should emphasize that only a limited range of the regularization parameter was tested in this study, for specific conditions and parcellations, and thus, we cannot theoretically guarantee that the optimal levels of regularization found here could be trivially extrapolated to other data sets with different acquisition parameters. But, considering the breadth of the fMRI conditions and the size of the data set used in this study, we are confident that this concave behavior would be replicable in other fMRI data sets as well.
Optimal regularization parameter depends on the specific data set
We observed that the optimal value of the regularization parameter, which maximizes the identification rates, depends on the condition, parcellation, scanning length, and number of frames used to compute the FCs (Figs. 4 and 5 and Tables 2 and 3). Venkatesh and colleagues (2020) used a fixed regularization magnitude (). Here, we show that identification rates can be substantially improved by using data set-dependent regularization parameter. In addition, although Venkatesh and colleagues (2020) employed regularization only when the FCs being compared were rank-deficient, we found that regularization improves identification rates even with full-rank FCs; for example, this was the case of Destrieux parcellation when frames were used to compute FCs.
Longer scanning length leads to more specific values of optimal regularization and to higher identification rates
As the number of samples (or frames chosen sequentially), and hence the scanning length, increases in the time series data, the resultant correlations become more reliable (Bonett and Wright, 2000), and thus, we get better estimates of FCs in the “static” sense of functional connectivity. For all the tasks, we observed that as the scanning length increased, the range of values of τ which resulted in maximized identification rates narrowed down (Figs. 4 and 5). This effect was not as prominent in resting-state, where for most of the scanning lengths evaluated, there was a wide range of values of τ, which resulted in maximum identification rates. This suggests that resting-state FCs, in comparison to tasks, may reside in an intrinsically different region of the semidefinite cone where reallocation of FCs through regularization does not have a sizeable influence on their differentiability.
It should also be pointed out that with optimal values of τ, the optimal identification rates were almost always obtained when using the entire scanning length (two exceptions: resting-state and language using Destrieux parcellation; Tables 2 and 3). Even in the two cases where it was not, the optimal scanning length was marginally smaller than the entire scanning length and the optimal identification rate was approximately equal to the identification rate obtained with maximum scanning length (within margin of error). Intuitively, we can say that the longer the scan acquired, the more information we have about the condition and the subject, which results in higher identification rates.
Number of frames and TR length are not as influential as scanning length
For all conditions, across the two parcellations, when the scanning length was decreased, the identification rates dropped, sometimes drastically (Figs. 4 and 5). Ostensibly, it might seem that this does not hold for resting-state condition, but it is worth noting that resting-state scan is a considerably longer acquisition (14 min and 47 sec compared with second longest, working memory, which is 4 min and 44 sec) than all the tasks and the effect of shorter scanning length comes into play when the reduced scanning length becomes comparable to tasks (around 6 − 7 min). The decrease in identification rate with decreasing scanning length raises a natural question: what would happen if scanning length is maintained but the number of frames is reduced?
The answer is that identification rates are considerably less sensitive to number of frames than the scanning length, when the number of frames is not too small (Fig. 6). To achieve fewer number of frames while maintain the scanning length, we chose alternate time points, with varying gaps, which introduced another variable into the mix: TR. For instance, by choosing every fourth sample from a time series, we are effectively increasing the TR fourfold. So, another conclusion that we could draw from this result is that identification rates are considerably less sensitive to TR length than scanning length. This effect has been observed before by Horien and colleagues (2018) but using Pearson's correlation coefficient as a metric to compare FCs. This knowledge could be helpful in designing scanning protocols where often one has to “sacrifice” spatial resolution for temporal resolution or vice versa. Knowing that as long as one has a long enough scan, perhaps a relatively longer TR could be acceptable in favor of improved spatial resolution, without any detrimental effects to the FC fingerprint.
Regularization counteracts the effect of a coarser grain parcellation on individual fingerprint
Using Pearson's correlation as a similarity metric to compare FCs, Finn and colleagues (2015) showed that a parcellation with more ROIs resulted in higher subject identification rates than a parcellation with fewer ROIs. Venkatesh and colleagues (2020) observed the same trend with both geodesic distance and Pearson's correlation-based dissimilarity. This suggested that finer parcellations lead to more uniqueness or fingerprint, at least up to a certain resolution. In this work, we found that when using a coarser resolution parcellation, we can achieve similar identification rates than a finer resolution parcellation when applying geodesic distance with optimal regularization magnitude.
When computing FCs, an ROI time series is computed by averaging voxel-level time series for all the voxels contained within the ROI. One of the main reasons this is done is to increase the signal-to-noise ratio of the time series under consideration, as the voxel-level time series would be much noisier than an averaged ROI time series. By choosing a finer resolution parcellation, we chose smaller size ROIs and hence compromise on the signal-to-noise ratio in the time series in favor of spatial resolution, compared with a coarse resolution parcellation, where an ROI time series would be computed by averaging over a larger number of voxels. Since by using geodesic distance with optimal regularization, we can overcome the downside of coarse resolution parcellation in terms of fingerprint, perhaps we can favor a relatively coarser parcellation for an improved signal-to-noise ratio while maintaining the individual fingerprint.
Generalizability of the optimal regularization magnitude
Very small differences were observed in the optimal identification rates and the optimal magnitudes of the regularization parameter when different subsamples of the data set were used for subject identification (Figs. 3–6). This highlights that the results for optimal regularization in this study are generalizable to other data sets, given that the scans are acquired with the same or similar parameters. If one is to change the acquisition parameters though, the optimal regularization magnitudes might be different. Using the two sessions from REST2 (not used in any of the former analyses), we were also able to show that the optimal regularization magnitudes and the corresponding identification rates are generalizable to different sessions of the same subjects, even when acquired on different days with the same parameters (Fig. 7). In addition, we observed that optimal identification rates are maintained for the same amount of regularization when the TR length is increased (to a certain extent), and the number of frames is decreased while maintaining the scanning length (Fig. 6). Overall, these findings suggest a generalization of these results to a considerable range of temporal resolution in the BOLD fMRI data.
Comparison with canonical metrics used to compare FCs
With all the canonical methods of comparing FCs (e.g., Pearson's correlation coefficient, Euclidean distance), only the elements in the upper or lower triangular part of the FC are selected and vectorized. This means that regularization has no effect on those metrics since the regularization magnitude is added to the main diagonal, which is ignored by all those metrics. It has already been shown by Venkatesh and colleagues (2020) that geodesic distance outperforms those metrics in uncovering individual fingerprint in FCs. They achieved this using a fixed nonoptimal regularization magnitude (). Our results show that the combination of geodesic distance with an optimal regularization outperforms identification rates and hence above-mentioned canonical metrics by a considerable margin.
How to estimate the optimal regularization parameter and the resulting geodesic distances in a specific study
We have observed that the optimal regularization that leads to maximum identification rates is dependent on the fMRI condition, brain parcellation, scanning length, and the number of frames. There might be other aspects of the data that influence such optimal value as well, such as voxel size. Hence, results suggest that when using geodesic distance to compare FCs, the regularization parameter must be estimated from the FC data of that study. Also, one should utilize sampling techniques to estimate a mean or median magnitude of regularization, along with the corresponding error. Once an appropriate regularization magnitude has been identified, one should regularize all FCs in the data set by that amount and then use geodesic distance to compare FCs. These steps have been tabulated for the benefit of the user of this framework (Table 4). It is important to remark that these resulting pairwise distances are better suited for establishing associations between functional connectivity and cognition, behavior, and neurological diseases at the individual level.
Table 4.
A Step-by-Step Outline of How to Estimate and Apply an Optimal Regularization Magnitude (τ*) to an Functional Connectome Data set, Such That Individual Fingerprint Is Maximized When Using Geodesic Distances to Compare Functional Connectomes
| Step 1 | Estimate test and retest FCs per subject from the fMRI data |
| Step 2 | For a wide range of regularization magnitude (τ): |
| a. Obtain a random sample of the FC data set without replacement* | |
| b. Regularize FCs by that regularization magnitude (τ) | |
| c. Compute pairwise geodesic distances and obtain the identifiability matrix. | |
| d. Estimate identification rate from the identifiability matrix | |
| *Random samplings without replacement are performed to estimate mean behavior (and standard error) of identification rate with respect to the regularization | |
| Step 3 | Identify the optimal regularization magnitude (τ*), such that (mean) identification rate is maximized |
| Step 4 | Regularize all FCs in the data set by the optimal regularization magnitude (τ*) |
| Step 5 | Compare the optimally regularized FCs by using geodesic distance |
| Step 6 | (Optional) For every two subjects, average all four test/retest geodesic distances |
| Step 7 | Use those geodesic distances to establish associations with cognitive/clinical outcomes |
FC, functional connectome; fMRI, functional magnetic resonance imaging.
This process of estimating an optimal regularization from the data themselves, and then applying it back to the same data might seem biased, but we should emphasize that the optimal regularization is estimated to maximize individual fingerprint in the data and nothing else. It is not optimized for any group differences or for any neuro/psychiatric or behavioral score. The only desired output is maximal interindividual differentiability so that the desired effects could be accurately captured at the individual level.
It might also seem desirable to have a constant value of regularization (say 0.1 or 1) that is applicable to all data sets, without any considerable negative effects. But as we have observed, deviations from optimal regularization magnitudes could have detrimental effects on the measured individual fingerprint depending on a variety of factors. Hence, it is always recommended to estimate an optimal regularization magnitude from the data themselves, especially considering that it is extremely easy and computationally efficient to estimate.
Limitations and future work
One limitation of the geodesic distance, whether applied to regularized or unregularized FCs, is that it only provides a single numeric distance estimate between FCs and hence does not allow element-wise (or edgewise) analyses of the FCs (i.e., analysis focused on a particular brain region or a specific functional coupling between two brain regions). Although this limitation can be addressed by projecting FCs from the SPD manifold onto a tangent space of symmetric matrices, which would be Euclidean and allow the use of Euclidean algebra and calculus (Pervaiz et al., 2020; You and Park, 2021). Future work should explore these projections and how they interact with regularization magnitude.
One could also explore the effects of regularization on the identification rates when the test and retest sessions belong to different fMRI conditions (e.g., working memory vs. resting-state), analogous to Finn et al. (2015) and Venkatesh et al. (2020). To estimate the optimal amount of regularization based on functional connectivity fingerprint, one could go beyond test/retest of the same individual and assess identification rates when the test and retest sessions belong to twin pairs (monozygotic or dizygotic). Finally, we can compare this straight forward main diagonal regularization with other kinds of regularization techniques that include off diagonal elements or add a variable amount to the elements of the main diagonal.
Conclusions
The use of the geodesic distance on full-rank or regularized rank-deficient FCs has been shown to be a more principled and accurate method to compare FCs than canonical methods, ultimately leading to improved subject fingerprinting, as measured by identification rates. Here, we combine geodesic distance with optimal regularization to uncover brain connectivity fingerprints by means of an incremental assessment of the magnitude of the regularization parameter. We show that optimal regularization that maximizes subject identification rates is highly data set-dependent—it depends on the fMRI condition, on the brain parcellation used, scanning length, and on the number of frames used to compute the FCs.
Acknowledgments
Data were provided [in part] by the Human Connectome Project, WU-Minn Consortium (Principle Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University.
Previous versions of this article have appeared in a preprint posting on the Cornell University's arXiv.org server, under the Quantitative Biology category, with the subcategory of Neurons and Cognition. The preprint was first uploaded to the server on March 11, 2020, whereas a modified version was updated on August 29, 2020.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
Joaquín Goñi acknowledges financial support from NIH R01EB022574, NIH R01MH108467, Indiana Alcohol Research Center P60AA07611, and Purdue Discovery Park Data Science Award “Fingerprints of the Human Brain: A Data Science Perspective.” Jaroslaw Harezlak has been partially supported by the grant NIH R01MH108467. Enrico Amico acknowledges financial support from the SNSF Ambizione project “Fingerprinting the brain: network science to extract features of cognition, behavior and dysfunction” (Grant No. PZ00P2_185716). Luiz Pessoa's research has been supported by the National Institute of Mental Health (R01 MH071589 and R01 MH112517).
References
- Abbas K, Amico E, Svaldi D, et al. . 2020. GEFF: graph embedding for functional fingerprinting. Neuroimage 221:117181. [DOI] [PubMed] [Google Scholar]
- Allen EA, Damaraju E, Plis SM, et al. . 2014a. Tracking whole-brain connectivity dynamics in the resting state. Cereb Cortex 24:663–676 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Allen NE, Sudlow C, Peakman T, et al. . 2014b. UK biobank data: come and get it. Sci Transl Med 6: 3008601. [DOI] [PubMed] [Google Scholar]
- Amico E, Arenas A, Goñi J. 2019. Centralized and distributed cognitive task processing in the human connectome. Netw Neurosci 3:455–474 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Amico E, Goñi J. 2018. The quest for identifiability in human functional connectomes. Sci Rep 8:8254. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Amunts K, Ebell C, Muller J, et al. . 2016. The Human Brain Project: Creating a European research infrastructure to decode the human brain. Neuron 92:574–581 [DOI] [PubMed] [Google Scholar]
- Bandettini PA, Wong EC, Hinks RS, et al. . 1992. Time course EPI of human brain function during task activation. Magn Reson Med 25:390–397 [DOI] [PubMed] [Google Scholar]
- Bari S, Amico E, Vike N, et al. . 2019. Uncovering multi-site identifiability based on resting-state functional connectomes. Neuroimage 202:115967. [DOI] [PubMed] [Google Scholar]
- Bhatia R. 2009. Positive definite matrices. In: Daubechies I, Weinan E, Lenstra JK, Süli E (eds.) Positive Definite Matrices. Princeton, NJ: Princeton University Press; pp. 205–206 [Google Scholar]
- Bonett DG, Wright TA. 2000. Sample size requirements for estimating Pearson, Kendall and Spearman correlations. Psychometrika 65:23–28 [Google Scholar]
- Bravais A. 1846. Mathematical Analysis on the probabilities of the situation errors of a point. In Memories presented by various scientists. The Royal Academy of Sciences of the Institute de France (Vol 9) [in French]. Paris, France: Royal Printing Press; pp. 255–332 [Google Scholar]
- Cole MW, Bassett DS, Power JD, et al. . 2014. Intrinsic and task-evoked network architectures of the human brain. Neuron 83:238–251 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Destrieux C, Fischl B, Dale A, et al. . 2010. Automatic parcellation of human cortical gyri and sulci using standard anatomical nomenclature. Neuroimage 53:1–15 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Finn ES, Shen X, Scheinost D, et al. . 2015. Functional connectome fingerprinting: identifying individuals using patterns of brain connectivity. Nat Neurosci 18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fornito A, Bullmore ET. 2015. Connectomics: a new paradigm for understanding brain disease. Eur Neuropsychopharmacol 25:733–748 [DOI] [PubMed] [Google Scholar]
- Fornito A, Zalesky A, Breakspear M. 2015. The connectomics of brain disorders. Nat Rev Neurosci 16:159–172 [DOI] [PubMed] [Google Scholar]
- Fornito A, Zalesky A, Bullmore ET. 2016. Fundamentals of Brain Network Analysis. In: Fornito A, Zalesky A, Bullmore ET (eds.) Fundamentals of Brain Network Analysis. London, UK: Elsevier Sciences; pp. 1–2 [Google Scholar]
- Frahm J, Bruhn H, Merboldt K-D, et al. . 1992. Dynamic MR imaging of human brain oxygenation during rest and photic stimulation. J Magn Reson Imaging 2:501–505 [DOI] [PubMed] [Google Scholar]
- Galton F. 1886. Regression towards mediocrity in hereditary stature. J Anthropol Inst Great Britain Ireland 15:246 [Google Scholar]
- Glasser MF, Coalson TS, Robinson EC, et al. . 2016. A multi-modal parcellation of human cerebral cortex. Nature 536:171–178 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Glasser MF, Sotiropoulos SN, Wilson, et al. 2013. The minimal preprocessing pipelines for the Human Connectome Project. Neuroimage 80:105–124 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gratton C, Laumann TO, Nielsen AN, et al. . 2018. Functional brain networks are dominated by stable group and individual factors, not cognitive or daily variation. Neuron 98:439–452.e5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Horien C, Noble S, Finn ES, et al. . 2018. Considering factors affecting the connectome-based identification process: Comment on Waller et al. Neuroimage 169:172–175 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kwong KK, Belliveau JW, Chesler DA, et al. . 1992. Dynamic magnetic resonance imaging of human brain activity during primary sensory stimulation. Proc Natl Acad Sci U S A 89:5675–5679 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marcus DS, Harwell J, Olsen T, et al. . 2011. Informatics and data mining tools and strategies for the human connectome project. Front Neuroinform 5:4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mars RB, Passingham RE, Jbabdi S. 2018. Connectivity fingerprints: From areal descriptions to abstract spaces. Trends Cogn Sci 22:1026–1037 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miller KL, Alfaro-Almagro F, Bangerter NK, et al. . 2016. Multimodal population brain imaging in the UK Biobank prospective epidemiological study. Nat Neurosci 19:1523–1536 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ogawa S, Lee TM, Kay AR, et al. . 1990. Brain magnetic resonance imaging with contrast dependent on blood oxygenation. Proc Natl Acad Sci U S A 87:9868–9872 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ogawa S, Tank DW, Menon R, et al. . 1992. Intrinsic signal changes accompanying sensory stimulation: functional brain mapping with magnetic resonance imaging. Proc Natl Acad Sci U S A 89:5951–5955 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Okano H, Miyawak A, Kasai K. 2015. Brain/MINDS: Brain-mapping project in Japan. Philos Trans R Soc B Biol Sci 370: 20140310. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pallarés V, Insabato A, Sanjuán A, et al. . 2018. Extracting orthogonal subject- and condition-specific signatures from fMRI data using whole-brain effective connectivity. Neuroimage 178:238–254 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pennec X, Fillard P, Ayache N. 2006. A riemannian framework for tensor computing. Int J Comput Vis 66:41–66 [Google Scholar]
- Pervaiz U, Vidaurre D, Woolrich MW, et al. . 2020. Optimising network modelling methods for fMRI. Neuroimage 211:116604. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ponsoda V, Martínez K, Pineda-Pardo JA, et al. . 2017. Structural brain connectivity and cognitive ability differences: A multivariate distance matrix regression analysis. Hum Brain Mapp 38:803–816 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Poo, M. ming, Du, J. lin, Ip NY, et al. . 2016. China Brain Project: Basic neuroscience, brain diseases, and brain-inspired computing. Neuron 92:591–596 [DOI] [PubMed] [Google Scholar]
- Power JD, Mitra A, Laumann TO, et al. . 2014. Methods to detect, characterize, and remove motion artifact in resting state fMRI. Neuroimage 84:320–341 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rajapandian M, Amico E, Abbas K, et al. . 2020. Uncovering differential identifiability in network properties of human brain functional connectomes. Netw Neurosci 4:698–713 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Satterthwaite TD, Xia CH, Bassett DS. 2018. Personalized neuroscience: Common and individual-specific features in functional brain networks. Neuron 98:243–245 [DOI] [PubMed] [Google Scholar]
- Seitzman BA, Gratton C, Laumann TO, et al. . 2019. Trait-like variants in human functional brain networks. Proc Natl Acad Sci U S A 116:22851–22861 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shen X, Finn ES, Scheinost D, et al. . 2017. Using connectome-based predictive modeling to predict individual behavior from brain connectivity. Nat Protoc 12:506–518 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith SM, Beckmann CF, Andersson J, et al. . 2013. Resting-state fMRI in the Human Connectome Project. Neuroimage 80:144–168 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sporns O. 2018. Discovering the Human Connectome. In: Sporns O (ed.) Discovering the Human Connectome. Cambridge, MA: The MIT Press; pp. 28–29 [Google Scholar]
- Svaldi DO, Goñi J, Abbas K, et al. . 2019. Optimizing differential identifiability improves connectome predictive modeling of cognitive deficits in Alzheimer's disease. arXiv Preprint arXiv:1908.06197 [DOI] [PMC free article] [PubMed] [Google Scholar]
- van den Heuvel MP, Sporns O. 2019. A cross-disorder connectome landscape of brain dysconnectivity. Nat Rev Neurosc 20:435–446 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Essen DC, Smith SM, Barch DM, et al. . 2013. The WU-Minn Human Connectome Project: An overview. Neuroimage 80:62–79 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Essen DC, Ugurbil K, Auerbach E, et al. . 2012. The Human Connectome Project: A data acquisition perspective. Neuroimage 62:2222–2231 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Venkatesh M, Jaja J, Pessoa L. 2020. Comparing functional connectivity matrices: A geometry-aware approach applied to participant identification. Neuroimage 207:116398. [DOI] [PMC free article] [PubMed] [Google Scholar]
- You K, Park HJ. 2021. Re-visiting Riemannian geometry of symmetric positive definite matrices for the analysis of functional connectivity. Neuroimage 225:117464. [DOI] [PubMed] [Google Scholar]
- Zuo XN, He Y, Betzel RF, et al. . 2017. Human Connectomics across the Life Span. Trends Cogn Sci 21:32–45 [DOI] [PubMed] [Google Scholar]