

Abstract
To mitigate the substantial post-processing burden associated with adaptive optics scanning light ophthalmoscopy (AOSLO), we have developed an open-source, automated AOSLO image processing pipeline with both “live” and “full” modes. The live mode provides feedback during acquisition, while the full mode is intended to automatically integrate the copious disparate modules currently used in generating analyzable montages. The mean (±SD) lag between initiation and montage placement for the live pipeline was 54.6 ± 32.7s. The full pipeline reduced overall human operator time by 54.9 ± 28.4%, with no significant difference in resultant cone density metrics. The reduced overhead decreases both the technical burden and operating cost of AOSLO imaging, increasing overall clinical accessibility.
1. Introduction
Adaptive optics (AO) has ushered in a new era of ophthalmic investigation due to its ability to image the living retina with unprecedented resolution by correcting the monochromatic aberrations of the eye [1]. This technology was first applied to a fundus camera and improved visualization of human photoreceptors [2]. AO was then applied to the confocal scanning laser ophthalmoscope (AOSLO) which conferred a substantial improvement in contrast [3,4], with lateral resolutions as low as ∼2µm [5]. The AOSLO raster scans a nearly diffraction-limited spot on the retina and detects the reflected light through a confocal aperture. Because of this design, the light levels of an AOSLO must be kept low to prevent phototoxicity, resulting in relatively low SNR, and some degree of distortion will always be present due to eye motion during scanning [6]. Further, regardless of the type of AO device, the small field-of-view (FOV) requires acquisition of images at multiple retinal locations and stitching these images together to form a retinal montage from which regions-of-interest (ROIs) may be selected for analysis [7,8]. These limitations may be partially mitigated by various image processing and registration algorithms, but the amount of user input currently required renders this process costly and inefficient. Reduction of the overhead associated with AOSLO imaging would be a boon to its advancement and utility in the clinic.
While most modules of the AOSLO image processing workflow have each been automated, to our knowledge, no fully automated pipeline exists to connect these modules (Fig. 1). Modules including correction of static sinusoidal distortion [9], non-confocal modality combination [10,11], reference frame selection [12,13], registration [14–16], statistical distortion correction [17,18], and montaging [7,8] have been automated, yet significant barriers remain. Most algorithms require manual selection of parameters and the outputs of one algorithm often need to be reformatted manually before they can be accepted as an input for the next algorithm in the workflow. Bridging modules and automating parameter selection using a combination of image analysis and optimization could relieve most (if not all) of the burden of manual image processing of AOSLO images. Additionally, the use of AO imaging in animals is increasing [19–22], which presents new challenges. Without the ability to direct the subject’s gaze, estimating retinal location and the extent of retinal area imaged further complicates acquisition and can result in missing data.
Fig. 1.

Typical workflow for our group when processing an AOSLO dataset. After acquiring images, raw video channels are combined into secondary (2°) modalities, calibration files are created to correct for sinusoidal distortion (“desinusoiding”), reference frames are selected for registration and averaging using a strip-based registration algorithm. High-SNR images are subjected to a statistical distortion correction, then stitched together into a larger montage from which regions-of-interest are selected. Cone centers are estimated, and metrics related to cone geometry can be used to assess photoreceptor health. Feedback (dashed lines) from several modules requires adjusting parameters from a previous module which may be especially time-consuming.
We sought to develop a fully automated image processing pipeline to mitigate some of these challenges. Here, we present two workflows optimized for speed or accuracy depending on the context, an updated reference frame selection algorithm, and a novel algorithm for determining parameters for registration. These algorithms were tested on datasets from control subjects with no self-reported vision-limiting pathology, subjects with achromatopsia (ACHM) or albinism, and thirteen-lined ground squirrels (13-LGS). The source code for this pipeline has been made available in an effort to advance the field of AO retinal imaging [23].
2. Methods
2.1. Adaptive optics scanning light ophthalmoscopes (AOSLO) and demographics
Two previously described AOSLO systems (one for humans, one for animals) were used to acquire the images used in this study [5,19]. Both use an 850nm superluminescent diode as the wavefront sensing source, a near-infrared reflectance imaging source between 775-790nm, a Shack-Hartmann wavefront sensor (Rolera-XR; QImaging, Surrey, BC, CAN), and a 97-actuator deformable mirror (ALPAO, Montbonnot-Saint-Martin, France). Fast horizontal scanning is achieved by a resonant scanning mirror (SC-30; Electro-Optical Products Corp., Fresh Meadows, NY), and slow vertical scanning by a piezo tip/tilt mirror (S-334.2SD; PI USA, Auburn, MA); both systems have a maximum FOV of 2 × 2°. The central point-spread function (PSF), which represents directly back-scattered signals [24], is detected by a photomultiplier tube (Hamamatsu Photonics, Hamamatsu City, JPN), and the periphery of the PSF is split into two channels referred to as “direct” and “reflect” which can be combined to form dark-field [10] or split-detector images [11]. The human AOSLO system has a 7.75mm system pupil and achieves a maximum lateral optical resolution in tissue of 2.4µm, whereas the animal AOSLO system has a 4.5mm system pupil and yields a lateral optical resolution of 1µm in the 13-LGS. Full demographic information for the human subjects and 13-LGS included in this study are given in Dataset 1 (149.2KB, xlsx) [25]. Across all human subjects, the µ±σ age was 27.8 ± 11.7 years (36 female, 24 male); for all 13-LGS animals, the µ±σ age was 1.2 ± 0.7 years (6 female, 8 male).
2.2. Pipeline types
We sought to develop two separate frameworks for the pipeline. The first is a faster/coarse version, henceforth referred to as Live-AO-pipe, which is meant to be run concurrently with image acquisition. The goal of this version is to assist operators in collecting a “montage-able” dataset that is free of gaps and non-overlapping images. This can be especially difficult when imaging animals due to the inability to direct fixation to a precise location of the visual field (to image different retinal locations in anesthetized animals, the animals are rotated about the eye in a custom stage while the operator tracks some retinal image feature to assess overlap between videos; imperfections in the plane of anesthesia, stage friction, or a lack of unique features may complicate this process). The second is a slower/fine version named Full-AO-pipe that would produce a montage of images with high SNR and reduced distortion for use in analysis of metrics such as cone density. AO-pipe was developed as a separate application rather than an integration with acquisition software in an attempt to be accessible to a wider range of laboratories and AOSLO system builds. The framework for AO-pipe was developed in Matlab 2019b (MathWorks, Natick, MA) and uses the following toolboxes (Image Processing Toolbox v11.0, Parallel Computing Toolbox v7.1, and Statistics and Machine Learning Toolbox v11.6). It also currently requires CUDA toolkit version 10.1 or later, and installation of a strip-registration algorithm implemented in python 2.7 (DeMotion [16]) and a fast automontager implemented in python 3.7 (UCL Automontager [8]).
2.3. Live-AO-pipe architecture
For Live-AO-pipe, image processing occurs concurrently with acquisition. The folder structure and files on the acquisition computer are continuously copied to a server to which a processing computer has access (Fig. 2). On the processing computer, three modules are run concurrently as service processes: calibration, de-noising, and montaging. The goal of the calibration service is to correct static sinusoidal distortion caused by the resonant scanner in our system. Short videos (∼10 frames) of a Ronchi ruling with known spacing in a horizontal and vertical orientation must be acquired at each FOV intended for use in the retina. These videos are automatically detected and paired according to their orientation (determined by a file naming convention). Frames are averaged and the resulting images are averaged along the orientation of the ruling. Local minima are detected and fit to a linear or sinc function, depending on the orientation. These functions are combined to create a “desinusoid matrix” which may be multiplied by subsequent AOSLO videos to obtain a resampled video with 1:1 pixel spacing.
Fig. 2.

Live-AO-pipe workflow. A service running on the acquisition PC continuously identifies and copies new files to a server without interrupting the acquisition process. On the processing PC, these files are identified, categorized, and added to a database object. Tasks are assigned based on unprocessed files. The code next to each service title (e.g., [1:C]) indicates the priority and maximum number of cores (C) allowed for parallel processing. Calibration videos are collected and processed to correct sinusoidal distortion induced by the resonant scanner. Retinal images are collected and de-noised (by registration and averaging) to obtain higher-quality images to increase the fidelity of montaging. Adjacent images are then stitched together to form a montage to provide timely feedback on image quality and gaps in acquisition. This typically results in 1 core reserved for updating the montage and the remaining cores dedicated to de-noising images. See Visualization 1 (28.8MB, avi) for a demonstration.
The goal of the “de-noising” service is to produce high-SNR images from each video. Excellent registration performance has been demonstrated using strip-registration [14,16,26], however the current implementation of the strip-registration algorithm is computationally expensive as it calculates full-frame normalized cross-correlation (NCC) matrices for all source frames in a video, then calculates NCC matrices between the template frame and each strip of the best n source frames. Even when using custom CUDA-enabled GPU processing, this process requires on the order of minutes to average a large number of frames, which is impractical for real-time feedback. Improvement in SNR by averaging typically follows a sqrt(n) curve. Because of this, the greatest rate of improvement occurs after a small number of frames are averaged. Given these factors, we tested a new strategy which takes advantage of the data generated by the automated reference frame selection (ARFS) algorithm [13], which is described in more detail in Section 2.5. Briefly: high-quality, minimally distorted frames are identified and sorted into spatial clusters, and the highest-quality frame from each cluster is used as a template frame for registration and averaging. Video snippets containing this reference frame and a small number (n, which can be adjusted by the user; the default is 5) of highly correlated and proximal frames are written and input to DeMotion. An initial strip size of 25 pixels is used with repeated measurements every 10 pixels. This corresponds to a sampling frequency of ∼1kHz in our system, which is typically sufficient to obtain segments undistorted by normal levels of tremor and drift [16]. If the height of the resultant image is less than half the original frame height, the number of rows per strip is doubled and re-processed (but the spacing between successive measurements remains constant). This continues until the image height is not increased, or the lines per strip exceeds one third of the original frame height. Eye motion is substantially slower in the anesthetized 13-LGS, and low-n, full-frame registration has exhibited good performance. Full-frame registration is much faster than strip-registration and thereby improves overall performance for datasets from this species. Only the confocal modality is used for motion estimation in this service. Once a registered, averaged, and cropped image is produced which passes the success criteria (n frames registered and the image height is over half the original video frame height), only the corresponding n frames from the “direct” and “reflect” videos are read into memory for the construction of “dark-field” [10] and “split-detector” [11] images. The motion correction computed using the confocal channel is applied to the direct and reflect n-frame substack, averaged, and cropped, then combined (pixel-wise average for dark-field, and the difference over the sum for split-detector). This is contrary to the conventional approach where the secondary modalities (dark-field and split-detector) are created prior to registration and the transforms computed using the primary (confocal) modality are applied to the entire stack of each secondary modality, then separately averaged. This approach was selected to save time but precludes the optional use of the dark-field or split-detector modality for performing the motion estimation.
In the final service, denoised images are compiled into a montage. Expected retinal locations for each image are continually written to a comma-separated file by an integrated fixation module (this could also be done manually if the users have a different fixation system). Registration between overlapping images is estimated using a custom implementation of a fast multimodal automontager which identifies “oriented-FAST and rotated-BRIEF” (ORB) features [8,27] and computes the translational offset between them. In the first iteration of the montaging service, an initial montage is generated using all detected new images. In subsequent iterations, newly detected images as well as previously montaged images that are expected to overlap with the new images by greater than 25%, are input to the automontager. Successful registrations are then incorporated into the full montage and the display is updated for the user (Visualization 1 (28.8MB, avi) ). Images at redundant locations that were not successfully montaged are assumed to be unnecessary and are ignored in the display. Retinal locations which could not be connected by the automontager are displayed to the operators as a suggestion for re-acquisition.
Each service has a priority and a maximum number of allowed CPU cores for parallel processing. The number of available cores (C) is an adjustable parameter on the GUI before a session is initiated, and it is recommended that at least one core is reserved for the operating system. Tasks are first allocated to the calibration service (which has first priority) and may use up to C cores, as the output of this step is a prerequisite for the subsequent services. The montaging service has second priority but is only allowed one core, thereby handling batches of new images in a serial fashion as they become available. The de-noising service, which is the most computationally expensive, has third priority and may use all remaining available cores. During a typical imaging session, the calibration files are generated quickly, allowing the montaging service to continuously run on one core, and the de-noising service to run continuously on C-1 cores. This design efficiently allocates resources according to typical workflows while maintaining the flexibility to acquire new calibration videos at any time in the event that an unexpected FOV is desired. When finished, the Live-AO-pipe GUI includes an option to start a new session or initiate Full-AO-pipe on the current dataset.
2.4. Full-AO-pipe architecture
The primary goal of Full-AO-pipe is to produce a montage of high-SNR images with minimal distortion and has less of an emphasis on speed. However, since no new inputs are expected, several time-saving efficiencies may be implemented. At this point, it can be assumed that all images in the dataset are collected, so no time is spent continuously looking for new inputs, and the modules are run in series to avoid redundancy (Fig. 3). Full-AO-pipe can operate independently of Live-AO-pipe but may utilize outputs from redundant modules such as desinusoiding or ARFS if the live mode was used previously.
Fig. 3.

Full-AO-pipe workflow. This workflow assumes all input files have been collected at the time of initiation. The overall framework is serial, but each main module utilizes parallel processing. Key differences between the full and live pipeline includes the creation of secondary modalities which can be used for motion estimation, a higher number of frames are used for de-noising, a statistical intraframe motion correction step is included, and the montaging algorithm is more exhaustive. The montage is then output to Photoshop (PS) for inspection and correction.
Occasionally, it may be advantageous to perform the motion estimation and strip-registration on one of the non-confocal modalities, then apply the registration transformations to all other modalities, particularly in regions of disrupted outer segment waveguiding [24] as is common in patients with ACHM [28], macular telangiectasia [29], or macular hole [30]. For this reason, it becomes necessary to construct split-detector and dark-field videos, rather than construct these from registered and averaged images of the direct and reflect channels as we did in the live mode. Users are given the option to set the modality order for motion estimation.
For registration and averaging, the goal now is to maximize SNR and image area while minimizing registration error. The best frame from every spatial cluster identified by the ARFS algorithm is used as a reference frame for DeMotion. If the dataset had previously been processed with ARFS within Live-AO-pipe, the output will be loaded without re-running. The highest ranked frames from each spatial cluster will then be input to DeMotion. The strip-motion estimation module of DeMotion is performed but is not yet used in the generation of a registered image. The distribution of NCC maxima for each strip is collected and an NCC threshold is set at one standard deviation above the mean. The averaged image would then be generated and automatically judged according to the following criteria: (1) no errors occurred in the strip-registration process (e.g., failure to find a cropping region), (2) the number of frames that contributed a strip with an NCC exceeding the threshold is greater than a user-defined level, and (3) the image size along the slow-scan axis is greater than 2/3 the original. If the strip size exceeds 1/3 the original frame height, the registration is deemed a failure, and the next modality is used for motion estimation. If all modalities fail, no image is produced, and a warning message is displayed.
Upon successful image generation, an attempt is made to correct for residual distortion that was present in the reference frame. We developed a custom implementation of a “de-warping” algorithm based on previous work [17,18,26]. One key modification made to the algorithm includes the use of the median (as opposed to the mean) transformation magnitude to compute the bias in an effort to mitigate outliers introduced by registration errors. These algorithms assume that eye motion is randomly distributed about the point of fixation. There is reasonable evidence that this is valid for healthy control subjects [17,18,31,32], but less so for subjects with pathological nystagmus and fixational instability. Based on the results of an independent validation experiment including subjects with nystagmus (described fully in Section 2.6), we decided to include this module regardless of a subject’s fixational stability.
All “successfully” processed images are input to a SIFT-based automontager (v1.4) [7]. This is a more exhaustive algorithm than the ORB-based automontager [8] used in the live mode; it ensures the best alignment is found by comparing more images but requires substantially more time. Rigid registration is allowed which accounts for slight rotations of the subject’s head (which is particularly important in 13-LGS). Upon completion, the automontager automatically exports images to Adobe Photoshop CS6 (Adobe Inc., San Jose, CA), and image triplets (confocal, split-detector, and dark-field) are linked, and grouped by FOV for convenient manual refinement.
2.5. Revisions to an automated reference frame selection (ARFS) algorithm
The purpose of the ARFS algorithm is to automatically select reference frames for registration and averaging of AOSLO image sequences [13]. ARFS attempts to identify minimally distorted reference frames in spatially distinct clusters to produce high quality images and increase the coverage of the retina. The original ARFS algorithm required ∼2-8 minutes/video depending on eye-motion, which would not be practical for implementation in Live-AO-pipe. We sought to increase the speed without a significant loss in performance, and this was primarily achieved by processing on a GPU, relying on inter-frame decorrelation as an inference of distortion, and relaxing the motion-tracking/registration procedure.
The first module of ARFS removes any lost frames (which occasionally occur due to acquisition lags and manifest as duplicates in the .avi file) and rejects frames based on image quality metrics including mean intensity, contrast, and sharpness (Fig. 4(A)). Contrast was defined as the standard deviation divided by the mean intensity for all pixels in a frame [12]. Sharpness was defined as the mean gradient magnitude after a frame was convolved with a Sobel filter [33]. A frame was rejected if its value for a given metric was 3 standard deviations below the mean. Each metric was assessed only on the frames that had not been rejected by a previous metric and the metrics were measured in increasing order of computational complexity.
Fig. 4.

Revised ARFS algorithm and determination of registration threshold. (A) ARFS workflow. The input is a 3D array of intensities with M height, N width, and T frames. Duplicate frames and frames which are lower outliers (µ-3σ) are rejected. Inter-frame motion is estimated in the “getMT” module by computing the phase correlation between frames. An empirically determined threshold was used to decide whether a phase correlation was sufficient to trust a registration. The phase correlation coefficient (PCC) is also used as a metric of intraframe distortion, and lower PCC outliers are rejected. Frames are then sorted into spatial clusters, refined, and the frames with the highest PCC per cluster are output. (B) Method for determining the aforementioned PCC threshold. Videos from isoeccentric locations were randomly interleaved, and the PCC between intra- and inter-video frame pairs were computed. (C-E) PCC threshold distributions for confocal, split-detector, and dark-field videos. The PCC threshold for each modality was defined as three standard deviations above the mean of all inter-video frame comparisons. This relatively conservative threshold increases the likelihood of false negatives (rejecting adequately registered frames), which is less deleterious for our purposes than false positives (accepting poorly registered frames). Distributions have worse separation for non-confocal modalities due to their lower SNR and contrast.
The second module estimates the spatial position of each frame for determination of spatially distinct clusters. Previously, this was performed with an NCC-based approach that was computationally expensive and overly complex. The new workflow incorporates a simplified phase-correlation-based approach that minimizes the number of redundant Fourier transforms, which was found to increase speed at a slight loss to registration accuracy. A successful registration was previously determined by a custom peak-finding algorithm in the NCC matrix; however, in most cases, an empirically derived threshold for maximum correlation between frames is sufficient. We determined a threshold empirically for each modality (confocal, split-detector, and dark-field), by randomly interleaving frames from non-overlapping, isoeccentric videos from 11 healthy control subjects (Dataset 1 (149.2KB, xlsx) [25]; µ±σ age: 30.0 ± 6.9 years) and measuring the phase-correlation coefficient (PCC) between subsequent frames (Fig. 4(B)). The frames were interleaved such that there would be a 2:1 ratio of intra- to inter-video comparisons, as some proportion of intra-video comparisons would be non-overlapping due to normal eye-motion. The threshold was set to be 3 standard deviations above the mean for all inter-video PCCs and the distributions were plotted to demonstrate a good separation between intra- and inter-video comparisons (Fig. 4(C)).
As in the original algorithm, key frames from each group of successfully registered frames are compared (again by phase-correlation), in an attempt to combine groups of frames. The key frame for each group was defined as the frame with the highest PCC in the group. Proceeding in descending order of frame group size, the PCC between key frames across groups is measured, and if the threshold is exceeded, the smaller group is absorbed. Spatial positions of all frames in an absorbed group are shifted based on the registration between the key frames of the absorbing group and the absorbed group. As in the original algorithm, an initial clustering is determined by k-means [34], and over-clustering is mitigated by allowing clusters to absorb frames in other clusters that overlap by ≥ 75% (which also proceeds in order of descending cluster size). Frames belonging to clusters with fewer than a user-defined threshold were rejected. Reference frames were then defined as the frame with the highest inter-frame PCC value per cluster. In the event that there are no clusters with more frames than the user-defined threshold, the algorithm outputs the frame with the highest PCC value overall.
2.6. Effect of intraframe motion correction (de-warping) on residual distortion
Statistical correction of intraframe motion relies on the assumption that eye motion is spatially random about the center of fixation [17,18]. We sought to assess the performance of such a “de-warping” algorithm and determine whether intraframe motion could be corrected in subjects with pathological nystagmus. A custom implementation of the de-warping algorithm [35] was used on multiple reference frames from the same video in 10 human subjects with no known ocular pathologies, as well as 20 subjects with ACHM (Fig. 5(A); Dataset 1 (149.2KB, xlsx) [25]). As part of a standard protocol in imaging subjects with conditions that typically exhibit nystagmus, the acquisition operators would note the nystagmus severity. These notes were used to stratify subjects into “mild” (ACHMmild) and “moderate-severe” (ACHMm-s) eye-motion categories. All designations were made prior to the initiation of this study. The µ±σ ages for control, ACHMmild, and ACHMm-s groups were 29.5 ± 3.2, 32.9 ± 15.7, and 22.5 ± 9.3 years, respectively. Confocal videos acquired at 1° temporal to the foveola (1°T) were processed by the updated ARFS algorithm to obtain the largest cluster of frames. Two metrics of frame distortion were measured in each frame: inter-frame PCC and intra-frame motion (IaFM) from the original ARFS algorithm [13]. Two minimally distorted frames (best) and two representative frames (median) according to each metric, as well as two randomly selected frames were extracted from the largest cluster. These were then each used separately as the reference frame for strip-registration to produce five image pairs (PCCbest, PCCmed, IaFMbest, IaFMmed, and Random). The NCC between frame pairs was measured before and after de-warping, operating under the assumption that independent intra-frame distortion mitigation would increase the correlation between images (Fig. 5(B)). De-warping improved image pair correlation in 98% of cases. Image pairs whose correlation improved after de-warping (n = 147) improved by 5.5 ± 3.6%, whereas image pairs whose correlation decreased after de-warping were reduced by 4.4 ± 4.5%. It should be noted that de-warping performance is dependent on strip-registration accuracy; while improved quality of each registered and averaged image was verified, the accuracy of alignment for each strip was not assessed here. The effect of reference frame selection type on de-warping performance was assessed by n-way ANOVA with a Tukey post-hoc test for multiple comparisons. Relative to controls, post-dewarping NCC was similar for the ACHMmild group (p = 0.73) but significantly lower in the ACHMm-s group (p = 1E-4). PCCbest frames resulted in significantly higher NCC post-dewarping compared to randomly selected frames (p = 0.016) but were not significantly different than the other frame selection methods. For these reasons, the de-warping module was incorporated into the pipeline regardless of subject condition.
Fig. 5.

De-warping algorithm performance assessment. (A) We recruited 10 subjects with normal vision (CTRL), 10 with achromatopsia and mild nystagmus (ACHMmild), and 10 with achromatopsia and moderate-severe nystagmus (ACHMm-s; Dataset 1 (149.2KB, xlsx) [25]). Frames from confocal videos obtained (1°T) were sorted into spatial clusters by ARFS. In the largest cluster, frame distortion was measured using two metrics: interframe phase correlation coefficient (PCC) and “intraframe motion” (IaFM). For each video, 2 minimally distorted (Best) and 2 representative (Median) frames were selected according to each distortion metric. Additionally, 2 other frames were randomly selected, resulting in a total of 5 frame-pairs per video. All 10 frames were separately used as a reference frame for strip-registering and averaging the video. The normalized cross-correlation (NCC) between the resultant image pairs was measured before and after dewarping. (B) De-warping resulted in an increased NCC between image pairs in 147 (98%) comparisons. Relative to controls, post-dewarping NCC was similar for the ACHMmild group (p=0.73) but significantly lower in the ACHMm-s group (p=1E-4). PCC best frames resulted in significantly higher NCC post-dewarping compared to randomly selected frames (p=0.016) but were not significantly different than the other frame selection methods. Boxes: interquartile range (IQR; 25th-75th percentile); dashed line: median; whiskers: limits of observations excluding outliers (+) defined as an observation 1.5*IQR away from the 25th or 75th percentile.
2.7. Subject inclusion and exclusion criteria
This study was approved by the Institutional Review Board (IRB) of the Medical College of Wisconsin (MCW) and was conducted in accordance with the tenets of the Declaration of Helsinki. Informed consent was obtained for all subjects once the nature and risks of the study were explained. Experimental procedures involving animal subjects were approved by the MCW Institutional Animal Care and Use Committee and were in accordance with the ARVO Statement for the Use of Animals in Ophthalmic and Vision Research. Representative datasets that matched the following inclusion and exclusion criteria were extracted from the existing MCW databank.
For inclusion in this study, any human subject must have been ≥ 5 years old at the time of imaging. Control subjects had no vision limiting pathology and normal retinal appearance on clinical imaging. Subjects with ACHM were included for consideration if their diagnosis included a mutation in cyclic nucleotide gated channel A3 or B3. Subjects with albinism were included for consideration if their diagnosis was listed as albinism, ocular albinism, or oculocutaneous albinism, but was not limited to a specific underlying genetic cause. The imaging protocol (one eye per subject) must have included at least a 2 × 2° grid approximately centered on the fovea, a temporal strip extending to 9° and a superior strip extending to 5°. For the retrospective assessment of AO-Pipe-full performance (Section 2.9), an intact montage that was generated independently and prior to the initiation of this study was required, whereas this was not required for the prospective assessment (Section 2.8).
For inclusion in this study, a wild-type 13-LGS animal must have been ≥ 6 weeks old at the time of AOSLO imaging, with imaging taking place between the months of March to September (to avoid confounds associated with torpor [36,37]). All retinal locations were manually recorded at the time of imaging and transcribed to match the output of the fixation target used in the human AOSLO system. The imaging protocol (one eye per animal) must have included at least one video centered on the optic nerve head (ONH); however, for the prospective analysis, a horizontal strip covering the ONH that extended ∼4° was required. Additionally, at least an inferior strip extending 9° from the ONH was required.
2.8. Prospective comparison of automatically and manually processed datasets
To determine human time-savings and output dataset quality, we performed a prospective comparison of manually processed datasets, and those processed with Full-AO-pipe. This comparison was performed on datasets from 3 healthy human subjects and 3 healthy 13-LGS (Dataset 1 (149.2KB, xlsx) [25]; Human: µ±σ age: 29.5 ± 5.8 years; 13-LGS: µ±σ age: 2.1 ± 1.2 years). For each species, we selected 2 operators to process these datasets. Each dataset was duplicated so that it could be processed manually and automatically by each operator, then the order of the 6 datasets per operator was randomized and de-identified. These operators were tasked with generating a fully intact montage of high-quality images manually or automatically, including a manual feedback step after each module (see Supplement 1 (1.2MB, pdf) for the instructions given to these operators [25]). Operators were instructed to time themselves interacting with the data and software, stopping the timer whenever they were passively waiting for a module to finish processing data. For datasets processed with AO-Pipe-full, operators were instructed to time themselves initiating the program, as well as replacing any poor-quality or misaligned images in the montage. This testing was carried out on 4 separate computers with identical specifications (data was stored and processed on a local solid-state drive of a machine with 64-bit Windows 10, 32GB RAM, Intel i9-9900K 8-core CPU at 3.6GHz, and an NVIDIA GeForce GTX 1650 GPU with 4GB of dedicated memory). Computers were accessed remotely due to the COVID-19 pandemic and all operators reported that this did not impede their ability to manually process datasets. Once all montages were finalized, user-interaction time, total processing time, the number of initial montage disconnections, and final montage area was measured.
Finalized montages were then prepared for another operator (JC) for ROI extraction. Method identifying tokens were removed from all layer names in each montage (AO-pipe includes extra labels in file names for record-keeping purposes). For each subject, one of the manually processed datasets was randomly selected for determination of a reference point. For human subjects, this is typically the foveal center, and for 13-LGS, this is typically the middle of the ONH in a horizontal position aligned with the superior/inferior strip collected. Once the reference point was selected in one dataset, it was marked on an image at that location, and that image was duplicated to the other 3 datasets from the same subject and placed on the canvas in a non-overlapping location. For a montage in which the reference point was originally determined, the operator was instructed to generate ROIs at defined eccentricities from the reference point (for humans: 0.25 × 0.25° ROIs at 1°T, and 0.4 × 0.4° at 3°T, 9°T, and 5°S; for 13-LGS: 0.5 × 0.5° ROIs at 3, 5, 7, and 9°I) and adjust them according to a standard set of rules (see Supplement 1 (1.2MB, pdf) for instructions given to the ROI-extracting operator [25]) using custom software (Mosaic v0.6.9.3; Translational Imaging Innovations, Hickory, NC). The sizes and adjusted positions of these ROIs were saved as an .xml file for later use. For subsequent montages from the same subject, the ROI-extracting operator was then instructed to align the reference image to each dataset and set the reference point such that it aligns with the mark on the reference image. The .xml file from the first montage was imported using the new reference point, producing ROIs at the previously adjusted locations. The ROI-extracting operator was then instructed to export the images at these ROIs without adjusting their positions. In the event that an ROI could not be exported due to incomplete encapsulation within a single image, the operator was instructed to record this information and omit the ROI. This would produce a maximum of 48 ROIs from human subjects and 48 ROIs from 13-LGS.
Once all ROI locations were finalized, images at these locations were exported and prepared for cone counting. Initial estimates of cone locations were performed on all available ROIs. For images from human subjects at 1°T, the confocal image was selected, and a local-maximum-based cone counting algorithm was used [38]. For all other images, the split-detector image was selected and an automated filtering local detection algorithm was used [39]. The ROIs were compiled, randomized, and masked separately for two cone-counting operators. The cone-counting operators were instructed to correct any mistakes made by the algorithm (see Supplement 1 (1.2MB, pdf) for cone-counting operator instructions [25]). Cone density estimates were compared between manually and automatically processed datasets and between operators for equivalent images.
2.9. Retrospective assessment of Live- and Full-AO-pipe performance
In the final experiment, we compared the performance of Live- and Full-AO-pipe to pre-existing manually processed datasets. Key metrics to be measured were total processing time, montage area, number of videos that failed to process, and the number of montage breaks that would need to be manually repaired. User-interaction time could not be directly measured here, and the methodology used to generate the montages was not controlled, so no strong conclusions should be drawn from time comparisons, but absolute measures of total processing time may be of general value for those who work with these datasets. The pipelines were run separately (not taking advantage of skipping redundant modules), for simplicity in measuring total processing time. The number of breaks in the montage after Live-AO-pipe was compared to Full-AO-pipe to assess the frequency of false positives which may unnecessarily extend an imaging session. Eleven datasets each from human subjects with no known ocular pathologies, subjects with ACHM or albinism, and 13-LGS were included in this assessment (Dataset 1 (149.2KB, xlsx) [25]). For Live-AO-pipe processing, strip-registration of 5 frames was used for human subjects and full-frame registration of 5 frames was used for 13-LGS. For Full-AO-pipe processing, a 10-frame threshold was used for both ARFS (clusters smaller than 10 frames would be rejected) and DeMotion (each pixel must be an average of at least 10 frames) for all subjects.
3. Results
3.1. Prospective assessment of Full-AO-pipe performance
The user-interaction time for manually (TUI;M) and automatically (TUI;A) processed datasets was compared. A reduction of 54.9 ± 28.4% (µ±σ) in user-interaction time was observed for all datasets (Table 1). There was a large species difference; reduction for human and 13-LGS datasets was 34.8 ± 28.1% and 75.0 ± 4.6%, respectively. In only one case, a dataset was processed faster manually than automatically (operator 1, subject JC_0617), but the absolute difference was 2.8 minutes. A small reduction in montage area for automatically (AA) processed datasets was observed relative to manually (AM) processed datasets: 2.8 ± 5.1% overall, 2.7 ± 2.0% and 3.0 ± 7.3% for human and 13-LGS datasets, respectively. The absolute magnitude of this effect was equivalent to a loss of about a single 1 × 1° video in humans and two 1 × 1° videos in 13-LGS. The number of montage breaks that needed to be manually corrected was nearly equivalent, with an overall average of 0.67 ± 0.65 and 0.75 ± 0.75 breaks for manually and automatically processed datasets, respectively. All 96 ROIs were successfully extracted (no montages lacked image content at the desired retinal locations).
Table 1. Operational Metrics of Montage Generation for Automatically and Manually Processed Datasets a .
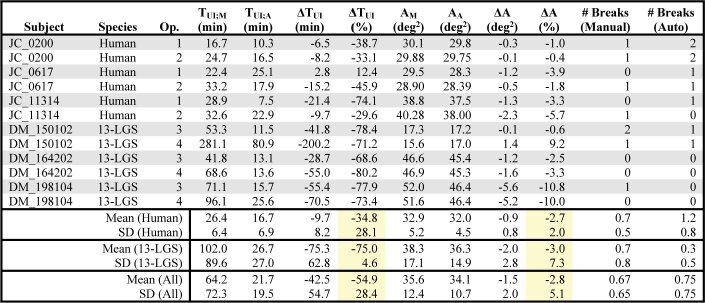
|
Abbreviations – Op.: Montage-generating operator ID; TUI;M and TUI;A: user-interaction time for manually and automatically processed datasets, respectively; ΔTUI: difference in user-interaction time relative to manually processed datasets; AM and AA: montage area for manually and automatically processed datasets, respectively; # Breaks: number of disconnections in the montage that were manually corrected.
Bound cone density was calculated and compared between manually and automatically processed images via Bland-Altman analysis for ROIs from human subjects (Fig. 6(A)). This comparison included cone density estimates from 48 ROI pairs (manual v. automatic for 3 subjects, 4 ROIs, 2 montage-generating operators, 2 cone-counting operators). As this comparison includes repeated measures at the same nominal retinal location from within the same subject (from the 2 montage-generating operators and cone counting operators), these data were not entirely independent. To account for this, density values were averaged between the montage-generating operators and cone-counting operators for equivalent nominal retinal locations, resulting in 12 density comparisons (Fig. 6(B)). This analysis was then repeated for datasets from 13-LGS (Fig. 6(C)-(D)). For all comparisons, we estimate that 95% of cone density estimates would differ by less than approximately ±10% and 5% for human and 13-LGS datasets, respectively.
Fig. 6.

Differences in cone density estimates between manually and automatically generated images. (A) Bland-Altman plot of cone density in human subjects from every pair of ROIs created either automatically or manually (3 subjects’ datasets processed with 2 methods [manually and automatically] by 2 operators, 4 ROIs extracted per subject by another operator, each counted by 2 different operators: 3 × 2 ×2 × 4 ×2 = 96 total ROIs; n = 48 ROI manual v. automatic pairs). Bias: solid line; limits-of-agreement: dashed lines. (B) To improve data independence (measures were repeated on the same retinal location in A), cone density estimates were averaged between montage-generating operators and cone-counting operators so that each density comparison is derived from a unique retinal location (n = 12 manual v. automatic pairs). (C-D) Equivalent analysis as A-B, respectively, for 13-LGS datasets. We expect that 95% of observations would differ by less than ± 10% and 5% for humans and 13-LGS, respectively.
3.2. Retrospective assessment of Full-AO-pipe performance
Absolute processing time was measured for each dataset (Fig. 7(A)). All datasets completed processing within 15 hours, which achieves the benchmark of “overnight” processing. Absolute processing time was then normalized to the number of videos per dataset to provide a more accurate comparison between conditions (Fig. 7(B)). Subjects with ACHM or albinism required significantly more time per video to process (ACHM v. control: p = 1.1E-4; albinism v. control: p = 1.1E-3; ACHM v. 13-LGS: p = 8.2E-8; albinism v. 13-LGS: p = 9.2E-7) but were not significantly different from one another (ACHM v. albinism: p = 0.87; 1-way ANOVA with a Tukey post-hoc multiple comparisons test. To obtain a rough estimate of processing performance with a different number of parallel threads, the processing time/video may be multiplied by the ratio of cores used in this study (4) and that of the other system, assuming a commensurate adjustment in available GPU memory. To identify the rate-limiting step in this workflow, the processing time for each module was calculated and expressed as a percentage of the total time for that video and averaged across all subjects for each condition (Table 2). Generation of secondary modalities, primary sequence reading, and desinusoiding were typically negligible. On average, ARFS required between 1.7-9.0% of the total de-noising time across subjects. The registration and averaging (R&A) subroutine required the most time on average, ranging between 70.7-94.9% of the de-noising time. A full list of cumulative processing time for all videos tested is given in Dataset 1 (149.2KB, xlsx) [25].
Fig. 7.

Retrospective assessment of Full-AO-pipe performance. (A) The distribution of absolute total processing time is shown to give a sense of real-world processing time requirements. Boxes: interquartile range (IQR; 25th-75th percentile); dashed line: median; whiskers: limits of observations excluding outliers (+) defined as an observation 1.5*IQR away from the 25th or 75th percentile. (B) The distribution was then normalized to the number of videos per dataset. Subjects with achromatopsia or albinism required significantly more time to process (ACHM v. control: p = 1.1E-4; Albinism v. control: p = 1.1E-3; ACHM v. 13-LGS: p = 8.3E-8; Albinism v. 13-LGS: p = 9.3E-7) but were not significantly different from one another (ACHM v. albinism: p = 0.87). Speed may be further improved by enabling additional parallel threads; only 4 were used in this study.
Table 2. Proportion of Processing Time for Full-AO-pipe De-Noising Modules a .

|
Each cell represents the µ±σ [min, max] (%) time spent on each de-noising module. The average (µ) was calculated for all videos within each condition, and the SD (σ), minimum, and maximum were computed for the within-subject average across subjects for each condition.
Aspects of the output datasets were then assessed. Representative montages for each condition (with respect to the size of the largest connected montage segment) are shown in Fig. 8. The failure rate, defined as the ratio of videos from which no image passed the success criteria to the total number of videos, was measured (Fig. 9(A)). Videos from control subjects and 13-LGS rarely failed to process, whereas subjects with ACHM and albinism failed more frequently. This increased failure rate translated to montages which were less connected. We defined a metric of montage connectivity as the ratio of connected segments (S) to the total number of images in the montage (N), i.e., 1-((S-1)/N) and evaluated this metric for all subjects (Fig. 9(B)). With this metric, a value of 1 indicates that all images are connected, and 0 indicates than no images are connected. Control subjects and 13-LGS cluster closely to 1, whereas subjects with ACHM and albinism have more disconnected montages. The largest connected segment of a montage was then measured and expressed as a percentage of the largest segment in the manually montaged dataset (Fig. 9(C)). Ideally, these distributions would be at or above 100%, as this would require minimal remaining effort to obtain an analysis-ready montage. The median segment for ACHM and albinism was ∼50% and 75% as large as the manually processed dataset, respectively, although the variability was much higher for these subjects. Occasionally, Full-AO-pipe produced a montage with greater area than the manually processed dataset.
Fig. 8.

Representative montages output by Full-AO-pipe. For human subjects, a 0.5 × 0.5° ROI at ∼0.25°T and 0.75 × 0.75° ROIs at ∼3°T, 9°T, and 4.5°S are shown. For the 13-LGS, 1 × 1° ROIs at 3, 5, 7, and 9°I are shown. For control subjects and 13-LGS, image quality is comparable; for subjects with nystagmus, image quality is more variable, occasionally outputting visibly distorted images, but also occasionally outperforming the manually generated images. White stars: eccentricity reference point; Red asterisk: 0.7 × 0.7° ROI.
Fig. 9.

Metrics of Full-AO-pipe montaging performance. (A) Videos from control subjects rarely failed to process with the parameters used here (13-LGS never failed), whereas the failure rate was much higher for subjects with ACHM or albinism. Boxes: interquartile range (IQR; 25th-75th percentile); dashed line: median; whiskers: limits of observations excluding outliers (+) defined as an observation 1.5*IQR away from the 25th or 75th percentile. (B) Montage connectivity (1 = all images connected; 0 = no images connected), was decreased in subjects with ACHM or albinism relative to controls and 13-LGS. (C) When comparing the largest connected montage segment to manually montaged datasets, performance was generally good for control subjects and 13-LGS. The median segment for ACHM and albinism was ∼50% and 75% as large as the manually processed dataset, respectively, although the variability was much higher for these subjects.
3.3. Retrospective assessment of Live-AO-pipe performance
Processing time for this module was analyzed to assess its utility as a real-time feedback module. Total processing time for each dataset was typically under 1 hour for all conditions (Fig. 10(A)), which is approximately the duration of an imaging session for a single eye. In one extreme case, total processing time was nearly 2 hours. All datasets from 13-LGS were completed in less than 3 minutes (recall that only full-frame registration was performed in this group). The total processing time was then normalized to the number of videos per dataset (Fig. 10(B)). Differences in processing time per video between subject conditions was assessed by 1-way ANOVA with a Tukey post-hoc multiple comparisons test. Datasets from 13-LGS processed significantly faster than human subjects (p = 0.04, 4.1E-5, 3.6E-5 for 13-LGS v. control, ACHM, and albinism, respectively), but there was not a significant difference found between conditions within human subjects (p > 0.05 for all comparisons). The processing time per video was then multiplied by the number of parallel threads used (4) to estimate the distribution of lag between initiation and montage placement (Fig. 10(C)). Across all subjects, the median delay between subsequent video acquisitions was ∼19s. Control subjects and subjects with nystagmus had median montaging lags of ∼1min and ∼2min, respectively, meaning that Live-AO-pipe would typically trail behind acquisition by approximately 3 and 6 videos. The average serial montaging lag for 13-LGS was 19.4 ± 0.8s, which would result in timely feedback and the ability to steer the animal to the location of a break in the montage without excessive backtracking. The lag across all subjects was 54.6 ± 32.7s (µ±σ). A representative subject (based on processing time/video) was selected for each subject group and the distribution of cumulative processing time for each module was calculated (Fig. 10(D)). As with Full-AO-pipe, the rate-limiting step was the registration and averaging module despite the more liberal success criteria. The distribution of delays between video acquisitions are also shown for reference. The numerous outliers for acquisition delays result from imaging breaks to mitigate subject fatigue for humans and factors such as tear film maintenance for 13-LGS.
Fig. 10.

Retrospective assessment of Live-AO-pipe performance. (A) The distribution of absolute total processing time for all datasets. Boxes: interquartile range (IQR; 25th-75th percentile); dashed line: median; whiskers: limits of observations excluding outliers (+) defined as an observation 1.5*IQR away from the 25th or 75th percentile. (B) The distribution was then normalized to the number of videos per dataset. Datasets from 13-LGS processed significantly faster than humans (p = 0.04, 4.1E-5, 3.6E-5 for 13-LGS v. control, ACHM, and albinism, respectively), but there was not a significant difference between conditions within human subjects (p > 0.05). (C) Serial processing time/video for comparison against the median delay between subsequent video acquisitions was measured to be ∼19s across all subjects, which is 3x and 6x faster than the median montaging lag for control subjects and subjects with nystagmus, respectively. The average serial montaging lag for 13-LGS was measured to be 19.4 ± 0.8s. (D) A representative subject (based on time/video) for each condition was selected to demonstrate the distribution of cumulative processing time/video for each module in the de-noising and montaging services. The distribution of delays between subsequent video acquisitions are also plotted, as this serves as a useful benchmark for feedback utility. Nearly all of the images from this 13-LGS dataset were added to the montage before a subsequent video acquisition would have taken place, whereas the lag for images from human subjects was typically on the order of ∼30s-2min. A substantial number of outliers exist for acquisition delays, as regular imaging breaks are often required to mitigate subject fatigue. As with Full-AO-pipe, the rate-limiting step appears to be the registration and averaging (R&A) module, despite the more liberal success criteria. Definitions for box-and-whisker plots are equivalent to A-C, with the median indicated by “bulls-eyes” and outliers by open circles.
Factors related to de-noising and montaging performance were then assessed for Live-AO-pipe. Representative montages for each condition (with respect to the size of the largest connected montage segment) are shown in Fig. 11. The distribution of failure rate for each subject was calculated (Fig. 12(A)) and exhibited trends similar to that of Full-AO-pipe. Importantly, the failure rate here includes images that were determined to be redundant with a successfully montaged image from a different video (same expected retinal location and FOV), which explains the slightly higher failure rates compared to Full-AO-pipe (Fig. 9(A)). Montage connectivity was generally worse for Live-AO-pipe than for Full-AO-pipe (Fig. 12(B), 9(B)), which results in an overestimation of the actual number of breaks; however, the relatively fast visual feedback in the Live-AO-pipe GUI allows operators to judge overlap between the output images (Fig. 11, Visualization 1 (28.8MB, avi) ). The largest connected montage segment relative to the largest segment of the manually montaged dataset was then assessed for all subjects (Fig. 12(C)). As expected from the decreased montage connectivity, the largest segment was typically smaller than generated from Full-AO-pipe (Fig. 9(C)).
Fig. 11.

Montages output by Live-AO-pipe in representative subjects for each condition. Manually processed and montaged datasets are given for reference. While there are a greater number of unconnected images in the montages output by Live-AO-pipe than Full, the operators now have the ability to assess the acquired retinal locations and make a more informed decision about the completeness of the acquisition.
Fig. 12.

Metrics of Live-AO-pipe montaging performance. (A) The distribution of failure rates for all subjects is shown. Importantly, this includes images from videos that were deteremined to be redundant with another video that was successfully montaged. Boxes: interquartile range (IQR; 25th-75th percentile); dashed line: median; whiskers: limits of observations excluding outliers (+) defined as an observation 1.5*IQR away from the 25th or 75th percentile. (B) Montage connectivity (1 = all images connected, 0 = no images connected) was fair for all datasets, with a median connectivity of 0.90 or above. (C) The largest montage segment for all subjects constructed by Live-AO-pipe were typically smaller than the completely intact manually montaged dataset for human subjects. Datasets from 13-LGS had better performance with a median largest segment size of 87%.
The number of connected segments between Live- and Full-AO-pipe was then compared (Fig. 13). The less connected montage output by Live-AO-pipe may encourage operators to acquire somewhat redundant videos with greater overlap between neighboring retinal locations, but this would likely reduce the risk of collecting an incomplete dataset without necessarily increasing post-processing time.
Fig. 13.

Relationship between montages generated by Full- and Live-AO-pipe. The number of segments successfully connected by Full- and Live-AO-pipe are compared for each subject. Ideally, the number of segments between pipeline types would be equivalent (and equal to 1), as this would offer an accurate prediction of Full-AO-pipe performance after acquisition. Due to the trade-off between montaging robustness and speed in Live-AO-pipe, the number of breaks is higher for Live-AO-pipe. While this may result in unnecessary redundant acquisitions in an attempt to obtain a fully connected montage, this is preferred over the situation where the number of breaks are underestimated by Live-AO-pipe and the retina is undersampled during acquisition and an incomplete dataset is collected.
4. Discussion
4.1. Architecture
Previously, AOSLO hardware and software systems have been demonstrated with highly efficient image acquisition and processing schemes [40–43]. These systems typically employed widefield (∼20-30°) eye tracking subsystems and additional scanning mirrors for real-time optical and digital image stabilization. Rather than direct the subject’s fixation to each retinal location, fixation was held constant, and the imaging field was steered. Using pre-defined protocols, montages could be rapidly obtained which were as large as 11mm2 in as little as 30min [40]. While these studies represent major strides into improving the accessibility and efficiency of AO retinal imaging, the optical and electronic designs are somewhat costly and complex. We aimed to develop our image processing pipeline architecture such that no additional hardware beyond that found in conventional AOSLO subsystems was required [5].
We converged on two distinct architectures optimized for real-time and offline image processing. Ideally, one pipeline would be developed which produces analysis-ready montages in nearly real-time, rather than two pipelines with different parameter sets. The output of Live-AO-pipe may be sufficient for obtaining an initial map of retinal locations, but the images are often too noisy to provide confident measurements, and Full-AO-pipe is often too slow to provide feedback within a useful timeframe. The rate-limiting step in the current implementation of AO-pipe is the strip-registration subroutine in the de-noising service. Possible speed improvements to the current implementation of this algorithm include a method of determining which modality to use for motion estimation and a more intelligent method of identifying the initial strip size. Typical intensity-based measurements of SNR, contrast, or entropy tend to poorly predict which modality exhibits more structure, but feature-based methods may prove useful. Nonlinear optimization, feature analysis, or machine learning (or some combination of these) may be promising approaches for determining a strip size which yields a large output image while minimizing motion artefacts. Alternative registration algorithms have been demonstrated for AOSLO videos which have been used for real-time AO-corrected stimulus delivery [26,44]. Further, single-frame, model-based de-noising algorithms derived from compressed sensing [45] may be a viable alternative to a multi-frame approach, as has been shown for other modalities [46]. Ultimately, an SNR which yields acceptable levels of repeatability in measurements of photoreceptor geometry should be pursued, but this may be difficult to automatically assess without some form of human input.
In the future, automated analysis modules may also be incorporated to provide useful metrics of photoreceptor health. An initial challenge would be identifying a reference point from which the eccentricity of subsequent ROIs would be defined. The definition of this reference point may be based on the location of peak foveal cone density or the locus of fixation [47], as well as the center of the foveal depression measured by optical coherence tomography (OCT). Each method exhibits disadvantages and associated error, so determination of the best approach will likely not be trivial. Once a reference point is selected, the next challenge may be to automate ROI extraction. As indicated in Supplement 1 (1.2MB, pdf) [25], this task also represents a complex optimization problem that is currently best performed by a human operator. Upon extraction of ROIs, automated photoreceptor segmentation algorithms may be used which exhibit excellent performance [38,39,48,49]. A method which may circumvent estimation of the foveal center, ROI extraction, and photoreceptor segmentation has also recently been presented [50]. This method may not be applicable in subjects with significant disruption to the regularity of the photoreceptor mosaic, although a confidence map is also produced which could offer timely feedback of image quality and possible regions of degeneration.
4.2. Generalizability
Currently, this software is relatively constrained to a fairly specific application using a set of specific AOSLO systems. For example, the video inputs must be uncompressed 8-bit grayscale .avi files with a standardized naming scheme organized into a standardized folder structure. Efforts are currently underway to increase the amount of metadata output by the acquisition software, which reduces the strain on the user to comply with naming standards. AO-pipe was also primarily validated on images of the photoreceptor mosaic; most of the algorithms used are now fairly generalizable to all feature types (ARFS, DeMotion, de-warping). In addition, the automontagers both use feature-matching approaches which were only tested on photoreceptor images. While 13-LGS datasets included the ONH and ACHM datasets included non-waveguiding cones in the fovea, future studies assessing its utility on more diverse features such as the vasculature and nerve fiber layer are warranted. Finally, we plan to increase modularity to facilitate use with other AOSLO designs, incorporate new algorithms, and provide support for AO-flood and AO-OCT systems.
4.3. Implications of the prospective assessment of Full-AO-pipe
We found that Full-AO-pipe saved operators, on average, ∼55% on time spent interacting with the software and data. This effect was more dramatic for 13-LGS datasets (∼75%) than human datasets (∼35%), and in the worst case, cost one operator 2 minutes longer than manually processing the dataset. User-interaction time is almost certainly proportional to dataset size when manually processing datasets, but this is not necessarily the case for Full-AO-pipe. User-interaction time is more likely proportional to image quality and the extent of image overlap from acquisition. Previously, imaging protocols may have been more prone to sparsity (e.g., collecting neighboring images with less overlap) to increase coverage while requiring less acquisition and post-processing time. With automated processing, an investment of collecting larger datasets with more overlap between images may slightly increase acquisition time but result in negligible added post-processing time.
The primary goal of Full-AO-pipe was to produce analysis-ready montages with minimal user-input. The instructions for the montage generating operators stated that “The end-result should be a fully-connected montage of high-quality images from which cone-counts could be performed” and this process included manual correction of any low quality or distorted images. By returning the montages, these operators certified that they were of sufficient quality for measurement. To provide further evidence of sufficient image quality and montage construction, the montages were passed to another operator (masked to the origins of the montage) for ROI extraction. All ROIs were able to be extracted, indicating sufficient retinal coverage for automatically processed datasets. Cone counts were then performed in the ROIs (masked and randomized once more) by two more operators. We found that, for datasets from human subjects, 95% of cone density estimates would differ by less than ∼10% in either direction, which is even less than previously estimated repeatability values for imperfectly aligned ROIs within a montage [51]. This range was even smaller in 13-LGS datasets (± ∼5%), in part due to the lower average density, but also likely due to the lower eye-motion and higher initial image quality. Taken together, these data suggest that Full-AO-pipe substantially reduces the post-processing burden while producing montages of similar quality to manually processed datasets.
4.4. Implications of the retrospective assessment of Full-AO-pipe
Here, we assessed the performance of Full-AO-pipe in a larger cohort of subjects in health and disease. Datasets from subjects with ACHM and albinism were selected as they exhibit varying degrees of nystagmus and fixational instability, which tests the capabilities of the current software. ACHM also features aberrant cone waveguiding, which results in a region of nearly absent confocal signal at the fovea. Total processing time required was increased for subjects with ACHM and albinism. Typically, this is because ARFS identifies a greater number of spatially distinct clusters of frames, then each of those are input to the registration and averaging module. Rapid eye movements also impede the ability to obtain a good AO correction, leading to worsened image quality, which increases the time required to find a strip size that results in a good correlation. Currently, a “good correlation” is defined as one standard deviation above the mean for all source-frame strips registered to the reference frame. Further effort is warranted in determining a more robust mechanism of setting this relatively arbitrary threshold. Additionally, a 10-frame minimum threshold was used for all subjects in this experiment, whereas manually processed datasets often included raw frames for the sole purpose of obtaining an intact montage. A potentially useful hybrid approach would be to determine the minimum number of frames to average in order to obtain a montage, then improve the SNR in targeted areas. Regardless, all datasets completed processing within 15 hours; if initiated at 5pm, an initial montage would be ready by 8am the next day, which satisfies a major goal of this version of the pipeline.
The failure rate for videos from subjects with ACHM and albinism were unfortunately rather high. This was predominantly caused by the inability of ARFS to register 10 or more frames together, especially for small FOVs; in this case, only the single best frame was output to the registration and averaging module, which may have failed due to the relatively high correlation threshold that was previously mentioned. Further effort is required to determine how a lower minimum frame threshold, a lower correlation threshold, and the resultant image quality might be balanced. Unsurprisingly, this resulted in lessened montage connectivity, which would then require substantial manual correction. While the automatically generated montages were generally smaller than the manually generated montages, relatively large segments were typically connected. Further effort is warranted in an automontager feedback algorithm which identifies disconnections and modifies the registration and averaging parameters to increase image size and the subsequent likelihood of connecting breaks. The automontager used here already features an “append” mode, so no time would be wasted re-computing the initial montage. While certainly not perfect, the majority of cases represent a vastly improved starting point compared to an entirely manual alternative.
4.5. Implications of the retrospective assessment of Live-AO-pipe
While Live-AO-pipe is intended for use as a feedback tool during acquisition, we used pre-existing datasets to benchmark processing speed without the confound of operator intervention. By comparing the delay between processing initiation and addition to the displayed montage to acquisition timestamps, we can determine whether Live-AO-pipe typically accomplishes the task of providing feedback before the acquisition of a new image sequence. This benchmark was achieved only for 13-LGS as substantially less time was required for registration and averaging. Timely feedback is especially critical for 13-LGS imaging, as it can be difficult to return to a previously imaged location to correct disconnections in the montage. Lags were higher for human subjects, as computationally expensive strip-registration and quality assessment is required. While these lags were several factors higher than the typical acquisition delay, the overall lag was still within a reasonable timeframe and would likely catch up during a ∼5-minute imaging break. Importantly, data transfer time was not included in this analysis, and depending on the type of connection between the acquisition and processing PC, variable delays may be introduced. In our experience with a LAN connection between PC’s (Cat6 ethernet cables), the transfer lag was typically ∼0.1 ± 0.3s (µ±σ).
By comparing montage connectivity between Live- and Full-AO-pipe outputs, we can assess how well Live-AO-pipe predicts the output quality of Full-AO-pipe. In general, montage connectivity was lower for Live- compared to Full-AO-pipe, which may result in unnecessary additional acquisitions; however, as mentioned previously, the post-processing burden would not necessarily be proportional to the dataset size, so the primary concern here is increasing light exposure, subject fatigue, and data storage requirements. As our AOSLO devices typically operate at several orders of magnitude below the maximum permissible exposure, each acquisition typically requires only an additional 10s, and data storage prices continually decrease over time, we believe these consequences are outweighed by the benefit of collecting more complete datasets.
5. Conclusions
With the combined utility of Live- and Full-AO-pipe, we have demonstrated a much-needed feedback tool for AOSLO dataset acquisition as well as a substantial reduction in the post-processing burden. We have shown that the output image quality is sufficient for estimating cone density with minimal differences to manually processed datasets. While new strategies are warranted for increasing fidelity in subjects with high nystagmus, the results represent a substantially improved starting point compared to the current standard workflow. We have made the source code available in an effort to promote feedback and advancement towards the ideal of minimizing operator burden and maximizing output dataset robustness and quality [23].
Acknowledgments
The authors would like to acknowledge Benjamin Davidson and Christos Bergeles for assistance with the fast automontager, Alfredo Dubra for developing and sharing the desinusoiding software and DeMotion, Erin Curran for assistance with the AOIP databank, Katie Litts and Maureen Tuffnell for their assistance with subject selection, Erica Woertz, Ben Sajdak, and Emily Patterson for useful discussion and feedback on the software, Jessica Morgan and David Brainard for useful discussion regarding the pipeline architecture, Ethan Duwell and the MCW-RCC for their assistance with remote computing during the COVID-19 pandemic.
Funding
National Eye Institute10.13039/100000053 (P30EY001931, R01EY017607, R01EY024969, T32EY014537, U01EY025477, U24EY029891); National Center for Advancing Translational Sciences10.13039/100006108 (UL1TR001436); National Center for Research Resources10.13039/100000097 (C06RR016511); Vision for Tomorrow Foundation; Alcon Research Institute10.13039/100007817; Foundation Fighting Blindness10.13039/100001116 (PPA-0641-0718-UCSF).
Disclosures
AES: Translational Imaging Innovations (E). JC: OptoVue (F), AGTC (F), MeiraGTx (C, F), Translational Imaging Innovations (I). RFC: Translational Imaging Innovations (C).
Supplemental document
See Supplement 1 (1.2MB, pdf) for supporting content.
References
- 1.Wynne N., Carroll J., Duncan J. L., “Promises and pitfalls of evaluating retinal diseases with adaptive optics scanning light ophthalmoscopy (AOSLO),” Prog. Retin. Eye Res. 2020, 100920 (2020). 10.1016/j.preteyeres.2020.100920 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Liang J., Williams D. R., Miller D. T., “Supernormal vision and high-resolution retinal imaging through adaptive optics,” J. Opt. Soc. Am. A. 14(11), 2884–2892 (1997). 10.1364/JOSAA.14.002884 [DOI] [PubMed] [Google Scholar]
- 3.Roorda A., Romero-Borja F., Donnelly W. J., III, Queener H., Hebert T., Campbell M., “Adaptive optics scanning laser ophthalmoscopy,” Opt. Express 10(9), 405–412 (2002). 10.1364/OE.10.000405 [DOI] [PubMed] [Google Scholar]
- 4.Roorda A., Duncan J. L., “Adaptive optics ophthalmoscopy,” Annu. Rev. Vis. Sci. 1(1), 19–50 (2015). 10.1146/annurev-vision-082114-035357 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Dubra A., Sulai Y., “Reflective afocal broadband adaptive optics scanning ophthalmoscope,” Biomed. Opt. Express 2(6), 1757–1768 (2011). 10.1364/BOE.2.001757 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Cooper R. F., Sulai Y. N., Dubis A. M., Chui T. Y., Rosen R. B., Michaelides M., Dubra A., Carroll J., “Effects of intraframe distortion on measures of cone mosaic geometry from adaptive optics scanning light ophthalmoscopy,” Transl. Vis. Sci. Technol. 5(1), 10 (2016). 10.1167/tvst.5.1.10 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Chen M., Cooper R. F., Han G. K., Gee J., Brainard D. H., Morgan J. I., “Multi-modal automatic montaging of adaptive optics retinal images,” Biomed. Opt. Express 7(12), 4899–4918 (2016). 10.1364/BOE.7.004899 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Davidson B., Kalitzeos A., Carroll J., Dubra A., Ourselin S., Michaelides M., Bergeles C., “Fast adaptive optics scanning light ophthalmoscope retinal montaging,” Biomed. Opt. Express 9(9), 4317–4328 (2018). 10.1364/BOE.9.004317 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Yang Q., Yin L., Nozato K., Zhang J., Saito K., Merigan W. H., Williams D. R., Rossi E. A., “Calibration-free sinusoidal rectification and uniform retinal irradiance in scanning light ophthalmoscopy,” Opt. Lett. 40(1), 85–88 (2015). 10.1364/OL.40.000085 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Scoles D., Sulai Y. N., Dubra A., “In vivo dark-field imaging of the retinal pigment epithelium cell mosaic,” Biomed. Opt. Express 4(9), 1710–1723 (2013). 10.1364/BOE.4.001710 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Scoles D., Sulai Y. N., Langlo C. S., Fishman G. A., Curcio C. A., Carroll J., Dubra A., “In vivo imaging of human cone photoreceptor inner segments,” Invest. Ophthalmol. Vis. Sci. 55(7), 4244–4251 (2014). 10.1167/iovs.14-14542 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Ramaswamy G., Devaney N., “Pre-processing, registration and selection of adaptive optics corrected retinal images,” Ophthalmic Physiol. Opt. 33(4), 527–539 (2013). 10.1111/opo.12068 [DOI] [PubMed] [Google Scholar]
- 13.Salmon A. E., Cooper R. F., Langlo C. S., Baghaie A., Dubra A., Carroll J., “An automated reference frame selection (ARFS) algorithm for cone imaging with adaptive optics scanning light ophthalmoscopy,” Transl. Vis. Sci. Technol. 6(2), 9 (2017). 10.1167/tvst.6.2.9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Stevenson S. B., Roorda A., “Correcting for miniature eye movements in high resolution scanning laser ophthalmoscopy,” in Proc SPIE 5688, Ophthalmic Technologies XV, Manns F., Soederberg P. G., Ho A., Stuck B. E., Belkin M., eds. (SPIE, 2005), pp. 145–151. [Google Scholar]
- 15.Yang Q., Zhang J., Nozato K., Saito K., Williams D. R., Roorda A., Rossi E. A., “Closed-loop optical stabilization and digital image registration in adaptive optics scanning light ophthalmoscopy,” Biomed. Opt. Express 5(9), 3174–3191 (2014). 10.1364/BOE.5.003174 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Dubra A., Harvey Z., “Registration of 2D images from fast scanning ophthalmic instruments,” in Biomedical Image Registration, 6204Fischer B., Dawant B., Lorenz C., eds. (Springer-Verlag, 2010), pp. 60–71. 10.1007/978-3-642-14366-3_6 [DOI] [Google Scholar]
- 17.Bedggood P., Metha A., “De-warping of images and improved eye tracking for the scanning laser ophthalmoscope,” PLoS One 12(4), e0174617 (2017). 10.1371/journal.pone.0174617 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Azimipour M., Zawadzki R. J., Gorczynska I., Migacz J., Werner J. S., Jonnal R. S., “Intraframe motion correction for raster-scanned adaptive optics images using strip-based cross-correlation lag biases,” PLoS One 13(10), e0206052 (2018). 10.1371/journal.pone.0206052 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Sajdak B., Sulai Y. N., Langlo C. S., Luna G., Fisher S. K., Merriman D. K., Dubra A., “Noninvasive imaging of the thirteen-lined ground squirrel photoreceptor mosaic,” Vis. Neurosci. 33, E003 (2016). 10.1017/S0952523815000346 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Sajdak B. S., Salmon A. E., Cava J. A., Allen K. P., Freling S., Ramamirtham R., Norton T. T., Roorda A., Carroll J., “Noninvasive imaging of the tree shrew eye: Wavefront analysis and retinal imaging with correlative histology,” Exp. Eye Res. 185, 107683 (2019). 10.1016/j.exer.2019.05.023 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Joseph A., Guevara-Torres A., Schallek J., “Imaging single-cell blood flow in the smallest to largest vessels in the living retina,” eLife 8, e45077 (2019). 10.7554/eLife.45077 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Huckenpahler A. L., Carroll J., Salmon A. E., Sajdak B. S., Mastey R. R., Allen K. P., Kaplan H. J., McCall M. A., “Noninvasive imaging and correlative histology of cone photoreceptor structure in the pig retina,” Transl. Vis. Sci. Technol. 8(6), 38 (2019). 10.1167/tvst.8.6.38 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Salmon A. E., “AO-PIPELINE,” https://github.com/asalmon91/AO-PIPELINE.
- 24.Roorda A., Williams D. R., “Optical fiber properties of individual human cones,” J. Vis. 2(5), 4–412 (2002). 10.1167/2.5.4 [DOI] [PubMed] [Google Scholar]
- 25.Salmon A.E., “Subject Table and Statistics from the Retrospective Assessment of Full-AO-pipe,” figshare (2021) boe-12-6-3142-d001.xlsx.
- 26.Vogel C. R., Arathorn D. W., Roorda A., Parker A., “Retinal motion estimation in adaptive optics scanning laser ophthalmoscopy,” Opt. Express 14(2), 487–497 (2006). 10.1364/OPEX.14.000487 [DOI] [PubMed] [Google Scholar]
- 27.Rublee E., Rabaud V., Konolige K., Bradski G., “ORB: An efficient alternative to SIFT or SURF,” in 2011 International Conference on Computer Vision, (IEEE, 2011), pp. 2564–2571. 10.1109/ICCV.2011.6126544 [DOI] [Google Scholar]
- 28.Langlo C. S., Patterson E. J., Higgins B. P., Summerfelt P., Razeen M. M., Erker L. R., Parker M., Collison F. T., Fishman G. A., Kay C. N., Zhang J., Weleber R. G., Yang P., Wilson D. J., Pennesi M. E., Lam B. L., Chiang J., Chulay J. D., Dubra A., Hauswirth W. W., Carroll J., ACHM-001 Study Group , “Residual foveal cone structure in CNGB3-associated achromatopsia,” Invest. Ophthalmol. Vis. Sci. 57(10), 3984–3995 (2016). 10.1167/iovs.16-19313 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Wang Q., Tuten W. S., Lujan B. J., Holland J., Bernstein P. S., Schwartz S. D., Duncan J. L., Roorda A., “Adaptive optics microperimetry and OCT images show preserved function and recovery of cone visibility in macular telangiectasia type 2 retinal lesions,” Invest. Ophthalmol. Vis. Sci. 56(2), 778–786 (2015). 10.1167/iovs.14-15576 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Yokota S., Ooto S., Hangai M., Takayama K., Ueda-Arakawa N., Yoshihara Y., Hanebuchi M., Yoshimura N., “Objective assessment of foveal cone loss ratio in surgically closed macular holes using adaptive optics scanning laser ophthalmoscopy,” PLoS One 8(5), e63786 (2013). 10.1371/journal.pone.0063786 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Cornsweet T. N., Crane H. D., “Accurate two-dimensional eye tracker using first and fourth Purkinje images,” J. Opt. Soc. Am. 63(8), 921–928 (1973). 10.1364/JOSA.63.000921 [DOI] [PubMed] [Google Scholar]
- 32.Engbert R., Mergenthaler K., Sinn P., Pikovsky A., “An integrated model of fixational eye movements and microsaccades,” Proc. Natl. Acad. Sci. U. S. A. 108(39), E765–E770 (2011). 10.1073/pnas.1102730108 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Sobel I., Feldman G., “A 3 × 3 Isotropic Gradient Operator for Image Processing,” (Stanford Artificial Intelligence Project (SAIL), 1968), pp. 271–272. [Google Scholar]
- 34.Arthur D., Vassilvitskii S., “k-means++: The advantages of careful seeding,” in Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, (Society for Industrial and Applied Mathematics, 2007), pp. 1027–1035. [Google Scholar]
- 35.Chen M., Cooper R. F., Gee J. C., Brainard D. H., Morgan J. I. W., “Automatic longitudinal montaging of adaptive optics retinal images using constellation matching,” Biomed. Opt. Express 10(12), 6476–6496 (2019). 10.1364/BOE.10.006476 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Merriman D. K., Sajdak B. S., Li W., Jones B. W., “Seasonal and post-trauma remodeling in cone-dominant ground squirrel retina,” Exp. Eye Res. 150, 90–105 (2016). 10.1016/j.exer.2016.01.011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Sajdak B. S., Salmon A. E., Litts K. M., Wells C., Allen K. P., Dubra A., Merriman D. K., Carroll J., “Evaluating seasonal changes of cone photoreceptor structure in the 13-lined ground squirrel,” Vision Res. 158, 90–99 (2019). 10.1016/j.visres.2019.02.009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Li K. Y., Roorda A., “Automated identification of cone photoreceptors in adaptive optics retinal images,” J. Opt. Soc. Am. A 24(5), 1358–1363 (2007). 10.1364/JOSAA.24.001358 [DOI] [PubMed] [Google Scholar]
- 39.Cunefare D., Cooper R. F., Higgins B., Katz D. F., Dubra A., Carroll J., Farsiu S., “Automatic detection of cone photoreceptors in split detector adaptive optics scanning light ophthalmoscope images,” Biomed. Opt. Express 7(5), 2036–2050 (2016). 10.1364/BOE.7.002036 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Huang G., Qi X., Chui T. Y., Zhong Z., Burns S. A., “A clinical planning module for adaptive optics SLO imaging,” Optom. Vis. Sci. 89(5), 593–601 (2012). 10.1097/OPX.0b013e318253e081 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Zhang J., Yang Q., Saito K., Nozato K., Williams D. R., Rossi E. A., “An adaptive optics imaging system designed for clinical use,” Biomed. Opt. Express 6(6), 2120–2137 (2015). 10.1364/BOE.6.002120 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Hammer D. X., Ferguson R. D., Bigelow C. E., Iftimia N. V., Ustun T. E., Burns S. A., “Adaptive optics scanning laser ophthalmoscope for stabilized retinal imaging,” Opt. Express 14(8), 3354–3367 (2006). 10.1364/OE.14.003354 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Ferguson R. D., Zhong Z., Hammer D. X., Mujat M., Patel A. H., Deng C., Zou W., Burns S. A., “Adaptive optics scanning laser ophthalmoscope with integrated wide-field retinal imaging and tracking,” J. Opt. Soc. Am. A 27(11), A265–A277 (2010). 10.1364/JOSAA.27.00A265 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Arathorn D. W., Yang Q., Vogel C. R., Zhang Y., Tiruveedhula P., Roorda A., “Retinally stabilized cone-targeted stimulus delivery,” Opt. Express 15(21), 13731–13744 (2007). 10.1364/OE.15.013731 [DOI] [PubMed] [Google Scholar]
- 45.Donoho D. L., “Compressed sensing,” IEEE Trans. Inf. Theory 52(4), 1289–1306 (2006). 10.1109/TIT.2006.871582 [DOI] [Google Scholar]
- 46.Fang L., Li S., Nie Q., Izatt J. A., Toth C. A., Farsiu S., “Sparsity based denoising of spectral domain optical coherence tomography images,” Biomed. Opt. Express 3(5), 927–942 (2012). 10.1364/BOE.3.000927 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Putnam N. M., Hofer H. J., Doble N., Chen L., Carroll J., Williams D. R., “The locus of fixation and the foveal cone mosaic,” J. Vis. 5(7), 3 (2005). 10.1167/5.7.3 [DOI] [PubMed] [Google Scholar]
- 48.Cunefare D., Fang L., Cooper R. F., Dubra A., Carroll J., Farsiu S., “Open source software for automatic detection of cone photoreceptors in adaptive optics ophthalmoscopy using convolutional neural networks,” Sci. Rep. 7(1), 6620 (2017). 10.1038/s41598-017-07103-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Cunefare D., Huckenpahler A. L., Patterson E. J., Dubra A., Carroll J., Farsiu S., “RAC-CNN: Multimodal deep learning based automatic detection and classification of rod and cone photoreceptors in adaptive optics scanning light ophthalmoscope images,” Biomed. Opt. Express 10(8), 3815–3832 (2019). 10.1364/BOE.10.003815 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Cooper R. F., Aguirre G. K., Morgan J. I. W., “Fully automated estimation of spacing and density for retinal mosaics,” Transl. Vis. Sci. Technol. 8(5), 26 (2019). 10.1167/tvst.8.5.26 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Garrioch R., Langlo C., Dubis A. M., Cooper R. F., Dubra A., Carroll J., “Repeatability of in vivo parafoveal cone density and spacing measurements,” Optom. Vis. Sci. 89(5), 632–643 (2012). 10.1097/OPX.0b013e3182540562 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Citations
- Salmon A.E., “Subject Table and Statistics from the Retrospective Assessment of Full-AO-pipe,” figshare (2021) boe-12-6-3142-d001.xlsx.