
Fig. 6.
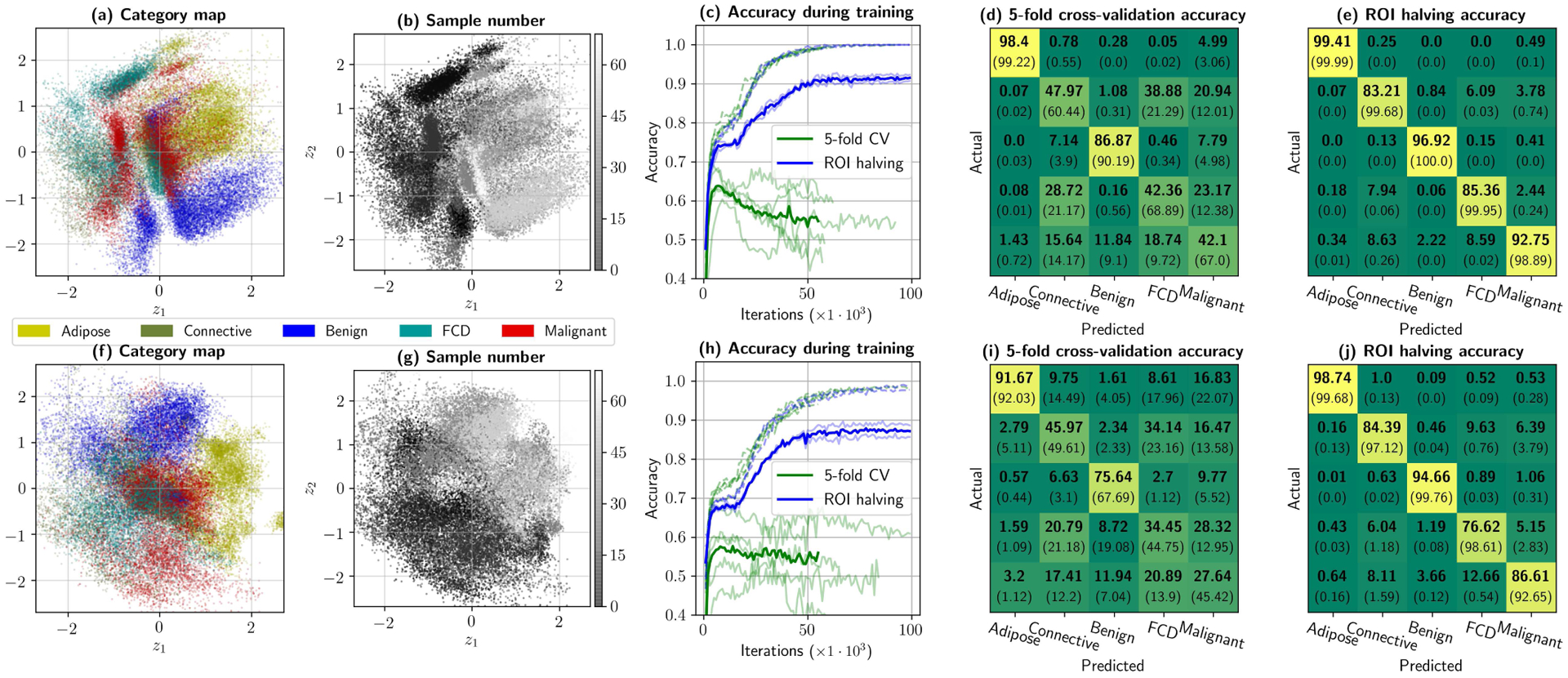
Initial dataset considerations provided by the neural framework. Top row shows (a) the 31 × 31-pixel patch dataset projected into 2D, color-coded by tissue supercategory, (b) the same plot but color-coded by sample number of origin, (c) classifier accuracies observed during training for 1000 random samples of the training and test sets in 5-fold cross-validation and ROI halving experiments. Finally, the confusion matrices in (d) and (e) provide the best test (in bold) and training (between parentheses) accuracies per category, for 5-fold cross-validation and ROI halving, respectively. Bottom row –plots (f) through (j)– provides analogous results for pixel-wise analysis. In this dataset, inter-sample variability dominates intra-sample variability by a significant margin, to the point that spectra can be nearly perfectly identified if the training set includes information from its specimen of origin.