
Fig. 3.
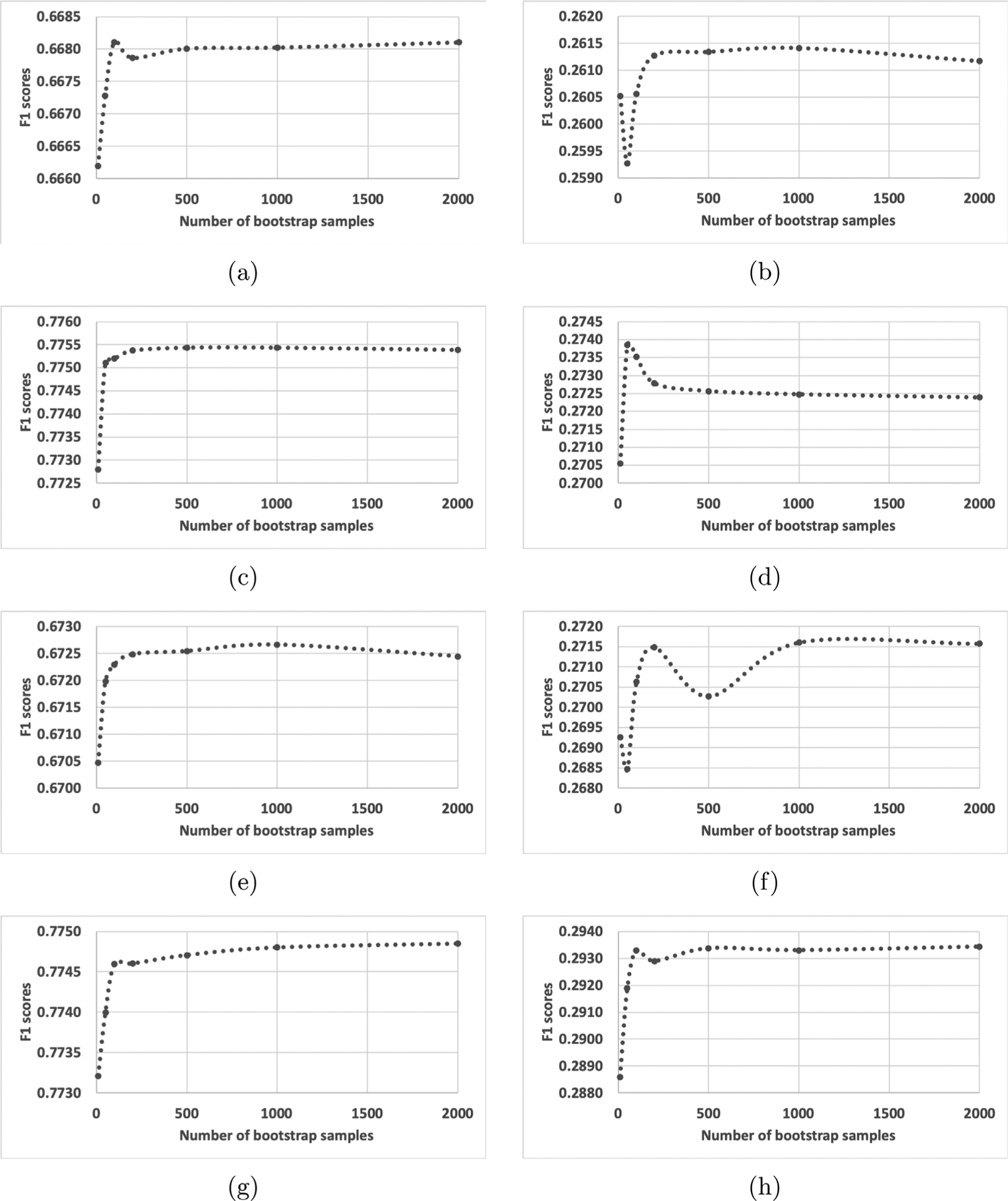
Micro and macro-averaged F1 scores per number of bootstrap samples being aggregated. (a) MT-CNN subsite micro-F1, (b) MT-CNN subsite macro-F1, (c) MT-CNN histology micro-F1, (d) MT-CNN histology macro-F1, (e) MT-HCAN subsite micro-F1, (f) MT-HCAN subsite macro-F1, (g) MT-HCAN histology micro-F1, and (h) MT-HCAN histology macro F1. Except in (d), we observed that the F1-scores were stable if more than 1000 bootstrap samples were applied.