
Figure 10.
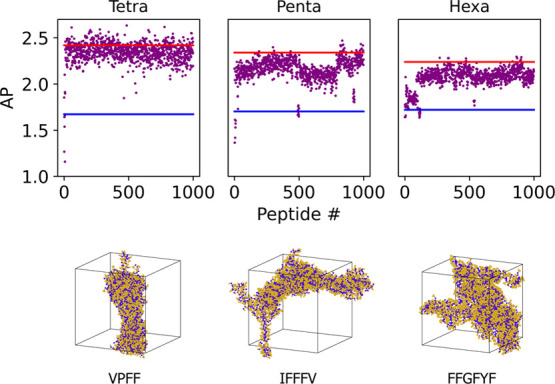
Algorithm learns to predict high AP peptides rapidly and continues to find peptides above the maximum and mean AP in the random set of 800 (red and blue lines respectively) over 100 iterations. The first iteration did not provide enough data to allow the algorithm to predict above random maximum in the second iteration (penta- and hexapeptides); the subsequent iterations show continued improvement and even self-correction (pentapeptides) where the predictions began to slide. The speed of the algorithm to learn to predict the top performing peptides is dependent on the nature of the initial iteration of random peptides and not related to the size of the data set.