
Fig. 3.
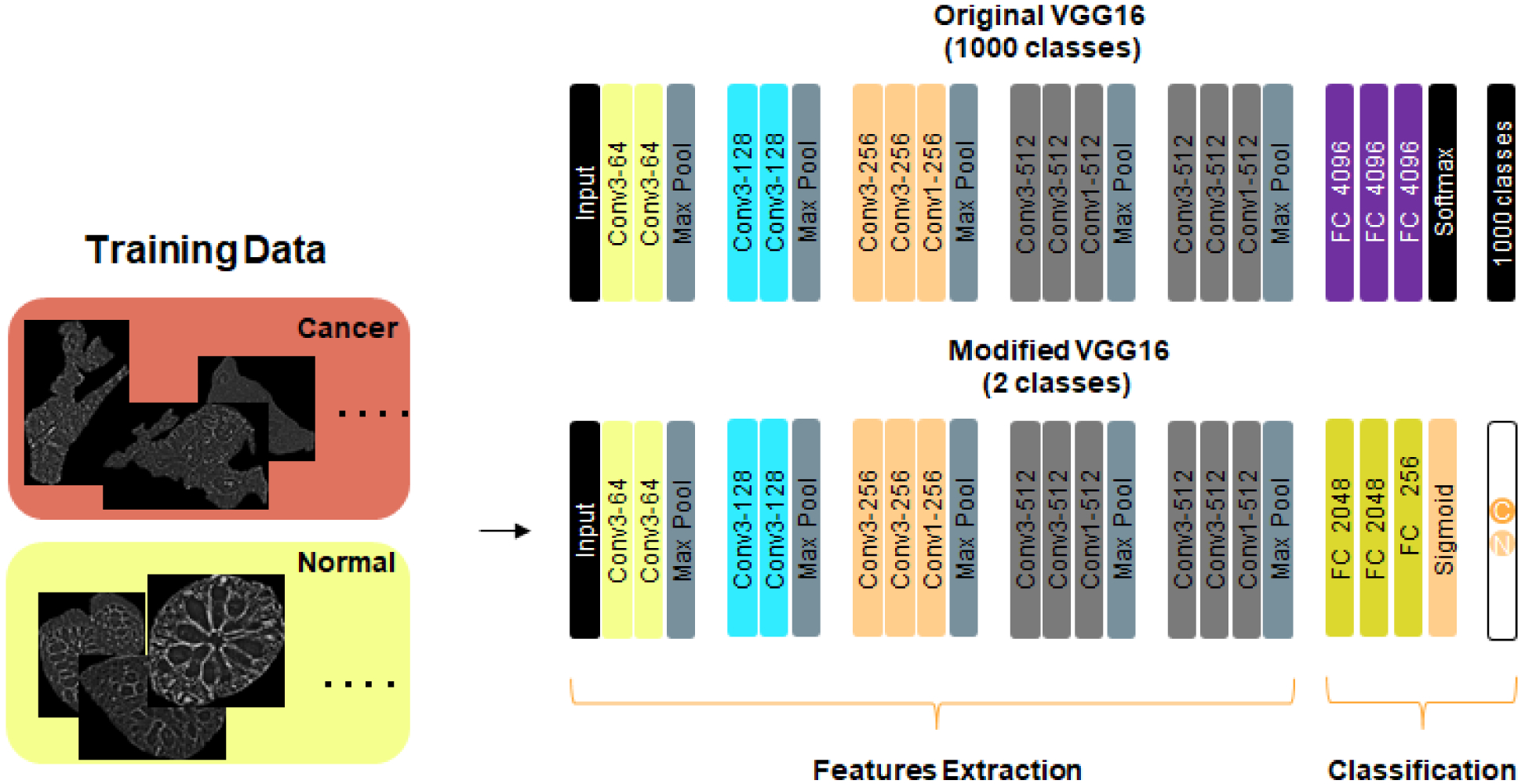
Modified VGG16 network. Input image size is 256 × 256 ×3. A pad of length 1 is added before each Max Pool layer. Conv1 : Convolutional layer with 1×1 filter; Conv3 : Convolutional layer with 3×3 filter; Max Pool: Maximum pooling layer over 2×2 pixels (stride=2); All hidden layers are followed by RELU activation. First FC layer is followed by 0.5 dropout. For the 1660 images used for training, they are split equally into 830 “normal” images and 830 “cancer” images. The images are also equally split into these two classes for the validation and the test.