
Fig. 2.
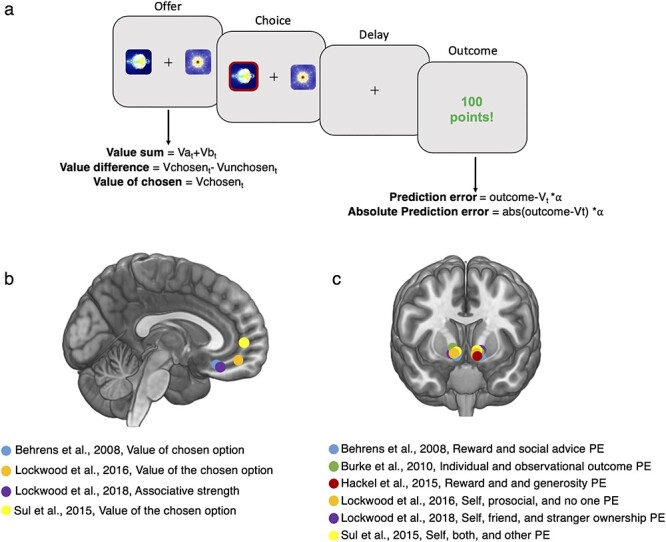
Schematic of task structure from a two-armed bandit task and associated neural signals from social reinforcement learning studies. (A) Example of a two-armed bandit task. At the offer stage, two options are presented that are probabilistically associated with a reward. In some experiments, they could also be associated with different magnitudes of reward, or both reward probability and magnitude could be varied. Participants learn by trial and error which of the two options provides a better outcome. At the time of the offer, various quantities can be modelled, including the associative strength between the picture and the outcome, the value sum, value difference or value of the chosen option. At the time of the outcome, either the signed prediction error which codes the expectedness of the outcome or an ‘absolute’ prediction error could be modelled. The absolute prediction error ignores the sign (positive or negative) of the prediction error but quantifies the overall unexpectedness of the outcome. (B) Studies of social reinforcement learning that have reported tracking of value/associative strength signals in ventromedial prefrontal cortex at the time of choice overlaid on an anatomical scan of the medial surface. (C) Studies of social reinforcement learning that have reported tracking of prediction errors that overlap in social and non-social situations at the time of an outcome in the ventral striatum overlaid on an anatomical scan. Note that a meta-analysis from NeuroSynth shows that the most robust response to the term ‘prediction error’ is in the ventral striatum (overlap from 93 studies). PE, prediction error.