
Fig. 1.
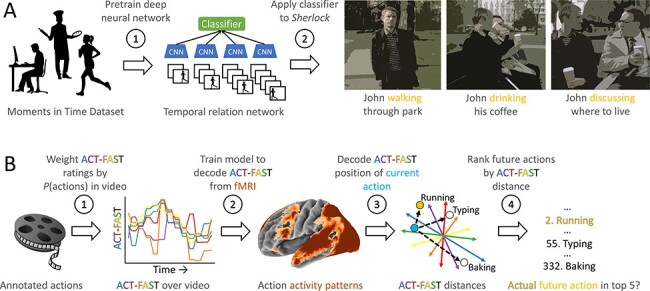
Analysis schematic. (A) Actions in Sherlock were automatically annotated using a temporal relation network pre-trained on the Moments in Time dataset. (B) These annotations were combined with ratings of where the actions fell on the ACT-FAST dimensions to produce an ACT-FAST time-series over the course of the video. These time-series were used to train a model to decode ACT-FAST coordinates from patterns of brain activity. We then created a rank order list of future actions, from most likely to least likely, ordered based on the proximity between each action in ACT-FAST space and the decoded coordinates. Accuracy was assessed by examining whether actual future actions appeared among the five ranked most likely.