
Figure 2.
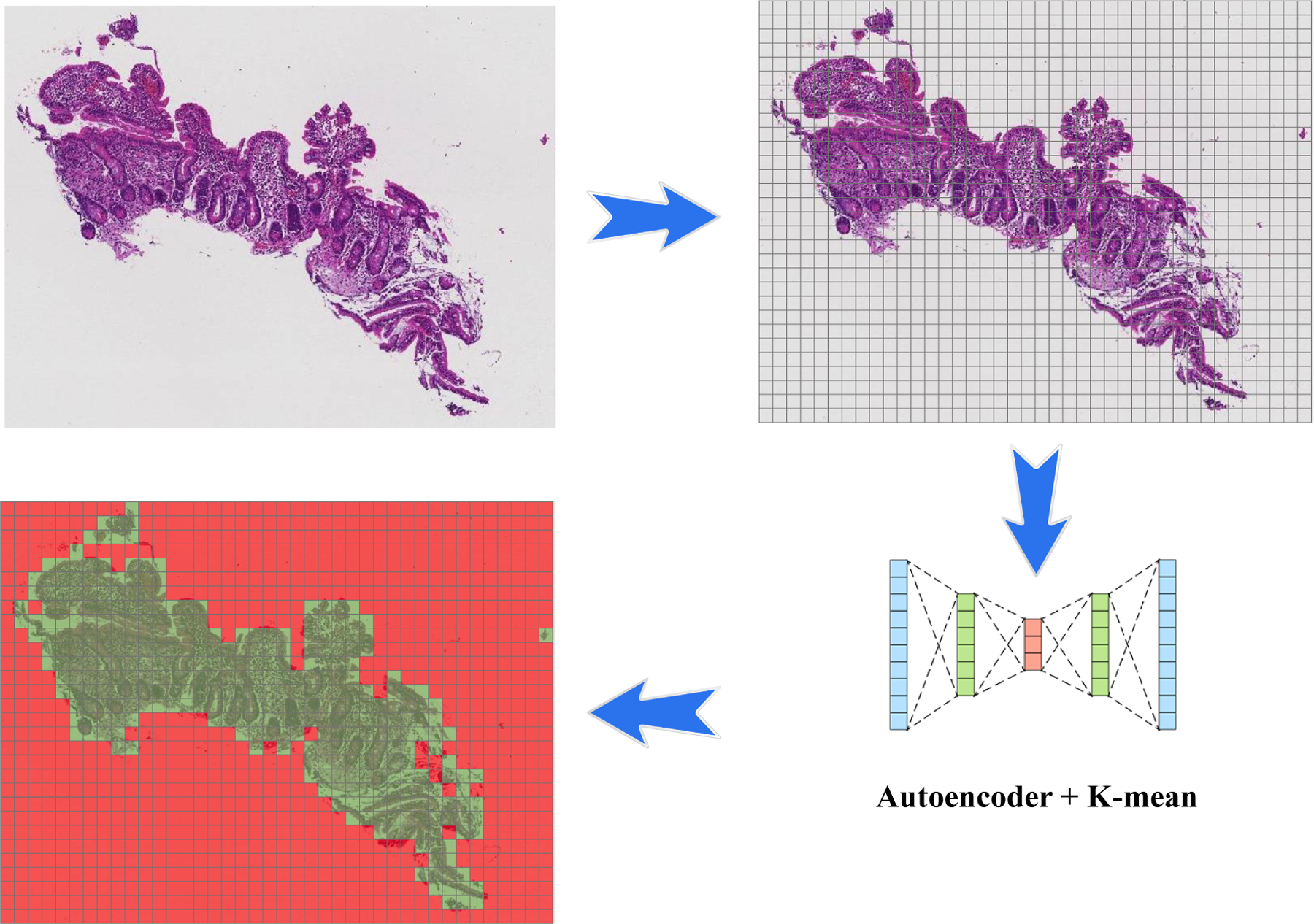
Pipeline of patching and applying an autoencoder to find useful patches for the training model. The biopsy images are very large, so we need to divide into smaller patches to be used in the machine learning model. As you can see in the image, many of these patches are empty. After using an autoencoder, we can apply a clustering algorithm to discard useless patches (green patches contain useful information, while red patches do not).