
Figure 2 .
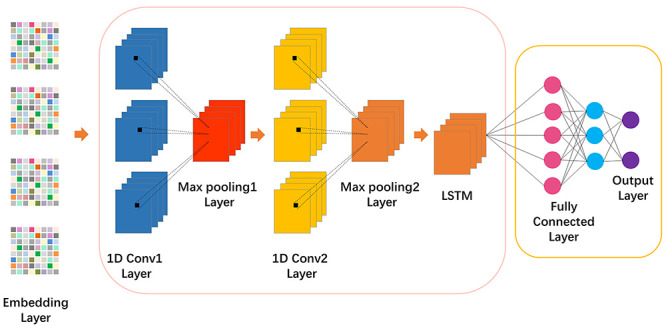
Visualization of the detailed architecture of DeepIPs. The input of DeepIPs is four different word embedding methods. The protein sequences are encoded as vectors that are fed into CNN-LSTM block. The convolution block was used for initial feature extraction and LSTM block was used to further capture the features from convolutional layer. Finally, the output of CNN-LSTM is fed into an additional fully connected layer and a Softmax layer to produce the final output.