

Abstract
Hand gesture recognition based on surface electromyography (sEMG) plays an important role in the field of biomedical and rehabilitation engineering. Recently, there is a remarkable progress in gesture recognition using high-density surface electromyography (HD-sEMG) recorded by sensor arrays. On the other hand, robust gesture recognition using multichannel sEMG recorded by sparsely placed sensors remains a major challenge. In the context of multiview deep learning, this paper presents a hierarchical view pooling network (HVPN) framework, which improves multichannel sEMG-based gesture recognition by learning not only view-specific deep features but also view-shared deep features from hierarchically pooled multiview feature spaces. Extensive intrasubject and intersubject evaluations were conducted on the large-scale noninvasive adaptive prosthetics (NinaPro) database to comprehensively evaluate our proposed HVPN framework. Results showed that when using 200 ms sliding windows to segment data, the proposed HVPN framework could achieve the intrasubject gesture recognition accuracy of 88.4%, 85.8%, 68.2%, 72.9%, and 90.3% and the intersubject gesture recognition accuracy of 84.9%, 82.0%, 65.6%, 70.2%, and 88.9% on the first five subdatabases of NinaPro, respectively, which outperformed the state-of-the-art methods.
1. Introduction
As a noninvasive approach of establishing links between muscles and devices, the surface electromyography- (sEMG-) based neural interface, also known as the muscle computer interface (MCI), has been widely studied in the past decade. Surface electromyography is a type of biomedical signal recorded by noninvasive electrodes placed on human skin [1]; it is the spatiotemporal superposition of motor unit action potential (MUAP) generated by all active motor units (MU) at different depths within the recording area [2]. sEMG recorded from subject's forearm measures muscular activity of his/her hand movements, thus, can be used for hand gesture recognition. So far, the sEMG-based gesture recognition techniques have been widely applied in rehabilitation engineering [3–5] and human-computer interaction [6–8].
From the perspective of signal recording, there are two types of sEMG signals: (1) high-density sEMG (HD-sEMG) [9–11] signals which are recorded by electrode arrays that consist of dozens, or even hundreds of electrodes arranged in a grid; (2) multichannel sEMG signals [12, 13] which are recorded by several sparsely located electrodes. For MCIs such as robotic hand prostheses and upper-limb rehabilitation robots, one of the key challenges is to precisely recognize the user's gestures through sEMG signals collected from his/her forearm. Over the past five years, feature learning approaches based on convolutional neural networks (CNNs) have shown promising success in HD-sEMG-based gesture recognition, that is, achieving >90% recognition accuracy in classifying a large set of gestures [11], and almost 100% recognition accuracy in classifying a small set of gestures [14, 15], because HD-sEMG signals contain both spatial and temporal information of muscle activity [16]. Compared to conventional feature engineering approaches based on shallow learning models, a major advantage of feature learning approaches is that the end-to-end learning capability of deep learning models enables them to automatically learn representative deep features from raw sEMG signals without any hand-crafted feature [17].
On the other hand, achieving high accuracy in multichannel sEMG-based gesture recognition performance remains a challenging task, because multichannel sEMG is noisy, random, nonstationary [18], and vulnerable to electrode shift [16] and contains much less spatial information about muscle activities than HD-sEMG [19]. So far, researchers have tried a variety of strategies to improve the multichannel sEMG-based gesture recognition performance, including extracting more representative features [20], using multimodal gesture data collected from multiple sensors [21], and developing more sophisticated deep learning models [15].
In recent years, there has emerged a trend in combining deep learning models with feature engineering techniques, as well-designed time domain (TD) [22], frequency domain (FD) [23], and time-frequency domain (TFD) [24] features have achieved remarkable success in multichannel sEMG-based gesture recognition systems. For example, Zhai et al. [25] calculated spectrograms of sEMG and used them as features for CNN-based gesture recognition and achieved 78.7% gesture recognition accuracy for recognizing 49 gestures. Hu et al. [26] extracted the Phinyomark feature set [23] from raw sEMG signals and fed them into an attention-based hybrid convolutional neural network and recurrent neural network (CNN-RNN) architecture for gesture recognition; they achieved 87% recognition accuracy for recognizing 52 gestures. Betthauser et al. [27] proposed the encoder-decoder temporal convolutional networks (ED-TCN) for sEMG-based sequential movement prediction; the inputs of their proposed ED-TCN model were composed of mean absolute value (MAV) sequences. Chen et al. [28] used continuous wavelet transform (CWT) to process the data as the input of their proposed CNN model.
In machine learning, multiview learning refers to learning from data described by different view-points or different feature sets [29, 30]. On this basis, Wei et al. [31] proposed a multiview CNN (MV-CNN) framework that constructs images generated from different sEMG features into multiview representations of multichannel sEMG. Compared to prior works that combined deep learning models with feature engineering techniques, one of the key characteristics of MV-CNN is that it adopts a “divide-and-aggregation” strategy that is able to independently learn deep features from each individual view of multichannel sEMG. The MV-CNN framework showed promising success in multichannel sEMG-based gesture recognition, as the gesture recognition accuracy achieved by MV-CNN significantly outperformed the state-of-the-art deep learning approaches.
From the perspective of multiview learning, there are generally two types of features, namely, the “view-specific feature” or “private feature” particular for each individual view and the “view-shared feature” or “public feature” shared by all views [32]. The independent learning under each individual view is able to learn view-specific features [33]; on the other hand, it is unable to learn shared information across different views [34]. The MV-CNN framework [31] did consider view-shared learning by an early fusion strategy that concatenates the output from the lowest convolutional layers of all view-specific CNN branches. However, from our perspective, the early fusion strategy used in MV-CNN is still a naive approach based on concatenation; it also ignores the original input feature spaces of different views.
Aiming at improving multichannel sEMG-based gesture recognition via better learning of view-shared deep features, in this paper, we proposed a hierarchical view pooling network (HVPN) framework, in which view-shared feature spaces were hierarchically pooled from multiview low-level features for view-shared learning. In order to build up more discriminative view-shared feature spaces, we proposed a CNN-based view pooling technique named the feature-level view pooling (FLVP) layer, which is able to learn a unified view-shared feature space from multiview low-level features. Compared to MV-CNN [31], the application of hierarchical view pooling and FLVP layer results in a wider (i.e., with more CNN branches) and deeper (i.e., with more convolutional layers in the view-shared learning branches) network architecture, respectively, thus enabling the learning of more representative view-shared deep features.
The remainder of this paper is organized as follows. Section 2 formulates the multiview learning problem, describes the databases, and details the proposed HVPN framework. Section 3 introduces the experiments in this paper and provides the experimental setup. Section 4 presents and discusses the experimental results. Finally, Section 5 concludes the paper.
2. Materials and Methods
2.1. Problem Statement
According to Wei et al. [31], the problem of multiview deep learning-based gesture recognition using multichannel sEMG signals can be formulated as
| (1) |
where v1, v2,…, vn denote multiview representations from n different views of C-channel sEMG signals x ∈ ℝC, H denotes a deep neural network with parameters θ, and y denotes the final gesture classification results.
The relationship between v1, v2,…, vn and x can be formulated as
| (2) |
where fvci, i=1,2,…, n denotes view construction functions that generate multiview representations from raw sEMG signals.
In the field of multiview deep learning, a common approach is to build up n neural networks Hli, i=1,2,…, n to learn deep representations from n views, respectively, and then use a view aggregation network Ha to fuse the learned multiview deep representations together and obtain the final decisions y. Thus, equation (1) can be written as
| (3) |
2.2. Databases
The evaluations in this work were performed offline using multichannel sEMG signals from the publicity available NinaPro databases [35]. We chose 5 subdatabases of NinaPro, which contain multichannel sEMG signals recorded from intact and transradial amputees through different types of electrodes. Details of these databases are as follows:
The first subdatabase (denoted as NinaProDB1) contains sEMG signals collected from 27 intact subjects; each subject was asked to perform 53 gestures, including 12 finger movements (denoted as Exercise A), 17 wrist movements and hand postures (denoted as Exercise B), 23 grasping and functional movement (denoted as Exercise C), and the rest movement; each gesture was repeated 10 times (i.e., 10 trials per gesture). The sEMG signals in NinaProDB1 were recorded by 10 Otto Bock 13E200-50 electrodes at a sampling rate of 100 Hz [13]. As most of the existing studies on this database excluded the rest movement for gesture recognition [10, 26, 31, 36], in our experiments we also excluded the rest movement for the convenience of performance comparison.
The second subdatabase (denoted as NinaProDB2) contains sEMG signals collected from 40 intact subjects; each subject was asked to perform 50 gestures, including Exercises B and C in NinaProDB1, 9 force patterns (denoted as Exercise D), and the rest movement; each gesture was repeated 6 times (i.e., 6 trials per gesture). The sEMG signals in NinaProDB2 were recorded by 12 Delsys Trigno Wireless electrodes at a sampling rate of 2000 Hz [13].
The third subdatabase (denoted as NinaProDB3) contains sEMG signals collected from 11 transradial amputees; each subject was asked to perform exactly the same 50 gestures as those in NinaProDB2; each gesture was repeated 6 times (i.e., 6 trials per gesture). The sEMG signals in NinaProDB3 were recorded by 12 Delsys Trigno Wireless electrodes at a sampling rate of 2000 Hz [13]. According to the authors of NinaPro database, during the sEMG recording process of NinaProDB3, three amputated subjects performed only a part of gestures due to fatigue or pain, and in two amputated subjects, the number of electrodes was reduced to ten due to insufficient space [13]. To ensure training and testing of the model can be completed, we omitted data from these subjects following the experimental configuration used by Wei et al. [31].
The fourth subdatabase (denoted as NinaProDB4) contains sEMG signals collected from 10 intact subjects; each subject was asked to perform exactly the same 53 gestures as those in NinaProDB1; each gesture was repeated 6 times (i.e., 6 trials per gesture). The sEMG signals in NinaProDB4 were recorded by the Cometa Wave Plus Wireless sEMG system with 12 electrodes, and the sampling rate was 2000 Hz [37]. After checking the data, we found that two subjects (i.e., subject 4 and subject 6) did not complete all hand movements; their data were omitted in our experiments.
The fifth subdatabase (denoted as NinaProDB5) contains sEMG signals collected from 10 intact subjects; each subject was asked to perform exactly the same 53 gestures as those in NinaProDB1; each gesture was repeated 6 times (i.e., 6 trials per gesture). Following the experimental configuration in [37], we chose 41 gestures (i.e., Exercise B and C plus rest movement) from all 53 gestures in NinaProDB5 for classification. The sEMG signals in NinaProDB5 were recorded by two Thalmic Myo armbands at a sampling rate of 200 Hz; each Myo armband contains 8 sEMG electrodes [37].
2.3. Data Preprocessing and View Construction
Due to memory limitation of the hardware, for experiments on NinaProDB2-DB4, we downsampled the sEMG signals from 2000 Hz to 100 Hz following the experimental configuration used in [31].
In multiview learning, view construction is usually defined as generation of multiple views from a single view of original data [38]. Considering the fairness of performance comparison, the view construction process in this paper was exactly the same as that in MV-CNN framework [31]. As a result, three different views of multichannel sEMG, denoted as v1, v2, and v3, are represented by images of discrete wavelet packet transform coefficients (DWPTC), discrete wavelet transform coefficients (DWTC), and the first Phinyomark's feature set (Phin_FS1) that are extracted from raw sEMG signals, respectively.
For the generation of the feature images, we followed the image generation algorithm proposed by Jiang and Yin [39], which is described in Algorithm 1.
Algorithm 1.

The image generation algorithm used in this paper [39].
Although the abovementioned three views of multichannel sEMG were proven to be the most discriminative views for gesture recognition in [31], the construction of them still requires a lot of computational time and resources, as well as their high-dimensionality results in the increase of the number of neural network parameters, making us consider the trade-off between gesture recognition accuracy and computational complexity. Thus, in this paper, we also evaluated a “two-view” configuration, which selected the two most discriminative views (i.e., v1 and v2, represented by images of DWPTC and DWTC, resp.) out of these three views of multichannel sEMG and used them as the input of the proposed HVPN framework. Details of the evaluations on the “two-view” configuration will be presented in the following sections of this paper.
For extraction of sEMG features during view construction, sliding windows were used to segment the multichannel sEMG. Early studies in MCI have pointed out that the response time of a real-time MCI system should be kept below 300 ms to avoid a time delay perceived by the user [40, 41]. For this reason, the sliding window length was set to 200 ms for most of the experiments, and the window increment was set to 10 ms except for experiments on NinaProDB5 using the sliding window length of 200 ms. For experiments on NinaProDB5 using 200 ms sliding windows, we followed the experimental configuration used by Pizzolato et al. [37] and Wei et al. [31], which set the window increment to 100 ms.
Suppose the images that represent the ith view have an sEMG feature dimension of Mi and an sEMG channel dimension of C, the Mi × C (width, height, respectively, depth = 1) feature space of vi is firstly transformed into an Mi × C × 1 (depth, width, and height, respectively) feature space before it is input into neural network architecture of HVPN for gesture recognition. The transformation is based on the experimental results presented in [15], where the 20 × 10 × 1 (depth, width, and height, respectively) sEMG images significantly outperformed the 1 × 20 × 10 (depth, width, and height, respectively) sEMG images as the input of an end-to-end CNN in gesture recognition using 10-channel sEMG signals segmented by 20-frame sliding window.
2.4. The HVPN Framework
A diagram of our proposed HVPN framework with all three views of multichannel sEMG is illustrated in Figure 1. The deep learning architecture of HVPN can be divided into three parts: view-specific CNNs, hierarchical view pooling CNNs, and a view aggregation network. For HVPN with the “two-view” configuration, there are two view-specific CNN branches to learn view-specific deep features from v1 and v2, respectively, and other parts are almost the same as those illustrated in Figure 1. The following sections describe the detailed network architecture and hyperparameter configurations of these parts.
Figure 1.
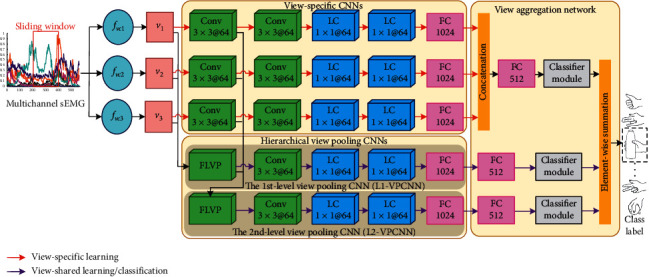
A schematic diagram of the proposed HVPN framework. FLVP, Conv, LC, and FC denote the feature-level view pooling layer, convolutional layer, locally connected layer, and fully connected layer, respectively. The numbers after the layer name denote the size and number of the filters or neurons; for example, Conv 3 × 3@64 denotes a CNN with 64 3 × 3 filters, and FC 1024 denotes an FC layer with 1024 hidden units.
2.5. View-Specific CNNs
After view construction, we built up three view-specific CNN branches to learn view-specific deep features from v1, v2, and v3, respectively. As shown in Figure 1, all view-specific CNN branches share the same network architecture but do not share their weights. The network architecture of each view-specific CNN branch is based on GengNet [10], which has been extensively used in sEMG-based gesture recognition [15, 31, 42]. Specifically, the images of each view are input into two convolutional layer with 64 3 × 3 filters (stride = 1), followed by two locally connected (LC) layers with 64 1 × 1 filters (stride = 1) and one fully connected (FC) layer with 1024 hidden units. For each CNN branch, we applied batch normalization and the ReLU nonlinearity function after each layer and added dropout layers to the FC layer and the last LC layer to prevent overfitting. The input of each CNN is also normalized through batch normalization.
2.6. Hierarchical View Pooling CNNs
The hierarchical view pooling CNNs are composed of two CNN branches, namely, the first-level view pooling CNN (denoted as L1-VPCNN) and the second-level view pooling CNN (denoted as L2-VPCNN); each of them starts with an FLVP layer, which is used to learn a view-shared feature space from multiview low-level features. As illustrated in Figure 2, the FLVP layer firstly concatenates the input feature maps from different views together and then learns a unified feature space from the concatenated feature maps through a 1 × 1 convolutional layer with 64 filters. The FLVP layers in our proposed HVPN framework play two important roles: (1) each of them learns a unified feature space shared by all views from concatenated multiview low-level features for view-shared learning; (2) compared with the extensively used view pooling technique based on simple element-wise maximum [43] or average [44] operation, each FLVP layer can guarantee that its corresponding hierarchical view pooling CNN branch is deep enough to learn representative features.
Figure 2.
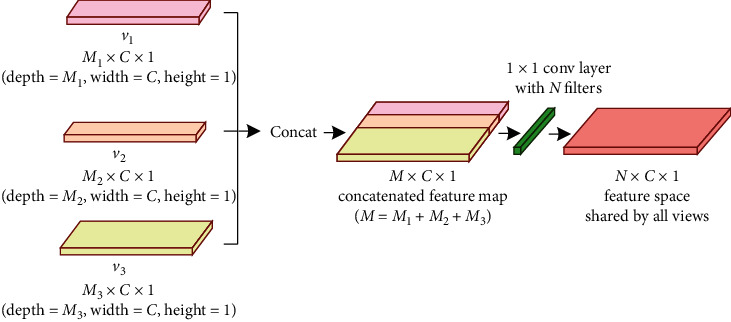
Diagram of the FLVP layer.
Suppose we have v1 ∈ ℝM1×C×1, v2 ∈ ℝM2×C×1, v3 ∈ ℝM3×C×1, and the multiview low-level features learned by the bottom convolutional layers of three view-specific CNN branches are , respectively. The hierarchical view pooling process by FLVP layers can be formulated as follows.
The 1st-level view pooling:
| (4) |
The 2nd-level view pooling:
| (5) |
where ‖ denotes the feature-level concatenation operation, denotes the learned feature space after level-i view pooling, Hfvi denotes the FLVP layer in Li-VPCNN, and θfvi denotes its parameters.
The remaining parts of L1-VPCNN and L2-VPCNN perform view-shared learning from and , respectively. They share the same network architecture, which is composed of one convolutional layer with 64 3 × 3 filters (stride = 1), followed by two LC layers with 64 1 × 1 filters (stride = 1) and one FC layer with 1024 hidden units.
2.7. View Aggregation Network
The view aggregation network is used for the following: (1) the fusion of all view-specific CNN branches and hierarchical view pooling CNN branches and (2) final gesture classification. As shown in Figure 1, the view aggregation network adopts a two-step view aggregation strategy. Specifically, it concatenates the output view-specific deep features learned by three view-specific CNN branches together at first. Then, the concatenated view-specific deep features and the view-shared deep features learned by L1-VPCNN and L2-VPCNN are input into three branches, respectively. Each branch consists of one FC layer with 512 hidden units and a classifier module, and each classifier module is composed of a G-way FC layer and a softmax classifier for gesture classification. At the top of HVPN, there is an element-wise summation operation that sums up the softmax scores predicted by all three classifier modules together to form the final classification results.
2.8. Evaluation Metric and Methodology
For experiments in this study, we calculated the gesture recognition accuracy for each subject as the evaluation metric, which is defined as
| (6) |
The evaluation methodology in this paper can be categorized into intrasubject evaluation and intersubject evaluation. Generally speaking, in intrasubject evaluation, the deep learning model is trained on a part of the data from one subject and tested on the nonoverlapping part of the data from the same subject, whereas in intersubject evaluation, the deep learning model is usually trained on data from one or a group of subjects and tested on data from another group of subjects.
For fair performance comparison, we adopted the same intrasubject and intersubject evaluation schemes as those were most commonly used in existing studies on NinaPro database [10, 13, 26, 31, 36, 42], which are described as follows.
Intrasubject Evaluation. For intrasubject evaluation, we followed the evaluation scheme proposed by the NinaPro team [13]. Specifically, for each subject, approximately 2/3 of the gesture trials are used as the training set; the remaining gesture trials constitute the test set. The final gesture recognition accuracy is obtained by averaging the achieved accuracy over all subjects. The selection of gesture trials for training and testing are based on the literature [13, 37].
Intersubject Evaluation. For intersubject evaluation, we followed the leave-one-subject-out cross-validation (LOSOCV) scheme used in the literature [31, 36, 42]. Specifically, in each fold of the cross-validation, data from one subject is used as the test set, and data from the remaining subjects is used as the training set. The final gesture recognition accuracy of the evaluation is obtained by averaging the achieved accuracy over all folds.
Specifications of the evaluation methodology on different sEMG databases are presented in Table 1.
Table 1.
Specifications of the evaluation methodology on different sEMG databases.
| Databases | Intrasubject | Intersubject | |
| Trials for training | Trials for testing | ||
|
| |||
| NinaPro DB1 | 1st, 3rd, 4th, 6th, 7th, 8th, 9th | 2nd, 5th, 10th | LOSOCV |
| NinaPro DB2 | 1st, 3rd, 4th, 6th | 2nd, 5th | LOSOCV |
| NinaPro DB3 | 1st, 3rd, 4th, 6th | 2nd, 5th | LOSOCV |
| NinaPro DB4 | 1st, 3rd, 4th, 6th | 2nd, 5th | LOSOCV |
| NinaPro DB5 | 1st, 3rd, 4th, 6th | 2nd, 5th | LOSOCV |
2.9. Deep Domain Adaptation for Intersubject Evaluation
In intersubject evaluation, the training (i.e., source domain) and test (i.e., target domain) data comes from two nonoverlapping groups of subjects; thus, there exist distribution mismatch and domain shift across the source target domain caused by electrode shifts, changes in arm position, muscle fatigue, skin condition [45], and individual differences among subjects [46], which may dramatically degrade the classification performance of the model [47].
To reduce the negative effect of distribution mismatch and domain shift on classification performance, a number of existing deep learning based approaches [31, 42, 48] in this field have applied a novel unsupervised deep domain adaptation technique named multistream AdaBN (MS-AdaBN) [42]. The MS-AdaBN technique uses a multistream network to incrementally update the batch normalization statistics of the network training process with the calibration data.
In this work, the MS-AdaBN was also implemented for deep domain adaptation in LOSOCV, because our preliminary experiments on NinaProDB1 revealed that the LOSOCV accuracy achieved by our proposed model without deep domain adaptation is far from practical applications (i.e., <30%). Similar results were achieved by MV-CNN and reported by Wei et al. [31].
For selection of training, calibration, and test data, we followed exactly the same MS-AdaBN configuration as that used in previous works [31, 42]. It should be mentioned that as MS-AdaBN requires a relatively large amount of calibration data, it may not be the best solution for domain adaptation in the context of multichannel sEMG-based gesture recognition. Nevertheless, MS-AdaBN is not a contribution of this work, and we used it in our experiments because we wanted to ensure a fair comparison of LOSOCV accuracy between our proposed method and the previously proposed MV-CNN [31], which is a multiview deep learning framework that also adopted MS-AdaBN for domain adaptation.
3. Experiments
All experiments were performed offline (i.e., not real-time) on a DevMax401 workstation with NVIDIA GeForce GTX1080Ti GPU. The proposed HVPN framework was trained using the stochastic gradient descent (SGD) optimizer with 28 epochs. For all experiments, the batch size was set to 1000, and a learning rate decay strategy was adopted during training to improve convergence, which initialized the learning rate at 0.1 and divided it by 10 after 16 and 24 epochs. For all layers with dropout, the dropout rate was set to 0.65 during training.
3.1. Evaluation of the Hierarchical View Pooling Strategy
Evaluation of the hierarchical view pooling strategy can be divided into two steps. First, we carried an ablation study to verify the effectiveness of FLVP layer. Second, we carried out an ablation study to validate the effectiveness of the proposed hierarchical view pooling CNNs. For all experiments in these ablation studies, the sliding window length was set to 200 ms.
In the first step of the evaluation, the standard HVPN was firstly compared with its two variants, namely, HVPN-maxpool and HVPN-avgpool, on five databases (i.e., NinaProDB1-DB5). In HVPN-maxpool, the FLVP layer in L2-VPCNN was replaced by view pooling based on element-wise maximum, while in HVPN-avgpool the FLVP layer in L2-VPCNN was replaced by view pooling based on element-wise average. Meanwhile, the FLVP layers in the L1-VPCNN of HVPN-maxpool and HVPN-avgpool were retained, because the input feature spaces of L1-VPCNN have different sizes, which make it impossible for performing element-wise maximum or average operation among them.
In the second step of the evaluation, the proposed HVPN was compared with the following deep neural network architectures:
VS-L1VP: a deep network that is equivalent to HVPN without the L2-VPCNN.
VS-L2VP: a deep network that is equivalent to HVPN without the L1-VPCNN.
VS-ONLY: a deep network that only consists of view-specific CNNs, followed by a concatenation operation that fuses their output together, a FC layer with 512 hidden units and a classifier module.
The schematic illustration of VS-L1VP, VS-L2VP, and VS-ONLY is depicted in Figure 3. Compared to HVPN that contains hierarchical view pooling CNNs, there is only one view pooling CNN in VS-L1VP, as well as VS-L2VP, for view-shared learning.
Figure 3.
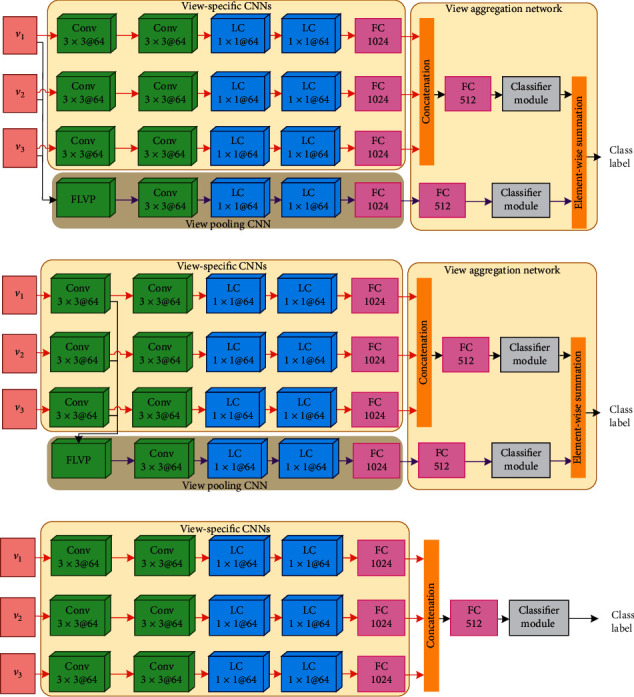
Schematic diagrams of (a) VS-L1VP, (b) VS-L2VP, and (c) VS-ONLY.
3.2. Comparison with Related Works
The gesture recognition accuracy achieved by the proposed HVPN framework, as well as the gesture recognition accuracy achieved by the proposed HVPN framework with the “two-view” configuration (denoted as HVPN-2-view), was further compared with related works on five databases (i.e., NinaProDB1-DB5). For the aim of fairness in this comparison, among various machine learning methods that were proposed for sEMG-based gesture recognition and tested on NinaPro, we only considered the ones that meet the following requirements: (1) their reported gesture recognition accuracy was achieved using exactly the same intrasubject or intersubject gesture recognition schemes as described in Section 2; (2) the input of their machine learning models were engineered features, not raw sEMG signals.
To prevent overfitting, a pretraining strategy that has been widely used by the compared methods [26, 31] was also adopted in this work. Specifically, for each experiment, a pretrained model was firstly trained using all available training data; then, the gesture recognition model for each subject was initialized by the pretrained model. For all layers with dropout, the dropout rate was set to 0.5 during the pretraining stage.
For comparison of intrasubject gesture recognition accuracy, we evaluated the gesture recognition accuracy achieved with 50 ms, 100 ms, 150 ms, and 200 ms sliding windows. Moreover, the gesture recognition accuracy obtained by majority voting on all 200 ms windows within each trial is also presented in the column labeled “Trial.” For comparison of LOSOCV (i.e., intersubject gesture recognition) accuracy, we only evaluated the gesture recognition accuracy achieved with 200 ms sliding windows.
4. Results and Discussion
4.1. Multichannel sEMG-Based Gesture Recognition Enhanced by Hierarchical View Pooling
Table 2 presents the intrasubject and LOSOCV accuracy achieved by the standard HVPN, HVPN-maxpool, and HVPN-avgpool on five databases. The proposed HVPN framework achieved the intrasubject gesture recognition accuracy of 86.8%, 84.4%, 68.2%, 70.8%, and 88.6% on NinaProDB1, DB2, DB3, DB4, and DB5, respectively, and achieved the LOSOCV accuracy of 83.1%, 79.0%, 65.6%, 67.0%, and 87.1% on NinaProDB1, DB2, DB3, DB4, and DB5, respectively. The gesture recognition accuracy achieved by HVPN was higher than that achieved by HVPN-maxpool and HVPN-avgpool in all experiments, indicating that the FLVP layer can achieve better gesture recognition accuracy than the conventional view pooling approaches based on element-wise maximum or average operation. However, when evaluated on NinaProDB1, DB2, DB3, and DB4, the performance improvement brought by the FLVP layer was subtle (i.e., from +0.2% to +0.4% over element-wise max or average pooling). This is likely due to the fact that in HVPN-maxpool and HVPN-avgpool we only replaced the FLVP layer in L2-VPCNN with conventional view pooling, making them very similar to the original HVPN.
Table 2.
Gesture recognition accuracy achieved by the standard HVPN, HVPN-maxpool, and HVPN-avgpool on five databases.
| Database | Evaluation methodology | HVPN | HVPN-maxpool | HVPN-avgpool |
|
| ||||
| NinaProDB1 | Intrasubject | 86.8% | 86.4% | 86.5% |
| NinaProDB2 | Intrasubject | 84.4% | 84.1% | 84.1% |
| NinaProDB3 | Intrasubject | 68.2% | 68.0% | 67.9% |
| NinaProDB4 | Intrasubject | 70.8% | 70.5% | 70.5% |
| NinaProDB5 | Intrasubject | 88.6% | 88.1% | 88.1% |
|
| ||||
| NinaProDB1 | LOSOCV | 83.1% | 82.7% | 82.8% |
| NinaProDB2 | LOSOCV | 79.0% | 78.8% | 78.7% |
| NinaProDB3 | LOSOCV | 65.6% | 65.4% | 65.3% |
| NinaProDB4 | LOSOCV | 67.0% | 66.6% | 66.6% |
| NinaProDB5 | LOSOCV | 87.1% | 86.4% | 86.6% |
Results in bold entries indicate best performance.
Table 3 presents the intrasubject and LOSOCV accuracy achieved by HVPN, VS-L1VP, VS-L2VP, and VS-ONLY on five databases (i.e., NinaProDB1-DB5). According to the experimental results in Table 3, the deep neural network architectures with view pooling CNNs (i.e., HVPN, VS-L1VP, and VS-L2VP) significantly outperformed VS-ONLY, indicating that combining view-specific learning with view-shared learning is better than performing view-specific learning alone in the context of multiview deep learning for multichannel sEMG-based gesture recognition. Moreover, the intrasubject and LOSOCV accuracy achieved by HVPN was higher than that achieved by VS-L1VP and VS-L2VP on all databases, which proves the effectiveness of our proposed hierarchical view pooling strategy in improving gesture recognition accuracy.
Table 3.
Gesture recognition accuracy achieved by HVPN, VS-L1VP, VS-L2VP, and VS-ONLY on five databases.
| Database | Evaluation methodology | HVPN | VS-L1VP | VS-L2VP | VS-ONLY |
|
| |||||
| NinaProDB1 | Intrasubject | 86.8% | 86.5% | 86.2% | 85.8% |
| NinaProDB2 | Intrasubject | 84.4% | 84.1% | 83.9% | 83.4% |
| NinaProDB3 | Intrasubject | 68.2% | 67.7% | 67.5% | 67.2% |
| NinaProDB4 | Intrasubject | 70.8% | 69.9% | 69.7% | 68.5% |
| NinaProDB5 | Intrasubject | 88.6% | 87.9% | 88.3% | 87.2% |
|
| |||||
| NinaProDB1 | LOSOCV | 83.1% | 82.6% | 82.5% | 81.9% |
| NinaProDB2 | LOSOCV | 79.0% | 78.7% | 78.7% | 78.1% |
| NinaProDB3 | LOSOCV | 65.6% | 65.5% | 65.0% | 64.7% |
| NinaProDB4 | LOSOCV | 67.0% | 66.3% | 65.7% | 65.2% |
| NinaProDB5 | LOSOCV | 87.1% | 86.2% | 86.5% | 84.7% |
Results in bold entries indicate best performance.
4.2. Comparison with Related Works Based on Intrasubject Evaluation
Table 4 presents the intrasubject gesture recognition accuracy achieved by various methods on the first five subdatabases of NinaPro. Among these methods, the methods proposed in [13, 36, 37] are shallow learning frameworks, the methods proposed in [25–27, 49, 50] are single-view deep learning frameworks, and the method proposed in [31] is a multiview deep learning framework (i.e., MV-CNN). All the above-mentioned methods are non-end-to-end methods using engineered sEMG features as their input, and they used exactly the same intrasubject evaluation scheme as that was used in our work.
Table 4.
Intrasubject gesture recognition accuracy in comparison with related works on five databases.
| Machine learning (ML) model | Type of ML model | Input of ML model | Database | Num. of gestures for classification | Window length | ||||
| 50 ms | 100 ms | 150 ms | 200 ms | Trial | |||||
|
| |||||||||
| Random forests [13] | Shallow learning | 5 hand-crafted features | NinaProDB1 | 50 | N.A. | N.A. | N.A. | 75.3% | N.A. |
| Dictionary learning [36] | Shallow learning | MLSVD-based features | NinaProDB1 | 52 | N.A. | N.A. | N.A. | N.A. | 97.4% |
| HuNet [26] | CNN-RNN | Phinyomark feature set | NinaProDB1 | 52 | N.A. | N.A. | 86.8% | 87.0% | 97.3% |
| MV-CNN [31] | Multiview CNN | 3 views of sEMG | NinaProDB1 | 52 | 85.8% | 86.8% | 87.4% | 88.2% | N.A. |
| ChengNet [49] | CNN | Multi-sEMG-features image | NinaProDB1 | 52 | N.A. | N.A. | N.A. | 82.5% | N.A. |
| HVPN-2-view | Multi-view CNN | 2 views of sEMG | NinaProDB1 | 52 | 85.4% | 86.5% | 87.2% | 88.1% | 97.8% |
| HVPN | Multi-view CNN | Same as [31] | NinaProDB1 | 52 | 86.0% | 86.9% | 87.7% | 88.4% | 98.0% |
|
| |||||||||
| Random forests [13] | Shallow learning | Hand-crafted features | NinaProDB2 | 50 | N.A. | N.A. | N.A. | 75.3% | N.A. |
| ZhaiNet [25] | CNN | sEMG spectrogram | NinaProDB2 | 50 | N.A. | N.A. | N.A. | 78.7% | N.A. |
| HuNet [26] | CNN-RNN | Phinyomark feature set | NinaProDB2 | 50 | N.A. | N.A. | N.A. | 82.2% | 97.6% |
| MV-CNN [31] | Multiview CNN | 3 views of sEMG | NinaProDB2 | 50 | 80.6% | 81.1% | 82.7% | 83.7% | N.A. |
| HVPN-2-view | Multiview CNN | 2 views of sEMG | NinaProDB2 | 50 | 82.7% | 83.8% | 83.3% | 85.0% | 97.8% |
| HVPN | Multiview CNN | Same as [31] | NinaProDB2 | 50 | 82.3% | 84.1% | 84.8% | 85.8% | 98.1% |
|
| |||||||||
| Support vector machine (SVM) [13] | Shallow learning | 5 hand-crafted features | NinaProDB3 | 50 | N.A. | N.A. | N.A. | 46.3% | N.A. |
| MV-CNN [31] | Multiview CNN | 3 views of sEMG | NinaProDB3 | 50 | N.A. | N.A. | N.A. | 64.3% | N.A. |
| ED-TCN [27] | TCN | MAV sequences | NinaProDB3 | 41 | N.A. | N.A. | 63.5% | N.A. | N.A. |
| HVPN-2-view | Multiview CNN | 2 views of sEMG | NinaProDB3 | 50 | 64.4% | 65.7% | 66.8% | 67.9% | 80.3% |
| HVPN | Multiview CNN | Same as [31] | NinaProDB3 | 50 | 64.5% | 65.9% | 66.9% | 68.2% | 80.7% |
|
| |||||||||
| Random forests [37] | Shallow learning | mDWT features | NinaProDB4 | 53 | N.A. | N.A. | N.A. | 69.1% | N.A. |
| MV-CNN [31] | Multiview CNN | 3 views of sEMG | NinaProDB4 | 53 | N.A. | N.A. | N.A. | 54.3% | N.A. |
| HVPN-2-view | Multiview CNN | 2 views of sEMG | NinaProDB4 | 53 | 60.1% | 63.2% | 67.6% | 72.1% | 81.1% |
| HVPN | Multiview CNN | Same as [31] | NinaProDB4 | 53 | 58.3% | 67.1% | 70.5% | 72.9% | 81.7% |
|
| |||||||||
| SVM [37] | Shallow learning | mDWT features | NinaProDB5 | 41 | N.A. | N.A. | N.A. | 69.0% | N.A. |
| ShenNet [50] | Stacking-based CNN | TD, FD and TFD features | NinaProDB5 | 40 | N.A. | N.A. | N.A. | 72.1% | N.A. |
| MV-CNN [31] | Multiview CNN | 3 views of sEMG | NinaProDB5 | 41 | N.A. | N.A. | N.A. | 90.0% | N.A. |
| HVPN-2-view | Multiview CNN | 2 views of sEMG | NinaProDB5 | 41 | 88.7% | 89.1% | 89.9% | 90.1% | 98.8% |
| HVPN | Multiview CNN | Same as [31] | NinaProDB5 | 41 | 88.7% | 89.3% | 90.0% | 90.3% | 98.4% |
N.A. denotes not applicable, and bold entries indicate our proposed method. HVPN-2-view refers to the proposed HVPN framework with the “two-view” configuration (i.e., using v1 and v2 as its input). †It should be mentioned that existing MCIs seldom segment raw sEMG signals by trial due to the constraint that the maximal response time of an MCI should be kept below 300 ms [40, 41]. ‡For experiments on HVPN, the predicted class label of each gesture trial is obtained by majority voting on all 200 ms sliding windows within it.
Experimental results in Table 4 demonstrate that when using all three views of multichannel sEMG as input, the proposed HVPN achieved the intrasubject gesture recognition accuracy of 88.4%, 85.8%, 68.2%, 72.9%, and 90.3% on NinaProDB1, DB2, DB3, DB4, and DB5, respectively, with the sliding window length of 200 ms, which outperformed not only shallow learning frameworks [13, 36, 37] but also deep learning frameworks [25, 26, 31, 49, 50] that were proposed for sEMG-based gesture recognition in recent years.
Compared to MV-CNN, which is also a multiview deep learning framework, experimental results show the following: (1) when using exactly the same input, the gesture accuracy achieved by MV-CNN was significantly inferior to that achieved by HVPN on all databases; (2) when the number of input views of HVPN was reduced to two (i.e., denoted as HVPN-2-view in Table 4), it still outperformed MV-CNN framework on most of the databases (i.e., NinaPro DB2, DB3, DB4, and DB5), and their gesture recognition accuracy on NinaProDB1 was almost the same. For example, when the sliding window length was set to 200 ms, the HVPN-2-view achieved the intrasubject gesture recognition accuracy of 88.1%, 85.0%, 67.9%, 72.1%, and 90.1% on NinaPro DB1, DB2, DB3, DB4, and DB5, respectively. By comparison, the intrasubject gesture recognition accuracy achieved by MV-CNN on NinaPro DB1, DB2, DB3, DB4, and DB5 was 88.2%, 83.7%, 64.3%, 54.3%, and 90.0%, respectively. These results indicate that compared to MV-CNN, the HVPN framework can achieve better or similar intrasubject gesture recognition accuracy using less input data.
We also found that the intrasubject gesture recognition accuracy achieved by MV-CNN on NinaPro DB4 was much lower than that achieved by a shallow learning method (i.e., random forests [37]). By comparison, our proposed HVPN achieved the intrasubject gesture recognition accuracy of 72.9% on NinaPro DB4, with the sliding window length of 200 ms, which significantly outperformed both MV-CNN [31] and the random forests-based method [37].
4.3. Comparison with MV-CNN Based on Intersubject Evaluation
As very few studies in this field have presented the LOSOCV accuracy of recognizing all gestures in any of the NinaPro subdatabases, considering the difference in evaluation methodology and domain adaptation strategy, in this section, we focused on comparison with the MV-CNN framework [31], which used exactly the same intersubject evaluation scheme and domain adaptation technique as our proposed HVPN framework.
The LOSOCV accuracy achieved by MV-CNN and our proposed HVPN framework on five databases is presented in Table 5. The MV-CNN framework achieved the LOSOCV accuracy of 84.3%, 80.1%, 55.5%, 52.6%, and 87.2% on NinaProDB1, DB2, DB3, DB4, and DB5, respectively, with the sliding window length of 200 ms. By comparison, the HVPN framework achieved the LOSOCV accuracy of 84.9%, 82.0%, 65.6%, 70.2%, and 88.9% on NinaPro DB1, DB2, DB3, DB4, and DB5, respectively, with the sliding window length of 200 ms, which significantly outperformed MV-CNN. Similar to the results of intrasubject evaluation, the LOSOCV accuracy achieved by HVPN framework with the “two-view” configuration (i.e., denoted as HVPN-2-view in Table 5) also outperformed that achieved by MV-CNN framework on all databases, indicating that HVPN framework can achieve better LOSOCV accuracy than MV-CNN using less input data.
Table 5.
LOSOCV accuracy in comparison with MV-CNN on five databases.
| ML model | Type of ML model | Domain adaptation method | Database | Num. of gestures for classification | LOSOCV accuracy (achieved with 200 ms window) |
|
| |||||
| MV-CNN [31] | Multiview CNN | MS-AdaBN | NinaProDB1 | 52 | 84.3% |
| HVPN-2-view | Multiview CNN | MS-AdaBN | NinaProDB1 | 52 | 84.5% |
| HVPN | Multiview CNN | MS-AdaBN | NinaProDB1 | 52 | 84.9% |
|
| |||||
| MV-CNN [31] | Multiview CNN | MS-AdaBN | NinaProDB2 | 50 | 80.1% |
| HVPN-2-view | Multiview CNN | MS-AdaBN | NinaProDB2 | 50 | 81.8% |
| HVPN | Multiview CNN | MS-AdaBN | NinaProDB2 | 50 | 82.0% |
|
| |||||
| MV-CNN [31] | Multiview CNN | MS-AdaBN | NinaProDB3 | 50 | 55.5% |
| HVPN-2-view | Multiview CNN | MS-AdaBN | NinaProDB3 | 50 | 65.4% |
| HVPN | Multiview CNN | MS-AdaBN | NinaProDB3 | 50 | 65.6% |
|
| |||||
| MV-CNN [31] | Multiview CNN | MS-AdaBN | NinaProDB4 | 53 | 52.6% |
| HVPN-2-view | Multiview CNN | MS-AdaBN | NinaProDB4 | 53 | 69.9% |
| HVPN | Multiview CNN | MS-AdaBN | NinaProDB4 | 53 | 70.2% |
|
| |||||
| MV-CNN [31] | Multiview CNN | MS-AdaBN | NinaProDB5 | 41 | 87.2% |
| HVPN-2-view | Multiview CNN | MS-AdaBN | NinaProDB5 | 41 | 88.8% |
| HVPN | Multiview CNN | MS-AdaBN | NinaProDB5 | 41 | 88.9% |
N.A. denotes not applicable, and bold entries indicate our proposed method. HVPN-2-view refers to the proposed HVPN framework with the “two-view” configuration (i.e., using v1 and v2 as its input).
5. Conclusions
This paper proposed and implemented a hierarchical view pooling network (HVPN) framework, which improves multichannel sEMG-based gesture recognition by not only view-specific learning under each individual view but also view-shared learning in feature spaces that are hierarchically pooled from multiview low-level features.
Ablation studies were conducted on five multichannel sEMG databases (i.e., NinaPro DB1–DB5) to validate the effectiveness of the proposed framework. Results show the following: (1) when the FLVP layer in L2-VPCNN was replaced by conventional view pooling based on element-wise max pooling or average pooling, both intrasubject and LOSOCV accuracy degraded; (2) the proposed HVPN outperformed its two simplified variants that have only one view pooling CNN, as well as a deep neural network architecture that only consists of view-specific CNNs, in both intrasubject evaluation and LOSOCV. According to the above results, the effectiveness of the proposed hierarchical view pooling strategy can be proven.
Furthermore, we carried out performance comparison with the state-of-the-art methods on five databases (i.e., NinaPro DB1–DB5). Experimental results have demonstrated the superiority of the proposed HVPN framework over other deep learning and shallow learning-based methods. When using sliding windows of 200 ms, the proposed HVPN achieved the intrasubject gesture recognition accuracy of 88.4%, 85.8%, 68.2%, 72.9%, and 90.3% on NinaPro DB1, DB2, DB3, DB4, and DB5, respectively. The LOSOCV accuracy achieved on NinaPro DB1, DB2, DB3, DB4, and DB5 using 200 ms sliding windows was 84.9%, 82.0%, 65.6%, 70.2%, and 88.9%, respectively.
Limited by experimental conditions, we only considered offline experiments to verify our proposed HVPN framework. Our future work will focus on online evaluation of the proposed multiview deep learning framework. Moreover, in the future, we will investigate the integration of our proposed framework with hardware systems, such as upper-limb prostheses [51, 52] and space robots [53, 54] that are driven by multichannel sEMG signals.
Acknowledgments
The authors thank the NinaPro team for providing the publicity available sEMG databases. This work was supported in part by the National Natural Science Foundation of China under Grant nos. 62002171 and 61871224, the Natural Science Foundation of Jiangsu Province under Grant BK20200464, the National Key Research and Development Program of China under Grant 2020YFC2005302, and the Jiangsu Provincial Key Research and Development Program under Grant BE2018729.
Data Availability
The multichannel sEMG data supporting the findings of this study are from the NinaPro dataset, which is publicly available at http://ninapro.hevs.ch. Papers describing the NinaPro dataset are cited at relevant places within the text as references [13, 37]. The processed data and trained deep learning models used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
References
- 1.Beanbonyka R., Nak-Jun S., Sedong M., Min H. Deep learning in physiological signal data: a survey. Sensors. 2020;20(4):p. 969. doi: 10.3390/s20040969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Chen X., Wang S., Huang C., Cao S., Zhang X. ICA-based muscle-tendon units localization and activation analysis during dynamic motion tasks. Medical & Biological Engineering & Computing. 2018;56(3):341–353. doi: 10.1007/s11517-017-1677-z. [DOI] [PubMed] [Google Scholar]
- 3.Li C., Li G., Jiang G., Chen D., Liu H. Surface EMG data aggregation processing for intelligent prosthetic action recognition. Neural Computing and Applications. 2018;32(22):16795–16806. doi: 10.1007/s00521-018-3909-z. [DOI] [Google Scholar]
- 4.Shi G., Xu G., Wang H., Duan N., Zhang S. Fuzzy-adaptive impedance control of upper limb rehabilitation robot based on sEMG. Proceedings of International Conference on Ubiquitous Robots; June 2019; Jeju, Korea. pp. 745–749. [DOI] [Google Scholar]
- 5.Ma R., Zhang L., Li G., Jiang D., Xu S., Chen D. Grasping force prediction based on sEMG signals. Alexandria Engineering Journal. 2020;59(3):1135–1147. doi: 10.1016/j.aej.2020.01.007. [DOI] [Google Scholar]
- 6.Côté-Allard U., Gagnon-Turcotte G., Laviolette F., Gosselin B. A low-cost, wireless, 3-D-printed custom armband for sEMG hand gesture recognition. Sensors. 2019;19(12):p. 2811. doi: 10.3390/s19122811. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Yu Y., Chen X., Cao S., Zhang X., Chen X. Exploration of Chinese sign language recognition using wearable sensors based on deep belief net. IEEE Journal of Biomedical and Health Informatics. 2020;24(5):1310–1320. doi: 10.1109/jbhi.2019.2941535. [DOI] [PubMed] [Google Scholar]
- 8.Sun Y., Xu C., Li G., et al. Intelligent human computer interaction based on non redundant EMG signal. Alexandria Engineering Journal. 2020;59(3):1149–1157. doi: 10.1016/j.aej.2020.01.015. [DOI] [Google Scholar]
- 9.Amma C., Krings T., Böer J., Schultz T. Advancing muscle-computer interfaces with high-density electromyography. Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems; April 2015; Seoul, Republic of Korea. pp. 929–938. [DOI] [Google Scholar]
- 10.Geng W., Du Y., Jin W., Wei W., Hu Y., Li J. Gesture recognition by instantaneous surface EMG images. Scientific Reports. 2016;6(1):p. 36571. doi: 10.1038/srep36571. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Chen X., Li Y., Hu R., Zhang X., Chen X. Hand gesture recognition based on surface electromyography using convolutional neural network with transfer learning method. IEEE Journal of Biomedical and Health Informatics. 2020;24 doi: 10.1109/JBHI.2020.3009383. [DOI] [PubMed] [Google Scholar]
- 12.Khushaba R. N., Kodagoda S., Takruri M., Dissanayake G. Toward improved control of prosthetic fingers using surface electromyogram (EMG) signals. Expert Systems with Applications. 2012;39(12):10731–10738. doi: 10.1016/j.eswa.2012.02.192. [DOI] [Google Scholar]
- 13.Atzori M., Gijsberts A., Castellini C., et al. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Scientific Data. 2014;1 doi: 10.1038/sdata.2014.53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Bahador A., Yousefi M., Marashi M., Bahador O. High accurate lightweight deep learning method for gesture recognition based on surface electromyography. Computer Methods and Programs in Biomedicine. 2020;195 doi: 10.1016/j.cmpb.2020.105643.105643 [DOI] [PubMed] [Google Scholar]
- 15.Wei W., Wong Y., Du Y., Hu Y., Kankanhalli M., Geng W. A multi-stream convolutional neural network for sEMG-based gesture recognition in muscle-computer interface. Pattern Recognition Letters. 2019;119:131–138. doi: 10.1016/j.patrec.2017.12.005. [DOI] [Google Scholar]
- 16.Chen J., Sheng B., Zhang G., Cao G. High-density surface EMG-based gesture recognition using a 3D convolutional neural network. Sensors. 2020;20(4):p. 1201. doi: 10.3390/s20041201. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Phinyomark A., Scheme E. EMG pattern recognition in the era of big data and deep learning. Big Data and Cognitive Computing. 2018;2(3):p. 21. doi: 10.3390/bdcc2030021. [DOI] [Google Scholar]
- 18.Farina D., Merletti R. Comparison of algorithms for estimation of EMG variables during voluntary isometric contractions. Journal of Electromyography and Kinesiology. 2000;10(5):337–349. doi: 10.1016/s1050-6411(00)00025-0. [DOI] [PubMed] [Google Scholar]
- 19.Wu L., Zhang X., Wang K., Chen X., Chen X. Improved high-density myoelectric pattern recognition control against electrode shift using data augmentation and dilated convolutional neural network. IEEE Transactions on Neural Systems and Rehabilitation Engineering. 2020;28(12):2637–2646. doi: 10.1109/tnsre.2020.3030931. [DOI] [PubMed] [Google Scholar]
- 20.Tsinganos P., Cornelis B., Cornelis J., Jansen B., Skodras A. A Hilbert curve based representation of semg signals for gesture recognition. Proceedings of 2019 International Conference on Systems, Signals and Image Processing (IWSSIP); June 2019; Osijek, Croatia. pp. 201–206. [DOI] [Google Scholar]
- 21.Pan T. Y., Tsai W. L., Chang C. Y., Yeh C. W., Hu M. C. A hierarchical hand gesture recognition framework for sports referee training-based EMG and accelerometer sensors. IEEE Transactions on Cybernetics. 2020:1–12. doi: 10.1109/tcyb.2020.3007173. inpress. [DOI] [PubMed] [Google Scholar]
- 22.Du Y.-C., Lin C.-H., Shyu L.-Y., Chen T. Portable hand motion classifier for multi-channel surface electromyography recognition using grey relational analysis. Expert Systems with Applications. 2010;37(6):4283–4291. doi: 10.1016/j.eswa.2009.11.072. [DOI] [Google Scholar]
- 23.Phinyomark A., Phukpattaranont P., Limsakul C. Feature reduction and selection for EMG signal classification. Expert Systems with Applications. 2012;39(8):7420–7431. doi: 10.1016/j.eswa.2012.01.102. [DOI] [Google Scholar]
- 24.Duan F., Dai L., Chang W., Chen Z., Zhu C., Li W. sEMG-based identification of hand motion commands using wavelet neural network combined with discrete wavelet transform. IEEE Transactions on Industrial Electronics. 2016;63(3):1923–1934. doi: 10.1109/tie.2015.2497212. [DOI] [Google Scholar]
- 25.Zhai X., Jelfs B., Chan R. H. M., Tin C. Self-recalibrating surface EMG pattern recognition for neuroprosthesis control based on convolutional neural network. Frontiers in Neuroscience. 2017;11:p. 379. doi: 10.3389/fnins.2017.00379. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Hu Y., Wong Y., Wei W., et al. A novel attention-based hybrid CNN-RNN architecture for SEMG-based gesture recognition. PLoS One. 2018;13(10):1–18. doi: 10.1371/journal.pone.0206049.e0206049 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Betthauser J. L., Krall J. T., Bannowsky S. G., et al. Stable responsive EMG sequence prediction and adaptive reinforcement with temporal convolutional networks. IEEE Transactions on Biomedical Engineering. 2020;67(6):1707–1717. doi: 10.1109/tbme.2019.2943309. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Chen L., Fu J., Wu Y., Li H., Zheng B. Hand gesture recognition using compact CNN via surface electromyography signals. Sensors. 2020;20(3):p. 672. doi: 10.3390/s20030672. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Sun S. A survey of multi-view machine learning. Neural Computing and Applications. 2013;23(7):2031–2038. doi: 10.1007/s00521-013-1362-6. [DOI] [Google Scholar]
- 30.Zhao J., Xie X., Xu X., Sun S. Multi-view learning overview: recent progress and new challenges. Information Fusion. 2017;38:43–54. doi: 10.1016/j.inffus.2017.02.007. [DOI] [Google Scholar]
- 31.Wei W., Dai Q., Wong Y., Hu Y., Kankanhalli M., Geng W. Surface-electromyography-based gesture recognition by multi-view deep learning. IEEE Transactions on Biomedical Engineering. 2019;66(10):2964–2973. doi: 10.1109/tbme.2019.2899222. [DOI] [PubMed] [Google Scholar]
- 32.Wang D., Ouyang W., Li W., Xu D. Dividing and aggregating network for multi-view action recognition. Proceedings of the European Conference on Computer Vision (ECCV); September 2018; Munich, Germany. [DOI] [Google Scholar]
- 33.Shao Z., Li Y., Zhang H. Learning representations from skeletal self-similarities for cross-view action recognition. IEEE Transactions on Circuits and Systems for Video Technology. 2021;31(1):160–174. doi: 10.1109/tcsvt.2020.2965574. [DOI] [Google Scholar]
- 34.Kong Y., Ding Z., Li J., Fu Y. Deeply learned view-invariant features for cross-view action recognition. IEEE Transactions on Image Processing. 2017;26(6):3028–3037. doi: 10.1109/tip.2017.2696786. [DOI] [PubMed] [Google Scholar]
- 35.Atzori M., Gijsberts A., Heynen S., et al. Building the Ninapro database: a resource for the biorobotics community. Proceedings of the IEEE RAS EMBS International Conference on Biomedical Robotics and Biomechatronics; February 2012; Pisa, Italy. pp. 1258–1265. [DOI] [Google Scholar]
- 36.Padhy S. A tensor-based approach using multilinear SVD for hand gesture recognition from SEMG signals. IEEE Sensors Journal. 2020;21 doi: 10.1109/JSEN.2020.3042540. [DOI] [Google Scholar]
- 37.Pizzolato S., Tagliapietra L., Cognolato M., et al. Comparison of six electromyography acquisition setups on hand movement classification tasks. PLoS One. 2017;12(10):1–17. doi: 10.1371/journal.pone.0186132.e0186132 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Xu C., Tao D., Xu C. A survey on multi-view learning. 2013. http://arxiv.org/abs/1304.5634.
- 39.Jiang W., Yin Z. Human activity recognition using wearable sensors by deep convolutional neural networks. Proceedings of the 23rd ACM International Conference on Multimedia; October 2015; Brisbane Australia. pp. 1307–1310. [DOI] [Google Scholar]
- 40.Hudgins B., Parker P., Scott R. N. A new strategy for multifunction myoelectric control. IEEE Transactions on Biomedical Engineering. 1993;40(1):82–94. doi: 10.1109/10.204774. [DOI] [PubMed] [Google Scholar]
- 41.Englehart K., Hudgins B. A robust, real-time control scheme for multifunction myoelectric control. IEEE Transactions on Biomedical Engineering. 2003;50(7):848–854. doi: 10.1109/tbme.2003.813539. [DOI] [PubMed] [Google Scholar]
- 42.Du Y., Jin W., Wei W., Hu Y., Geng W. Surface EMG-based inter-session gesture recognition enhanced by deep domain adaptation. Sensors. 2017;17(3):p. 458. doi: 10.3390/s17030458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Su H., Maji S., Kalogerakis E., Learned-Miller E. Multi-view convolutional neural networks for 3D shape recognition. Proceedings of IEEE International Conference on Computer Vision; December 2015; Santiago, Chile. pp. 945–953. [DOI] [Google Scholar]
- 44.He T., Mao H., Yi Z. Moving object recognition using multi-view three-dimensional convolutional neural networks. Neural Computing and Applications. 2017;28(12):3827–3835. doi: 10.1007/s00521-016-2277-9. [DOI] [Google Scholar]
- 45.Shin S., Tafreshi R., Langari R. Robustness of using dynamic motions and template matching to the limb position effect in myoelectric classification. Journal of Dynamic Systems, Measurement, and Control. 2016;138(11) doi: 10.1115/1.4033835. [DOI] [Google Scholar]
- 46.Phinyomark A., Campbell E., Scheme E. Biomedical Signal Processing. Berlin, Germany: Springer; 2020. Surface electromyography (EMG) signal processing, classification, and practical considerations; pp. 3–29. [DOI] [Google Scholar]
- 47.Zhang L. Transfer adaptation learning: a decade survey. 2019. http://arxiv.org/abs/1903.04687. [DOI] [PubMed]
- 48.Côté-Allard U., Fall C. L., Campeau-Lecours A., et al. Transfer learning for SEMG hand gestures recognition using convolutional neural networks. IEEE International Conference on Systems, Man, and Cybernetics (SMC); October 2017; Banff, Canada. pp. 1663–1668. [DOI] [Google Scholar]
- 49.Cheng Y., Li G., Yu M., et al. Gesture recognition based on surface electromyography-feature image. Concurrency and Computation: Practice and Experience. 2021;33(6) doi: 10.1002/cpe.6051.e6051 [DOI] [Google Scholar]
- 50.Shen S., Gu K., Chen X.-R., Yang M., Wang R.-C. Movements classification of multi-channel sEMG based on CNN and stacking ensemble learning. IEEE Access. 2019;7:137489–137500. doi: 10.1109/access.2019.2941977. [DOI] [Google Scholar]
- 51.Fajardo J., Ferman V., Cardona D., Maldonado G., Lemus A., Rohmer E. Galileo hand: an anthropomorphic and affordable upper-limb prosthesis. IEEE Access. 2020;8:81365–81377. doi: 10.1109/access.2020.2990881. [DOI] [Google Scholar]
- 52.Prakash A., Sharma S. A low-cost transradial prosthesis controlled by the intention of muscular contraction. Physical and Engineering Sciences in Medicine. 2021;44(1):229–241. doi: 10.1007/s13246-021-00972-w. [DOI] [PubMed] [Google Scholar]
- 53.Zhang X., Liu J., Gao Q., Ju Z. Adaptive robust decoupling control of multi-arm space robots using time-delay estimation technique. Nonlinear Dynamics. 2020;100(3):2449–2467. doi: 10.1007/s11071-020-05615-5. [DOI] [Google Scholar]
- 54.Zhang X., Liu J., Feng J., Liu Y., Ju Z. Effective capture of nongraspable objects for space robots using geometric cage pairs. IEEE/ASME Transactions on Mechatronics. 2020;25(1):95–107. doi: 10.1109/tmech.2019.2952552. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The multichannel sEMG data supporting the findings of this study are from the NinaPro dataset, which is publicly available at http://ninapro.hevs.ch. Papers describing the NinaPro dataset are cited at relevant places within the text as references [13, 37]. The processed data and trained deep learning models used to support the findings of this study are available from the corresponding author upon request.