

Abstract
PURPOSE
Pancreatic cancer is an aggressive malignancy with patients often experiencing nonspecific symptoms before diagnosis. This study evaluates a machine learning approach to help identify patients with early-stage pancreatic cancer from clinical data within electronic health records (EHRs).
MATERIALS AND METHODS
From the Optum deidentified EHR data set, we identified early-stage (n = 3,322) and late-stage (n = 25,908) pancreatic cancer cases over 40 years of age diagnosed between 2009 and 2017. Patients with early-stage pancreatic cancer were matched to noncancer controls (1:16 match). We constructed a prediction model using eXtreme Gradient Boosting (XGBoost) to identify early-stage patients on the basis of 18,220 features within the EHR including diagnoses, procedures, information within clinical notes, and medications. Model accuracy was assessed with sensitivity, specificity, positive predictive value, and the area under the curve.
RESULTS
The final predictive model included 582 predictive features from the EHR, including 248 (42.5%) physician note elements, 146 (25.0%) procedure codes, 91 (15.6%) diagnosis codes, 89 (15.3%) medications, and 9 (1.5%) demographic features. The final model area under the curve was 0.84. Choosing a model cut point with a sensitivity of 60% and specificity of 90% would enable early detection of 58% late-stage patients with a median of 24 months before their actual diagnosis.
CONCLUSION
Prediction models using EHR data show promise in the early detection of pancreatic cancer. Although widespread use of this approach on an unselected population would produce high rates of false-positive tests, this technique may be rapidly impactful if deployed among high-risk patients or paired with other imaging or biomarker screening tools.
INTRODUCTION
In the United States, pancreatic cancer represents the 10th most common cancer diagnosis yet is the third most common cause of cancer-related death,1 with an estimated 47,000 dying from this deadly disease in the United States in 2020.2 Surgery for pancreatic cancer represents a patient's only chance for cure, but only a small fraction of patients will present with potentially operable disease.3 Unfortunately, many patients present with vague, nonspecific symptoms, which is a diagnostic challenge that results in delayed diagnosis. Identifying patients earlier in their disease course would allow an increased number of patients with pancreatic cancer to undergo curative intent surgery and could markedly improve cure rates.
CONTEXT
Key Objective
This study created a machine learning within a large electronic health record data set to detect signatures of patients with pancreatic cancer earlier in their disease course at a stage of disease potentially amenable to curative surgery.
Knowledge Generated
This approach identified 582 predictive features from the electronic health record including components documented in physician notes, procedures, diagnoses, medications, and demographic factors. The model had favorable performance characteristics overall although the low incidence of pancreatic cancer in an unselected patient population led to a high number of false-positive tests.
Relevance
This machine learning algorithm demonstrates potential benefits with respect to early identification of pancreatic cancer, yet to implement this approach successfully in the future would require targeting a high-risk patient population or pairing with other complimentary screening approaches.
Despite the strong incentive for early detection of pancreatic cancer, we currently lack an effective approach to population-wide screening.4 Pancreatic cancer has a lower incidence compared with other more common cancers such as breast, prostate, and colorectal cancers. The relative infrequency of pancreatic cancer leads to practical challenges with screening in that even among screening tests with high specificity, the majority of positive screening tests would represent false-positive tests in patients without pancreatic cancer as opposed to true-positive tests in patients with pancreatic cancer. To help circumvent this limitation, one could consider using an easily implementable screening strategy to identify patients at risk of pancreatic cancer who could potentially benefit from additional screening studies. A two-step approach, using complimentary screening approaches, could overcome some of the practical limitations inherent with pancreatic cancer screening.
Most screening options for pancreatic cancer screening involve either imaging or biomarker-based approaches.5 The current study evaluates an alternative clinical data-driven approach to pancreatic cancer screening on the basis of existing electronic health record (EHR) data. Given the ubiquitous nature of EHR data, the concept of screening for diseases within an EHR system has the potential for widespread cost-effective implementation. Furthermore, with pancreatic cancer, EHR-based screening could potentially identify high-risk patients who stand to benefit from additional screening with conventional or novel early detection approaches. The application of machine learning algorithms to EHR data demonstrates promise in different clinical applications, yet has not been thoroughly studied in pancreatic cancer.6-8 In this study, we applied a machine learning technique to EHR data to generate a prediction model to help identify patients at risk for pancreatic cancer. We then applied this predictive model to a group of patients diagnosed with late-stage pancreatic cancer (LSPC) to determine how much earlier they could be detected with this predictive model.
MATERIALS AND METHODS
Data Source
This study evaluated patients from within the Optum deidentified EHR data set between 2008 and 2017 (Data Supplement).9,10 To minimize missing data, we restricted patients to those who received care through integrated delivery networks (IDN).11
Pancreatic Cancer Cases and Noncancer Controls
We initially identified 50,707 patients with pancreatic cancer with the presence of two or more International Classification of Diseases, Ninth or Tenth Revision, codes in a single calendar year.12-16 Patients with pancreatic cancer were further divided into those with early-stage pancreatic cancer (ESPC) or LSPC. Patients were assumed to have ESPC if they underwent major pancreatic surgery including a pancreaticoduodenectomy, distal pancreatectomy, or total pancreatectomy.17 The remaining patients with pancreatic cancer were assumed to have LSPC. We excluded the small fraction of patients under 40 years of age at diagnosis (n = 899), those who did not receive care through IDN (n = 7,048), and those without a clinical encounter in the year before pancreatic cancer diagnosis (n = 13,530). After these exclusions, the analytic case cohort included a total of 3,322 patients with ESPC and 25,908 patients with LSPC. Patients were eligible as controls if they had no history of pancreatic cancer, were ≥ 40 years at diagnosis, received care through IDN, and had at least three individual yearly healthcare encounters within the EHR. This approach identified 7,039,056 potential control patients. The Data Supplement demonstrates patient characteristics of excluded and included patients with pancreatic cancer.
Predictive Model to Identify Pancreatic Cancer
For each ESPC case, we matched 16 controls on the basis of geographic region and enrollment period within Optum. We did not match by patient age, sex, or other demographic variables given that these could represent risk factors for pancreatic cancer. Table 1 demonstrates patient characteristics of our matched cohort. We split the ESPC case-control cohort into 70% training and 30% test sets stratified by dependent variables.18-20 We defined the predictive model on the training set and assessed its overall performance on the test set.
TABLE 1.
Patient Characteristics
The model considered features found in patients’ EHRs during a 1-year time window extending from 13 months through 1 month before cancer diagnosis. We included a wide array of potential variables into our predictive model (Data Supplement). To avoid incorporating aspects of care along the diagnostic pathway for pancreatic cancer, we removed variables involved with pancreatic cancer diagnosis, staging, treatment, and monitoring. Initially, we identified 18,220 variables generated from EHR data. After variables reduction (detailed in the Data Supplement), 1,947 potential variables were considered in our predictive model.21-23
To construct the prediction model, we used the XGBoost machine learning framework, an optimized gradient boosting ensemble model well suited for handling large data with sparse features.24 Parameters were tuned via grid search along with 5-fold cross-validation using area under the curve (AUC) score as a performance metric, with L1-based regularization applied to reduce overfitting. The importance of individual model variables was estimated by the total gain (Data Supplement).25,26 Additional details of the algorithm used are provided in the Data Supplement. Scikit-learn’s inbuilt reliability curves are provided in the Data Supplement.
Analysis
With our final predictive model, we calculated the sensitivity, specificity, and AUC. An AUC of 1.0 indicates a perfect prediction, and an AUC of 0.5 indicates random chance. 95% CIs were calculated by the 1,000-iteration based Bootstrapping method. To estimate the positive predictive value (PPV) in detecting incident pancreatic cancer cases, we used the following formula: (sensitivity × incidence)/(sensitivity × incidence + (1 − specificity) × (1 − incidence). We estimated age-adjusted incidence for pancreatic cancer from the SEER database and assumed a population age-distribution representative of the 2000 US Standard Population.2,27,28
We applied our algorithm to the cohort of patients with LSPC described above. Among this cohort, we determined the fraction of patients and time (in months) the algorithm could predict a patient would develop cancer before their date of diagnosis.
Sensitivity analyses were performed and presented in the Data Supplement. All analyses were conducted using SAS version 9.4 and Python version 3.6.5.
RESULTS
The final model included 582 variables (Data Supplement), and Fig 1 shows the 30 most important variables selected by the algorithm using the total gain method. Together, these variables accounted for > 68% of the overall total gain. A record of pancreatic disorders (noncancerous and not relating to diabetes mellitus) was found to be the most important model feature, followed by age, income, biliary tract disease, education level, obstructive jaundice, and abdominal pain. Of all the variables, 248 (42.5%) were considered physician note elements, 146 (25.0%) were procedure codes, 91 (15.6%) were diagnosis codes, 89 (15.3%) were medications, and 9 (1.5%) were demographic features.
FIG 1.

Most important features in the predictive algorithm. This figure represents the 30 model features with the highest total gain in the predictive algorithm. Total gain represents the contribution of each variable to the model’s predictive ability. Higher gain values indicate that the variable is more important in generating a prediction. Pancreatic disorders (not diabetes) is a Clinical Classification Software (CCS) category inclusive of ICD-9-CM and ICD-10-CM codes for acute and chronic pancreatitis and pancreatic cysts and pseudocysts.
Overall, when evaluating the model performance on the final test data set, the AUC of the predictive model was 0.84 (95% CI, 0.83 to 0.85) (Fig 2). Model performance tradeoffs with different test thresholds in terms of sensitivity, specificity, and PPV are demonstrated in Table 2. Choosing a test threshold with a lower sensitivity would reduce the number of true-positive patients identified although it would also increase the specificity and PPV. Of note, PPV depended on patient age, which reflects the increasing incidence of pancreatic cancer among older populations (Figs 3A and 3B). For example, if we choose a test threshold with a sensitivity of 20%, the specificity was 99.9%. At this cutoff, the PPV for patients age ≥ 40 years was 2.5% although the PPV for patients age ≥ 80 years was 8.0%, which means that 8.0% of cases classified positive by the algorithm were truly positive among patients age 80 years or above.
FIG 2.

Receiver operating characteristic curve. The solid blue line represents the relationship between model sensitivity versus specificity. AUC, area under the curve.
TABLE 2.
Summary of Predictive Test Characteristics

FIG 3.
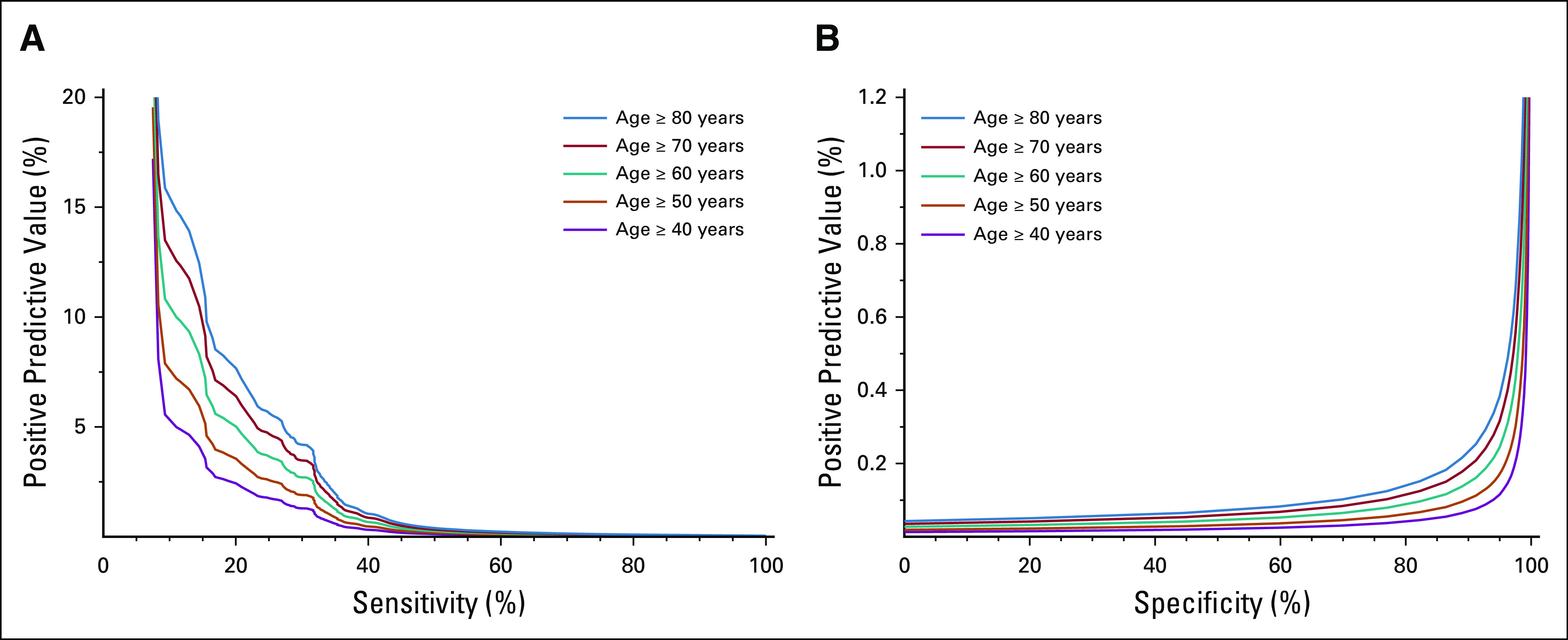
PPV. These plots demonstrate the PPV according to (A) model sensitivity and (B) specificity. The PPV depends on the ages of patients screened, with the different color lines representing different age groups. PPV, positive predictive value.
We applied the predictive algorithm to the cohort of 25,908 patients with LSPC. The fraction of patients with LSPC detected at least 1 month before their diagnosis depended on the algorithm sensitivity threshold (Fig 4A and Table 2), with lower sensitivity levels leading to a decreased proportion of LSPC detected. Among those patients with LSPC who were identified earlier by the algorithm, the distribution of time they could be detected earlier depended on model sensitivity (Fig 4B). Choosing a predictive model cut point with higher sensitivity levels led to progressively earlier diagnoses among the patients with LSPC. Table 2 demonstrates the tradeoffs associated with different cut points in terms of the model’s ability to identify patients with LSPC. For example, a model cut point with a sensitivity of 20% would detect patients with LSPC with a median of 4.3 months earlier than their actual diagnosis, whereas choosing a cut point with a sensitivity of 80% would detect patients with LSPC with a median of 34 months earlier than their actual diagnosis.
FIG 4.
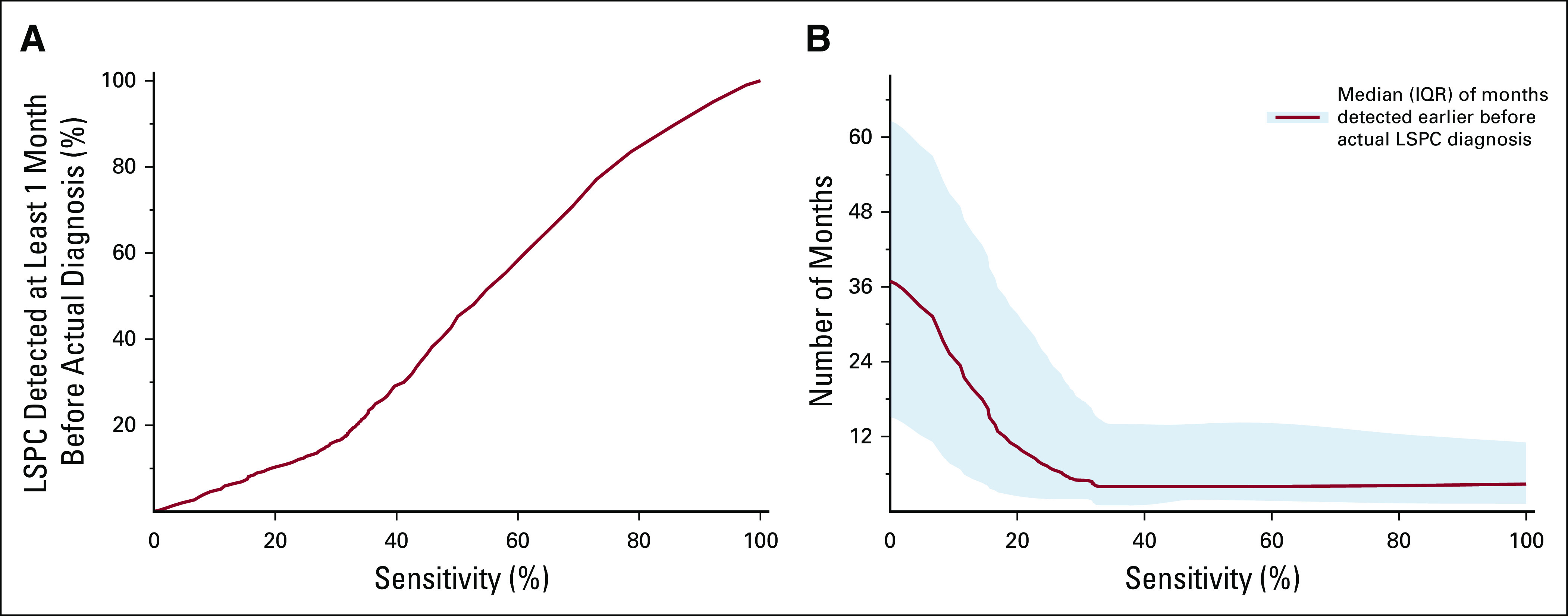
Model prediction among patients with LSPC. (A) The correlation between the fraction of patients with LSPC detected and model sensitivity. (B) The correlation between the number of months that late-stage patients were detected earlier than their diagnosis, with the solid red line representing the median value and the shaded region representing the IQR. IQR, interquartile range; LSPC, late-stage pancreatic cancer.
We conducted secondary analyses to assess the stability of our model under different conditions. There was no significant change in AUC with different case-control ratios. The AUC of the base model was 0.84, whereas the AUCs for case-control ratios of 1:8 and 1:32 were also 0.84. Our base predictive model incorporated EHR data in a window extending up to 1 month before diagnosis, and we found that expanding this 1-month gap decreased the AUC slightly. Increasing the gap to 2 months produced an AUC of 0.80, and increasing the gap to 3 months produced an AUC of 0.79. When evaluating the limited case-control cohort with laboratory values, the AUC increased marginally from 0.87 (building a model with no laboratory values) to 0.88 (building a model with laboratory values). This suggests that incorporating laboratory values did not substantially improve the predictive capacity of the model.
The predictive model performed well when focusing on subsets of patients divided by sex, age, and race, with an AUC above 0.81 in all subsets (Data Supplement). The model performance of our base model (AUC, 0.84) outperformed simpler risk prediction models with three features (AUC, 0.75), five features (AUC, 0.77), and 10 features (AUC, 0.79). Finally, the risk prediction model with known pancreatic cancer risk factors, which demonstrated inferior performance (AUC, 0.71), was compared with our base model (AUC, 0.84).
DISCUSSION
Despite the aggressive nature of pancreatic cancer, we lack an accepted approach to screening.29 Existing screening approaches often involve imaging modalities including abdominal computed tomography, endoscopic ultrasound, or magnetic resonance imaging. These imaging tools play a central role in pancreatic cancer diagnosis, yet they have variable sensitivity and specificity when used in screening.30-33 Additionally, computed tomography imaging exposes patients to radiation, and endoscopy represents an invasive procedure that, although generally well-tolerated, has a small complication rate.34 Also, any imaging tests can lead to false-positive benign or incidental finding, which could lead to additional tests that carry risks of complications. In 2019, the US Preventive Services Task Force (USPSTF) assessed the utility of imaging for pancreatic cancer screening4 and found that the potential benefits of screening for pancreatic cancer in asymptomatic adults do not outweigh the potential harms. This USPSTF recommendation arose from a review of 13 prospective cohort studies of imaging to detect pancreatic cancer in individuals with elevated familial or genetic risk for pancreatic cancer. Despite the recommendations against global screening, with the high mortality rate associated with a late diagnosis of pancreatic cancer, researchers continue to study different screening approaches in an attempt to bend the mortality curve of this challenging disease.
This current project evaluates the potential for using data within an EHR to identify individuals at risk of pancreatic cancer. Applying this algorithm to late-stage patients enabled early identification of a substantial portion of patients. For example, depending on the predictive model threshold used, the algorithm could potentially identify 58% of late-stage patients with a median of 24 months earlier than their actual diagnosis. Despite the intuitive attraction to earlier diagnosis with pancreatic cancer, one must consider that data supporting the overall clinical benefit of early diagnosis are limited. A recent retrospective study among 354 high-risk patients found that patients with screen-detected pancreatic cancer had improved survival compared with patients who did not adhere to recommended screening.35 However, with retrospective research, one must consider the issue of lead-time bias, which can lead to artificially improved survival estimates among earlier screen-detected cancers. Additionally, length-time bias could inflate survival estimates of screen-detected cancers if screening identifies more indolent or slower progressing cancers. Given the morbidity and nontrivial mortality associated with pancreatic cancer treatment, one must consider these issues when evaluating any screening approach. However, data clearly demonstrate significantly improved survival associated with resection of smaller localized pancreatic tumors.36 Overall, earlier detection of pancreatic cancer has clear potential to substantially improve cure rates.
Our modeling approach relied on a diverse set of features within an EHR to construct a predictive algorithm. Our full model with 582 variables modestly outperformed simpler models with three, five, and 10 variables, although notably our full model substantially outperformed a model with classic pancreatic risk factors. Although prior researchers have not used our specific modeling approach, other research teams have incorporated clinical factors to generate risk prediction models. Zhao and Weng37 created a weighted Bayesian network model on EHR data among 98 patients with pancreatic cancer incorporating 20 risk factors. Zhao and Weng found an AUC of 0.91, which is higher than our AUC of 0.84, although they used a different analytic approach including a manual chart review to extract model features for the cases. Manual chart review poses a potential limitation with respect to feasibility with real-world implementation. In another study, Muhammad et al38 created an artificial neural network to identify pancreatic cancer among 898 patients diagnosed with pancreatic cancer using publicly available health survey data and found an AUC of 0.85. Other avenues of research into pancreatic cancer screening have evaluated a variety of different approaches, including studies searching for potential biomarkers in saliva, urine, or blood.39-42 For example, a recently reported multianalyte blood test combining polymerase chain reaction and an immunoassay can achieve a sensitivity of 69% and a specificity of 99%. Additionally, circulating tumor DNA–based screening tests hold promise, with large ongoing trials assessing the potential role within cancer screening.43,44 Coupling a broad-based clinical screening tool with a secondary biomarker-oriented screening tool represents a potential strategy to increase the efficiency of population-based screening.45
One important consideration with any cancer screening modality relates to potential issues surrounding real-world implementation. Our approach relies on data extractable from EHRs, which represents an implementable strategy given the ubiquity of EHR data.46 In theory, one could widely deploy an EHR-based screening tool across a healthcare network with integration into an EHR platform. However, with any population-wide screening tool involving a disease with low prevalence, one must consider the impact of false-positive screening tests. Even with a screening tool with a specificity of 99%, implementing this screening tool on a population of 10,000 patients would lead to 100 false-positive tests among patients without cancer. Real-world implementation of this screening strategy could only be undertaken after careful consideration of the cost of unnecessary workup in these false-positive patients. One must also consider potential psychosocial concerns related to patients who undergo screening. Studies evaluating cancer screening in patients with familial or genetic risk factors for pancreatic cancer show that this subset of patients experience relatively low psychosocial burden from screening.47,48 However, the psychosocial impact of screening an average-risk population represents a distinctly different scenario compared with screening a high-risk population. Ultimately, research into both effectiveness and implementation is essential to help understand the overall utility of any screening tool.
This study design has limitations worth mentioning. First, this study used EHR data to identify pancreatic cancer cases, and we do not have access to gold standard pathology reports confirming tissue diagnosis. Although this approach leads to the possibility of misclassification of cancer cases, other research demonstrates high levels of accuracy using ICD codes to identify pancreatic cancer from EHR data.49 Similarly, we lack information on stage of diagnosis, and although a major operation on the pancreas would likely occur in early-stage patients, we accept that some early-stage or late-stage patients could be misclassified. The larger sample size of our data set represents a benefit with respect to model construction although future independent model validation in EHR data linked to cancer registry data could help overcome some of these limitations with respect to identification and classification of cancer cases. With this analysis, we excluded subsets of patients in constructing our study cohort. Although our model performed well in subsets of patients stratified by age, sex, and race, the excluded patients could potentially introduce bias into this analysis. Because of missing data, our model also lacks smoking status and weight, both of which are known risk factors for pancreatic cancer. A model that included these features would likely perform better. We have noted that baseline laboratory values, absent for many patients, were excluded from the model with little cost to model performance. However, given the nature of the data used in this analysis, we accept that other clinical data elements might be missing or incomplete in our analysis, which we suspect would degrade model accuracy. Finally, this model used one specific machine learning approach to build a predictive model. Other machine learning algorithms, or other artificial intelligence approaches, could potentially produce predictive models with improved accuracy. Future research to optimize the analytic approach would help enhance model accuracy.
Overall, our prediction model reflects a unique strategy to potentially identify patients with pancreatic cancer at earlier time points in their disease course. Additional validation in external data sets will help further define the overall generalizability of this approach. Future research assessing clinical efficacy and research evaluating implementation approaches will help define the ultimate utility of EHR-based screening in pancreatic cancer.
SUPPORT
Supported by NIH TL1 TR001443 (D.R.C. and A.K.).
Q.C. and D.R.C. contributed equally to this work.
AUTHOR CONTRIBUTIONS
Conception and design: Qinyu Chen, Daniel R. Cherry, Vinit Nalawade, James D. Murphy
Administrative support: Andrew M. Lowy, James D. Murphy
Provision of study materials or patients: Andrew M. Lowy
Collection and assembly of data: Qinyu Chen, Daniel R. Cherry, Vinit Nalawade, Abhishek Kumar, James D. Murphy
Data analysis and interpretation: Qinyu Chen, Vinit Nalawade, Edmund M. Qiao, Abhishek Kumar, Andrew M. Lowy, Daniel R. Simpson, James D. Murphy
Manuscript writing: All authors
Final approval of manuscript: All authors
Accountable for all aspects of the work: All authors
AUTHORS' DISCLOSURES OF POTENTIAL CONFLICTS OF INTEREST
The following represents disclosure information provided by authors of this manuscript. All relationships are considered compensated unless otherwise noted. Relationships are self-held unless noted. I = Immediate Family Member, Inst = My Institution. Relationships may not relate to the subject matter of this manuscript. For more information about ASCO's conflict of interest policy, please refer to www.asco.org/rwc or ascopubs.org/cci/author-center.
Open Payments is a public database containing information reported by companies about payments made to US-licensed physicians (Open Payments).
Abhishek Kumar
Stock and Other Ownership Interests: Sympto Health
Andrew M. Lowy
Consulting or Advisory Role: Halozyme, Merck, Pfizer, HUYA Bioscience International, Fount Therapeutics, Rafael Pharmaceuticals
Research Funding: Mitsubishi Tanabe Pharma, Syros Pharmaceuticals
Expert Testimony: Merck
Travel, Accommodations, Expenses: Pfizer
James D. Murphy
Consulting or Advisory Role: Boston Consulting Group
Research Funding: eContour
No other potential conflicts of interest were reported.
REFERENCES
- 1.Siegel RL, Miller KD, Jemal A.Cancer statistics, 2019 CA Cancer J Clin 697–342019 [DOI] [PubMed] [Google Scholar]
- 2.NIH . Cancer Stat Facts: Pancreatic Cancer. https://seer.cancer.gov/statfacts/html/pancreas.html [Google Scholar]
- 3.Truty MJ, Kendrick ML, Nagorney DM, et al. Factors predicting response, perioperative outcomes, and survival following total neoadjuvant therapy for borderline/locally advanced pancreatic cancer Ann Surg 273341–3492019 [DOI] [PubMed] [Google Scholar]
- 4.Henrikson NB, Aiello Bowles EJ, Blasi PR, et al. Screening for pancreatic cancer: Updated evidence report and systematic review for the US Preventive Services Task Force JAMA 322445–4542019 [DOI] [PubMed] [Google Scholar]
- 5.Singhi AD, Koay EJ, Chari ST, et al. Early detection of pancreatic cancer: Opportunities and challenges Gastroenterology 1562024–20402019 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Battineni G, Sagaro GG, Chinatalapudi N, et al. Applications of machine learning predictive models in the chronic disease diagnosis. J Pers Med. 2020;10:21. doi: 10.3390/jpm10020021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Davenport T, Kalakota R.The potential for artificial intelligence in healthcare Future Healthc J 694–982019 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Ahmed Z, Mohamed K, Zeeshan S, et al. Artificial intelligence with multi-functional machine learning platform development for better healthcare and precision medicine. Database (Oxford) 2020;2020:baaa010. doi: 10.1093/database/baaa010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Wallace PJ, Shah ND, Dennen T, et al. Optum labs: Building a novel node in the learning health care system Health Aff (Millwood) 331187–11942014 [DOI] [PubMed] [Google Scholar]
- 10.Optum Labs . Using Clinical Notes to Improve Health Care. https://www.optum.com/resources/library/notes-improve-care.html [Google Scholar]
- 11.Al-Saddique A. Integrated delivery systems (IDSs) as a means of reducing costs and improving healthcare delivery. J Healthc Commun. 2018;3:19. [Google Scholar]
- 12.Hess LM, Zhu YE, Sugihara T, et al. Challenges of using ICD-9-CM and ICD-10-CM codes for soft-tissue sarcoma in databases for health Services research. Perspect Health Inf Manag. 2019;16:1a. [PMC free article] [PubMed] [Google Scholar]
- 13.Goldberg DS, Lewis JD, Halpern SD, et al. Validation of a coding algorithm to identify patients with hepatocellular carcinoma in an administrative database Pharmacoepidemiol Drug Saf 22103–1072013 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Goldberg D, Lewis J, Halpern S, et al. Validation of three coding algorithms to identify patients with end-stage liver disease in an administrative database Pharmacoepidemiol Drug Saf 21765–7692012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Eichler AF, Lamont EB.Utility of administrative claims data for the study of brain metastases: A validation study J Neurooncol 95427–4312009 [DOI] [PubMed] [Google Scholar]
- 16.Boyd CA, Branch DW, Sheffield KM, et al. Hospital and medical care days in pancreatic cancer Ann Surg Oncol 192435–24422012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Tempero MA, Malafa MP, Behrman SW, et al. Pancreatic adenocarcinoma, version 2.2014: Featured updates to the NCCN guidelines J Natl Compr Canc Netw 121083–10932014 [DOI] [PubMed] [Google Scholar]
- 18.Pan L, Liu G, Lin F, et al. Machine learning applications for prediction of relapse in childhood acute lymphoblastic leukemia. Sci Rep. 2017;7:7402. doi: 10.1038/s41598-017-07408-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Goto T, Jo T, Matsui H, et al. Machine learning-based prediction models for 30-day readmission after hospitalization for chronic obstructive pulmonary disease COPD 16338–3432019 [DOI] [PubMed] [Google Scholar]
- 20.Vanneschi L, Farinaccio A, Mauri G, et al. A comparison of machine learning techniques for survival prediction in breast cancer. BioData Min. 2011;4:12. doi: 10.1186/1756-0381-4-12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Biau DJ, Kernéis S, Porcher R.Statistics in brief: The importance of sample size in the planning and interpretation of medical research Clin Orthop Relat Res 4662282–22882008 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Tanha K, Mohammadi N, Janani L. P-value: What is and what is not. Med J Islamic Rep Iran. 2017;31:65. doi: 10.14196/mjiri.31.65. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Britto Figueiredo Filho D, Paranhos R, da Rocha EC, et al. When is statistical significance not significant? Brazil Pol Sci Rev 731–552013 [Google Scholar]
- 24.Chen T, Carlos G.XGBoost: A scalable tree boosting system KDD 2016785–7942016 [Google Scholar]
- 25.Package XP . Python API Reference. https://xgboost.readthedocs.io/en/latest/python/python_api.html [Google Scholar]
- 26.Huiting Z, Jiabin Y, Long C. Short-term load forecasting using EMD-LSTM neural networks with a Xgboost algorithm for feature importance evaluation. Energies. 2017;10:1168. [Google Scholar]
- 27.Institute NC . Age-Specific SEER Incidence Rates, 2012-2016. https://seer.cancer.gov/csr/1975_2016/browse_csr.php?sectionSEL=22&pageSEL=sect_22_table.07 [Google Scholar]
- 28.NIH . Standard Populations—19 Age Groups. https://seer.cancer.gov/stdpopulations/stdpop.19ages.html [Google Scholar]
- 29.Owens DK, Davidson KW, Krist AH, et al. Screening for pancreatic cancer: US Preventive Services Task Force reaffirmation recommendation statement JAMA 322438–4442019 [DOI] [PubMed] [Google Scholar]
- 30.Shrikhande SV, Barreto SG, Goel M, et al. Multimodality imaging of pancreatic ductal adenocarcinoma: A review of the literature HPB (Oxford) 14658–6682012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Costache MI, Costache CA, Dumitrescu CI, et al. Which is the best imaging method in pancreatic adenocarcinoma diagnosis and staging—CT, MRI or EUS? Curr Health Sci J 43132–1362017 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Zhang L, Sanagapalli S, Stoita A.Challenges in diagnosis of pancreatic cancer World J Gastroenterol 242047–20602018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.McAllister F, Montiel MF, Uberoi GS, et al. Current status and future directions for screening patients at high risk for pancreatic cancer Gastroenterol Hepatol (N Y) 13268–2752017 [PMC free article] [PubMed] [Google Scholar]
- 34.Ben-Menachem T, Decker GA, Early DS, et al. Adverse events of upper GI endoscopy Gastrointest Endosc 76707–7182012 [DOI] [PubMed] [Google Scholar]
- 35.Canto MI, Almario JA, Schulick RD, et al. Risk of neoplastic progression in individuals at high risk for pancreatic cancer undergoing long-term surveillance Gastroenterology 155740–7512018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Katz MH, Hu CY, Fleming JB, et al. Clinical calculator of conditional survival estimates for resected and unresected survivors of pancreatic cancer Arch Surg 147513–5192012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Zhao D, Weng C.Combining PubMed knowledge and EHR data to develop a weighted bayesian network for pancreatic cancer prediction J Biomed Inform 44859–8682011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Muhammad W, Hart GR, Nartowt B, et al. Pancreatic cancer prediction through an artificial neural network. Front Artif Intell. 2019;2:2. doi: 10.3389/frai.2019.00002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Bratulic S, Gatto F, Nielsen J. The translational status of cancer liquid biopsies. Regen Eng Transl Med. 2019 [Google Scholar]
- 40.Zhang X, Shi S, Zhang B, et al. Circulating biomarkers for early diagnosis of pancreatic cancer: Facts and hopes Am J Cancer Res 8332–3532018 [PMC free article] [PubMed] [Google Scholar]
- 41.Zhou B, Xu JW, Cheng YG, et al. Early detection of pancreatic cancer: Where are we now and where are we going? Int J Cancer 141231–2412017 [DOI] [PubMed] [Google Scholar]
- 42.Kunovsky L, Tesarikova P, Kala Z, et al. The use of biomarkers in early diagnostics of pancreatic cancer. Can J Gastroenterol Hepatol. 2018;2018:5389820. doi: 10.1155/2018/5389820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Aravanis AM, Lee M, Klausner RD.Next-generation sequencing of circulating tumor DNA for early cancer detection Cell 168571–5742017 [DOI] [PubMed] [Google Scholar]
- 44.The Circulating Cell-free Genome Atlas Study. https://ClinicalTrials.gov/show/NCT02889978 [Google Scholar]
- 45.Kim J, Yuan C, Babic A, et al. Genetic and circulating biomarker data improve risk prediction for pancreatic cancer in the general population Cancer Epidemiol Biomarkers Prev 29999–10082020 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.KFF Health Tracking Poll—January 2019: The Public on Next Steps for the ACA and Proposals to Expand Coverage. Oakland, CA: Kaiser Family Foundation; [Google Scholar]
- 47.Konings IC, Sidharta GN, Harinck F, et al. Repeated participation in pancreatic cancer surveillance by high-risk individuals imposes low psychological burden Psychooncology 25971–9782016 [DOI] [PubMed] [Google Scholar]
- 48.Maheu C, Vodermaier A, Rothenmund H, et al. Pancreatic cancer risk counselling and screening: Impact on perceived risk and psychological functioning Fam Cancer 9617–6242010 [DOI] [PubMed] [Google Scholar]
- 49.Hwang YJ, Park SM, Ahn S, et al. Accuracy of an administrative database for pancreatic cancer by international classification of disease 10th codes: A retrospective large-cohort study World J Gastroenterol 255619–56292019 [DOI] [PMC free article] [PubMed] [Google Scholar]