
Fig. 7.
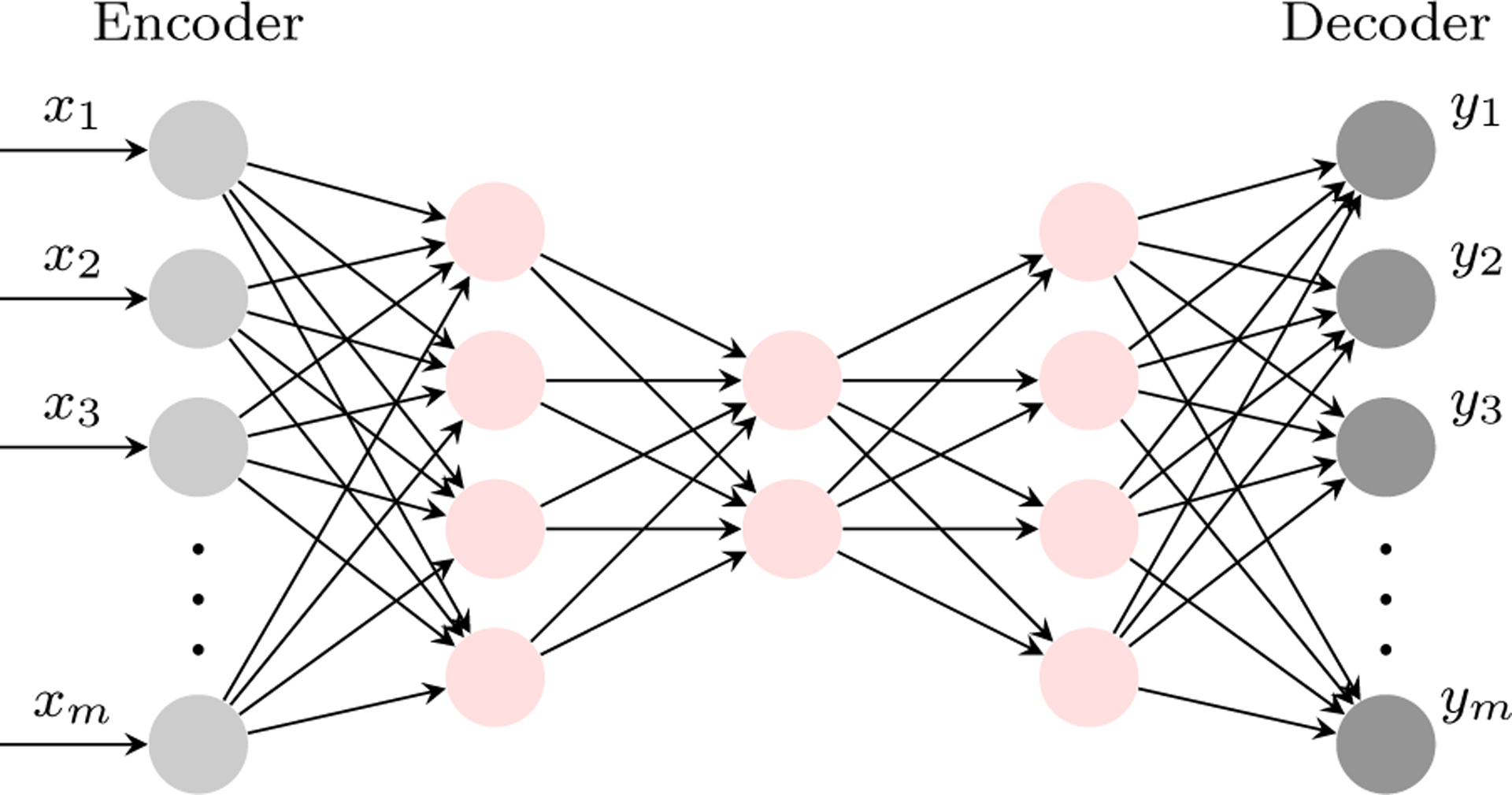
An illustration of an AE. The first part of the network, called the encoder, compresses input into a latent-space by learning the function h = f(x). The second part, called the decoder, reconstructs the input from the latent-space representation by learning the function .