
Figure 3 .
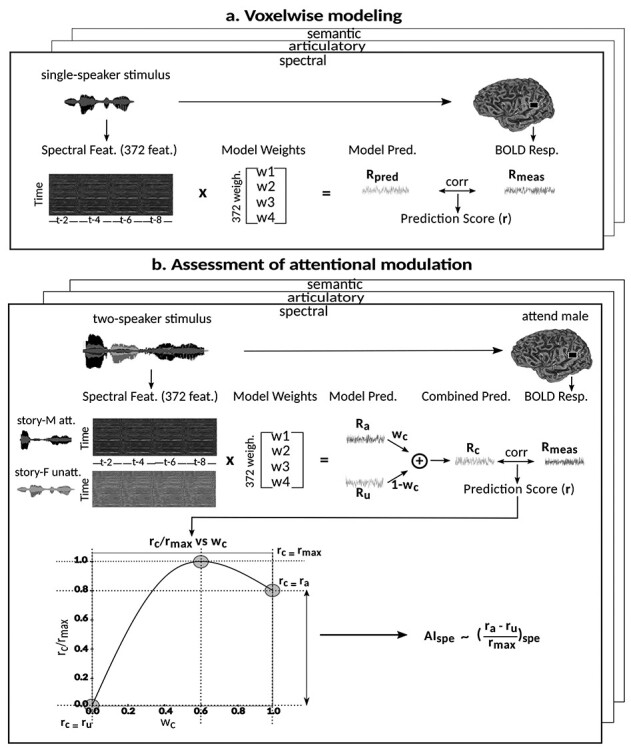
Modeling procedures. (a) “Voxelwise modeling.” Voxelwise models were fit in individual subjects using passive-listening data. To account for hemodynamic response, a linearized 4-tap FIR filter spanning delayed effects at 2–8 s was used. Models were fit via L2-regularized linear regression. BOLD responses were predicted based on fit voxelwise models on held-out passive-listening data. Prediction scores were taken as the Pearson’s correlation between predicted and measured BOLD responses. For a given subject, speech-selective voxels were taken as the union of voxels significantly predicted by spectral, articulatory, or semantic models (q(FDR) < 10−5, t-test). (b) “Assessment of attentional modulation.” Passive-listening models for single voxels were tested on cocktail-party data to quantify attentional modulations in selectivity. In a given run, one of the speakers in a 2-speaker story was attended while the other speaker was ignored. Separate response predictions were obtained using the isolated story stimuli for the attended speaker and for the unattended speaker. Since a voxel can represent information from both attended and unattended stimuli, a linear combination of these predicted responses was considered with varying combination weights (wc in [0 1]). BOLD responses were predicted based on each combination weight separately. Three separate prediction scores were calculated based on only the attended stimulus (wc = 1), based on only the unattended stimulus (wc = 0), and based on the optimal combination of the 2 stimuli. A model-specific attention index, (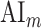 ) was then computed as the ratio of the difference in prediction scores for attended versus unattended stories to the prediction score for their optimal combination (see Materials and Methods).
) was then computed as the ratio of the difference in prediction scores for attended versus unattended stories to the prediction score for their optimal combination (see Materials and Methods).