
Figure 5 .
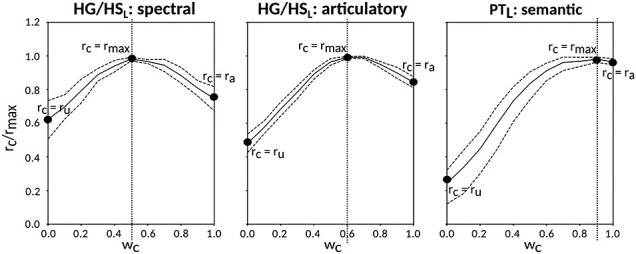
Predicting cocktail-party responses. Passive-listening models were tested during the cocktail-party task by predicting BOLD responses in the cocktail-party data. Since a voxel might represent information from both attended and unattended stimuli, response predictions were expressed as a convex combination of individual predictions for the attended and unattended story within each 2-speaker story. Prediction scores were computed as the combination weights ( ) were varied in [0 1] (see Materials and Methods). Prediction scores for a given model were averaged across speech-selective voxels within each ROI (
) were varied in [0 1] (see Materials and Methods). Prediction scores for a given model were averaged across speech-selective voxels within each ROI ( ). The normalized scores of spectral, articulatory, and semantic models are displayed in several representative ROIs (HG/HS, HG/HS, and PT). Solid and dashed lines indicate mean and 95% confidence intervals across subjects. Scores based on only the attended story (
). The normalized scores of spectral, articulatory, and semantic models are displayed in several representative ROIs (HG/HS, HG/HS, and PT). Solid and dashed lines indicate mean and 95% confidence intervals across subjects. Scores based on only the attended story ( ), based on only the unattended story (
), based on only the unattended story (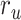 ), and based on the optimal combination of the two (
), and based on the optimal combination of the two (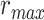 ) are marked with circles. For the “spectral model” in left HG/HS,
) are marked with circles. For the “spectral model” in left HG/HS, 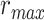 is larger than
is larger than 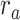 (P < 10−4); and the optimal combination equally weighs attended and unattended stories. For the “articulatory model” in left HG/HS,
(P < 10−4); and the optimal combination equally weighs attended and unattended stories. For the “articulatory model” in left HG/HS, 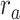 is larger than
is larger than 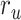 (P < 10−4), whereas
(P < 10−4), whereas 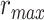 is greater than
is greater than 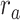 (P < 10−2). Besides, the optimal combination puts slightly higher weight to attended story than unattended story. For the “semantic model” in left PT,
(P < 10−2). Besides, the optimal combination puts slightly higher weight to attended story than unattended story. For the “semantic model” in left PT, 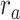 is much higher than
is much higher than 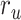 (P < 10−4), and the optimal combination puts much greater weight to attended story than unattended one. These representative results imply that attention may have divergent effects at various levels of speech representations across cortex.
(P < 10−4), and the optimal combination puts much greater weight to attended story than unattended one. These representative results imply that attention may have divergent effects at various levels of speech representations across cortex.