
Figure 1:
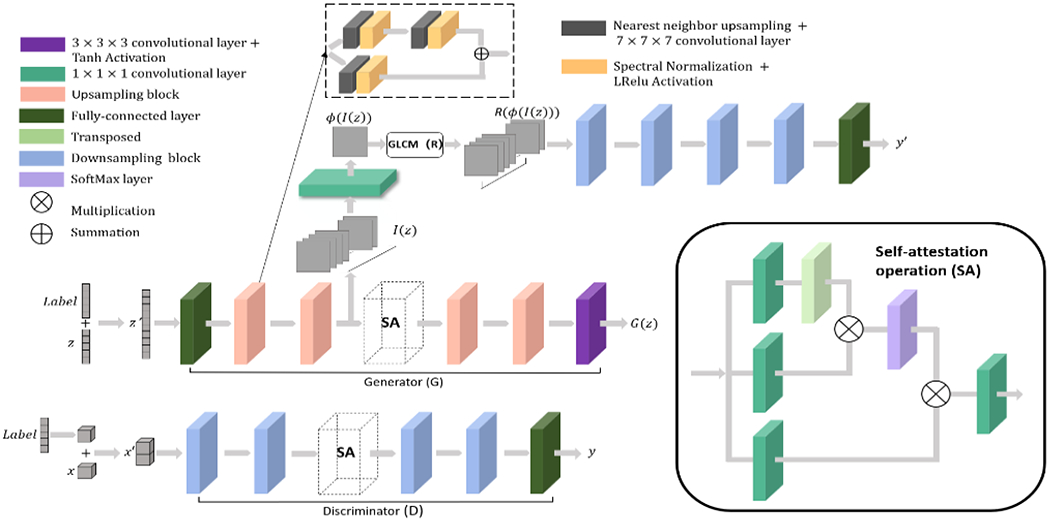
Network structure: The GAN network proposed adopts a Wasserstein discriminator with gradient penalty. Self-attention layers are included in both the generator and discriminator to model long-range dependencies in the image. The radiomics supervision network is included after the first half of the generator to encourage texture similarity between generated and real lesions. Input conditions are encoded in a one-hot label vector and appended to the inputs of both the generator and discriminator. Upsampling and down-sampling ratios are 2. We adopted the RMSprop optimizer with an initial learning rate of 0.0001. The learning rate decays to 0.9 of its value every 20 epochs. Batch size is 8 and a total of 1200 epochs were used in training.