
Figure 1.
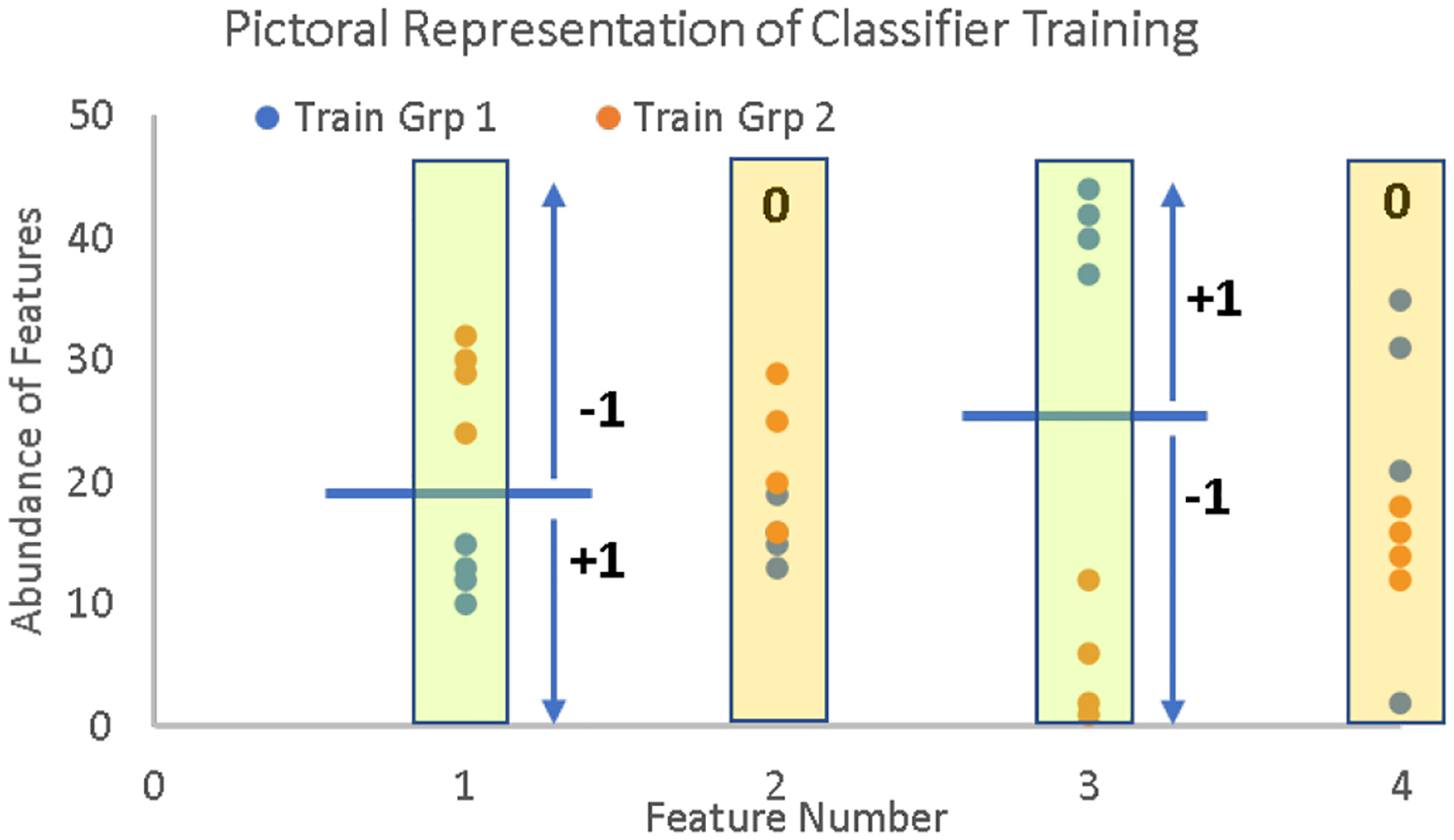
Pictorial description of the feature selection and scoring mechanism in the Aristotle Classifier. Training data from two different classes (blue dots and orange dots) are assessed, one feature at a time. The classifier selects the features in which the training data can be partitioned completely into their respective classes, ex: Features 1 and 3 in the figure are selected. Then a border (depicted by the blue line) is designated for the selected features. Samples that are not part of the training set are scored based on whether their selected features’ abundances are above or below the blue border, as shown in the figure and described more fully in the text. The final class assignment for test samples is based on the total point score for the sample.