
Fig. 4.
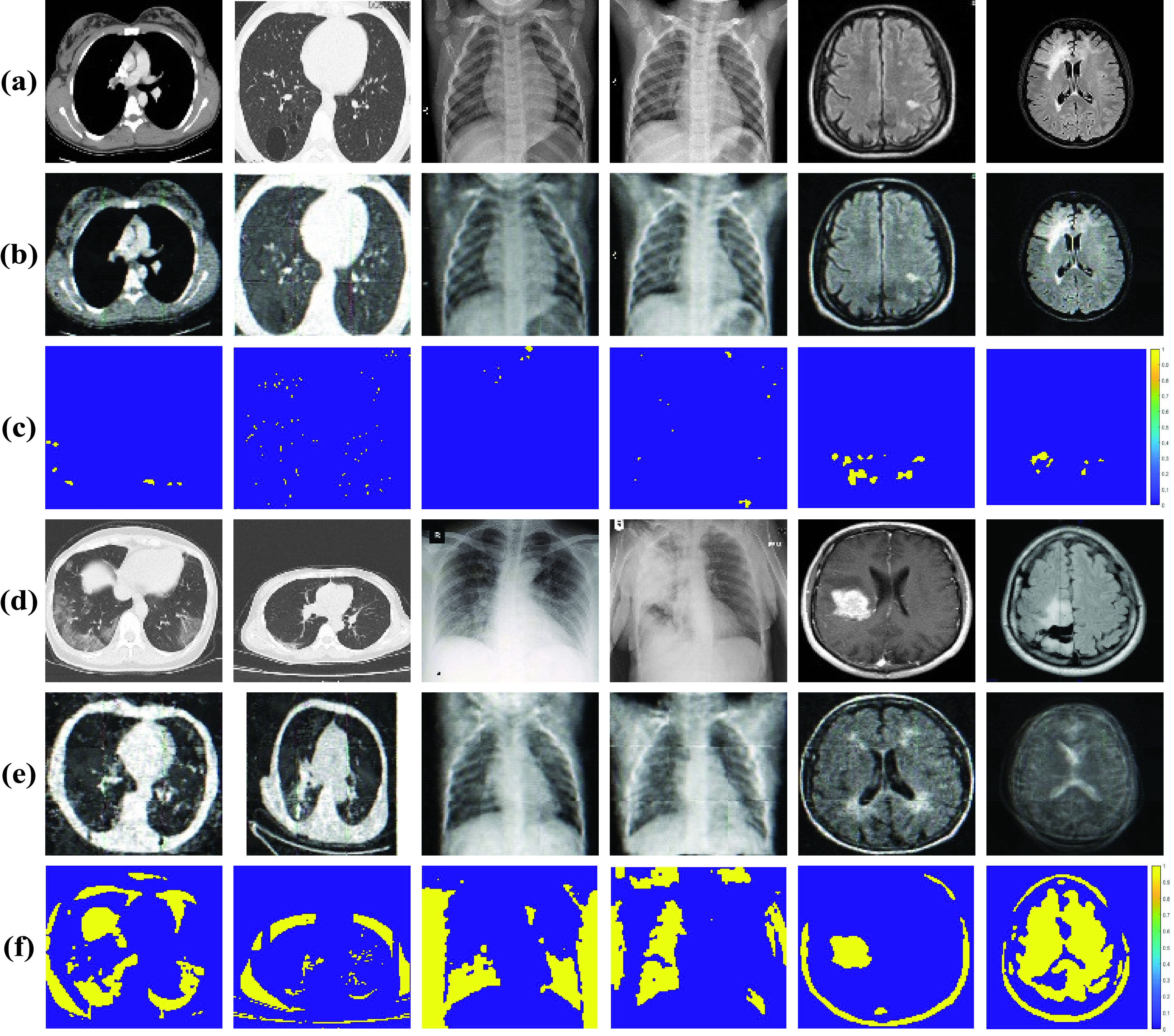
The results of our proposed MAMA Net. Only need training on normal samples, our model can generate high reconstruction error of abnormal samples than normal samples. (a) testing inputs on normal samples; (b) reconstruction on normal samples; (c) reconstruction error of binary mask on normal samples; (d) testing inputs on anomaly; (e) reconstruction on anomaly; (f) reconstruction error of binary mask on anomaly.